







基本拿到任意项目,部署到服务器之后,运行的时候,你要理解里面的代码逻辑,需要掌握调试与抓包,当然更复杂的是逆向解析。这节先梳理下,浏览器自带的调试功能。所有的WEB项目,都必须掌握调试技巧,否则查看问题异常的麻烦。
打开任意需要调试的网站,按下F12(推荐使用谷歌浏览器,标准性最高),很多浏览器标准和谷歌浏览器比较类同。可以看到很多密密麻麻的一片功能区,这里总结下最常用的一些功能,并说明,做逆向的时候,用的会更多一些。
- 网络请求连接部分:
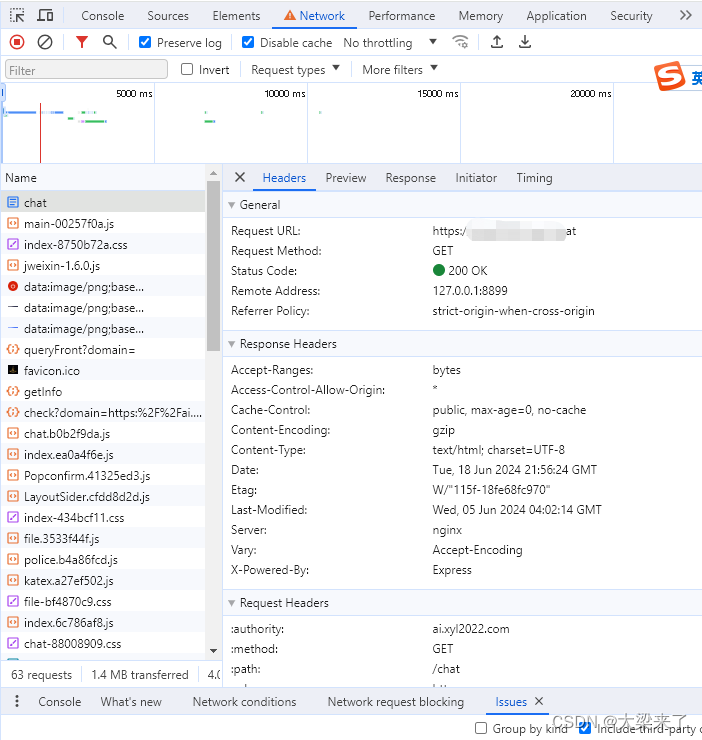
Network网络查看是最常用的功能,一般网站访问失败,功能异常,首先就是F12,检查有没有红色的报错链接。如果有报错链接,我们首先点击到红色的部分,查看headers(请求头)可以看到在headers里面有很多信息:
Headers分三个大部分大体信息,响应头部,请求头部信息:
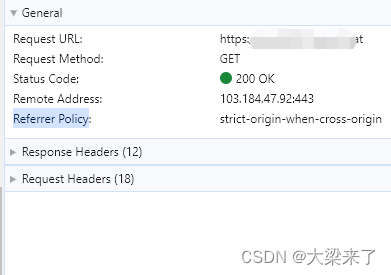
第一部分可以查看到本次远程请求/请求的浏览器方法/请求的状态/远程地址/引用协议(这样可以看到自己某个接口请求的事正式环境接口还是测试环境接口,开发里面由于URL配置异常导致请求了测试环境数据导致在正式环境里面响应失败的情况)。
第二部分响应头信息: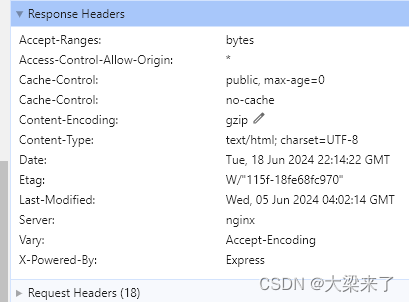
主要查看响应web服务器相关信息,包括响应的框架,这个地方如果是自己开发的,基本不用查看太多,如果是安全攻击者,通常是想知道nginx的版本号还有系统使用的框架,以便利用对应的漏洞。
第三部分是请求头信息。浏览器的指纹信息与这个关系很大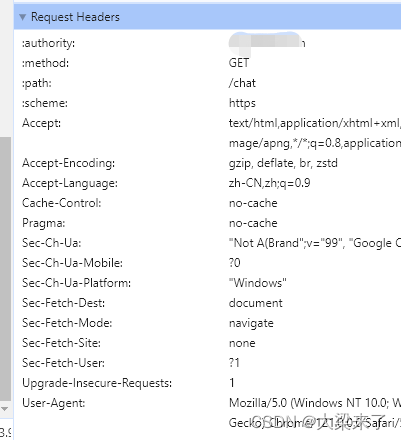 。
。
这里面的信息是我们在模拟我们请求的时候,如果要做到全真模拟,基本要就要把这里的参数全部发送过去,远程服务器才会判断是一个段访问。而要把这些内容复制出来,需要点击左侧内容复制出来(这个很有用,特别是对于初级模拟请求,爬虫,仿真测试)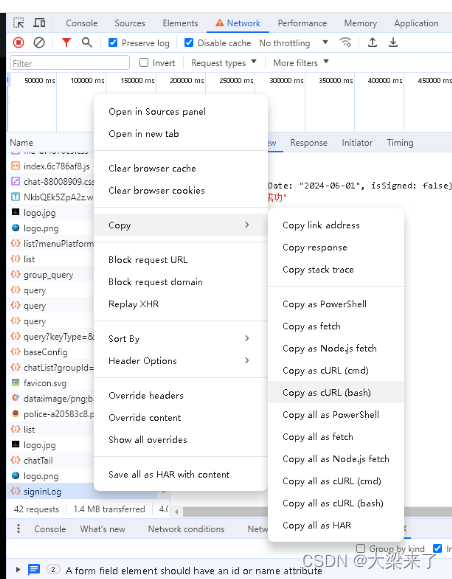
复制出来的请求参数,然后转换成各种其他语言的请求,这样就完成了在我们代码里面对浏览器的一次仿真请求,我一般使用(https://curlconverter.com/)进行转换。
考虑到我们调试页面的时候,会有很多干扰项,或者我们只想调试特定的东西(如果只是修改样式,或者只查看发出去了什么远程请求)筛选出我们需要的筛选到对应的XHR和CSS。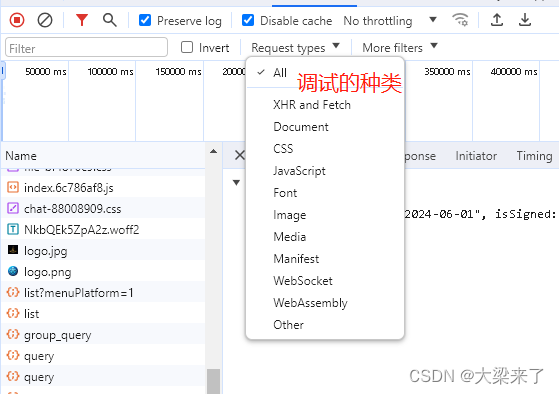 要不然满屏幕的链接,会看的眼花,特别是我们只想知道某个链接发送了什么参数,获得了什么响应。在筛选的上面一层,依次有停止继续抓的按钮(防止有些脚本一直请求连接,导致我们定位的链接一直变动为止,不好定位使用)清除(主要当我们需要重新开始抓使用)preserve log (不勾选的情况下,刷新页面,会将上个页面的记录清理,勾选之后,网页反复刷新也会保留日志)disable cache (是否需要缓存,调试一般不需要缓存,需要实时获取远程服务器的改动,以便知道程序是否正常,正常访问需要缓存,)no throtting (网络的请求模式获取,主要模拟2G/3G/4G网络下的表现,如果有些链接跳转过快,也可以通过降低网速的方式查看中途发生的变化)。
要不然满屏幕的链接,会看的眼花,特别是我们只想知道某个链接发送了什么参数,获得了什么响应。在筛选的上面一层,依次有停止继续抓的按钮(防止有些脚本一直请求连接,导致我们定位的链接一直变动为止,不好定位使用)清除(主要当我们需要重新开始抓使用)preserve log (不勾选的情况下,刷新页面,会将上个页面的记录清理,勾选之后,网页反复刷新也会保留日志)disable cache (是否需要缓存,调试一般不需要缓存,需要实时获取远程服务器的改动,以便知道程序是否正常,正常访问需要缓存,)no throtting (网络的请求模式获取,主要模拟2G/3G/4G网络下的表现,如果有些链接跳转过快,也可以通过降低网速的方式查看中途发生的变化)。
对于常用的开发核心功能,network然后另外一些比如console 调试台,主要查看中途的执行结果,或者在当前页面执行一些特定JS代码片段的反应。基本页面的console.log 打印流程,就可以实时查看我们代码开发中的变量是否异常。
还有一个很关键的Application ,这里面主要储存了我们的location Storage 还有cookie信息。关于俩者的区别,H5里面新出来的概念,主要储存比较大型归属本地自己使用的一个缓存(例如一般的个性化配置,远程服务器端无法获取),而cookie是远程交互比较多(主要是网络使用的数据,一般远程网络也可以获取客户端的cookie信息)。Cookie信息也会在copy对应URL的信息里面,拿到之后,就可以正常模拟登录了的状态获取数据。
















 857
857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











