







考研期间为了第一时间关注各大招生单位的调剂信息,写了一个网页更新检测的小脚本,一旦网页发布了新内容就会发邮件提醒。
1. 基本思路(以edge浏览器为例)
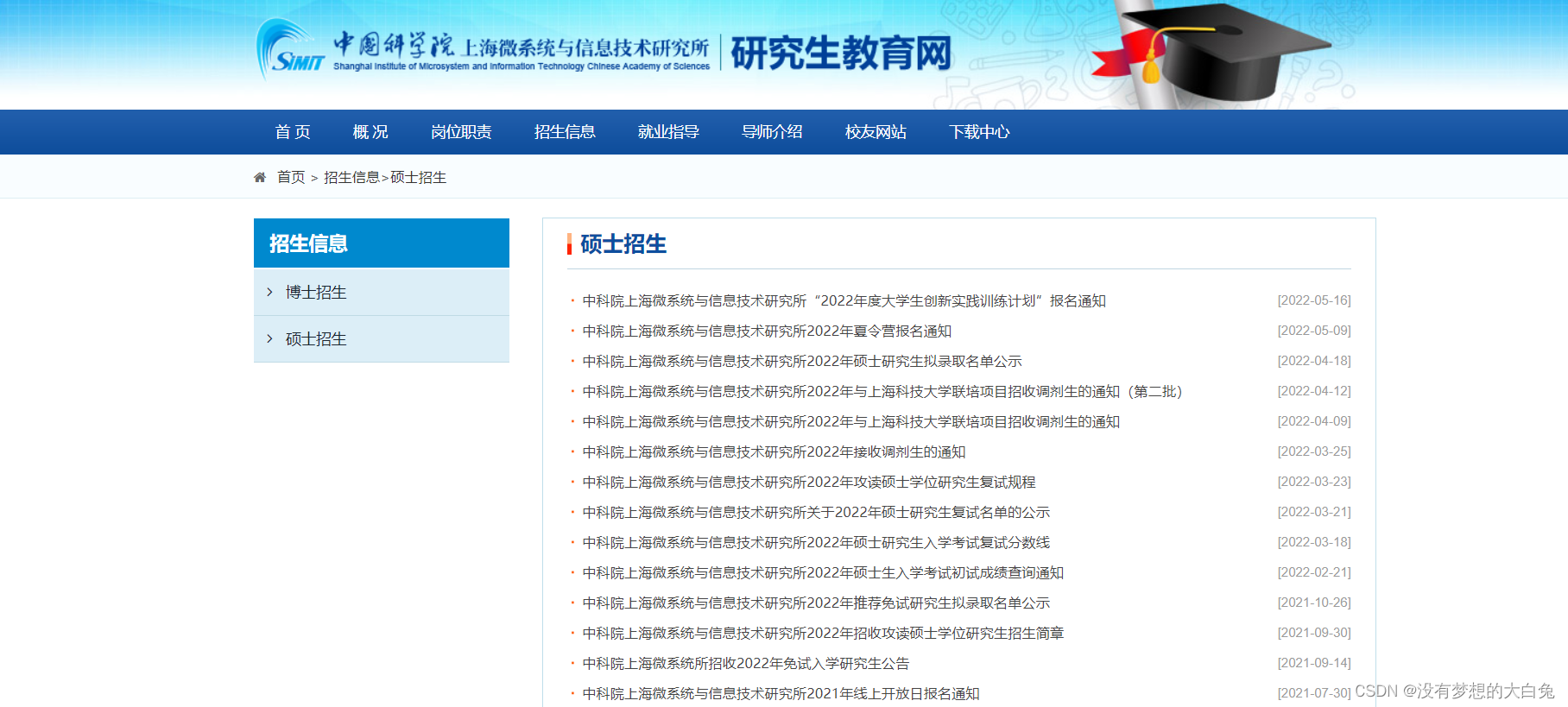
某网站的招生信息如下
按F12进入开发者模式,选择元素,可以逐步定位第一个标题的路径
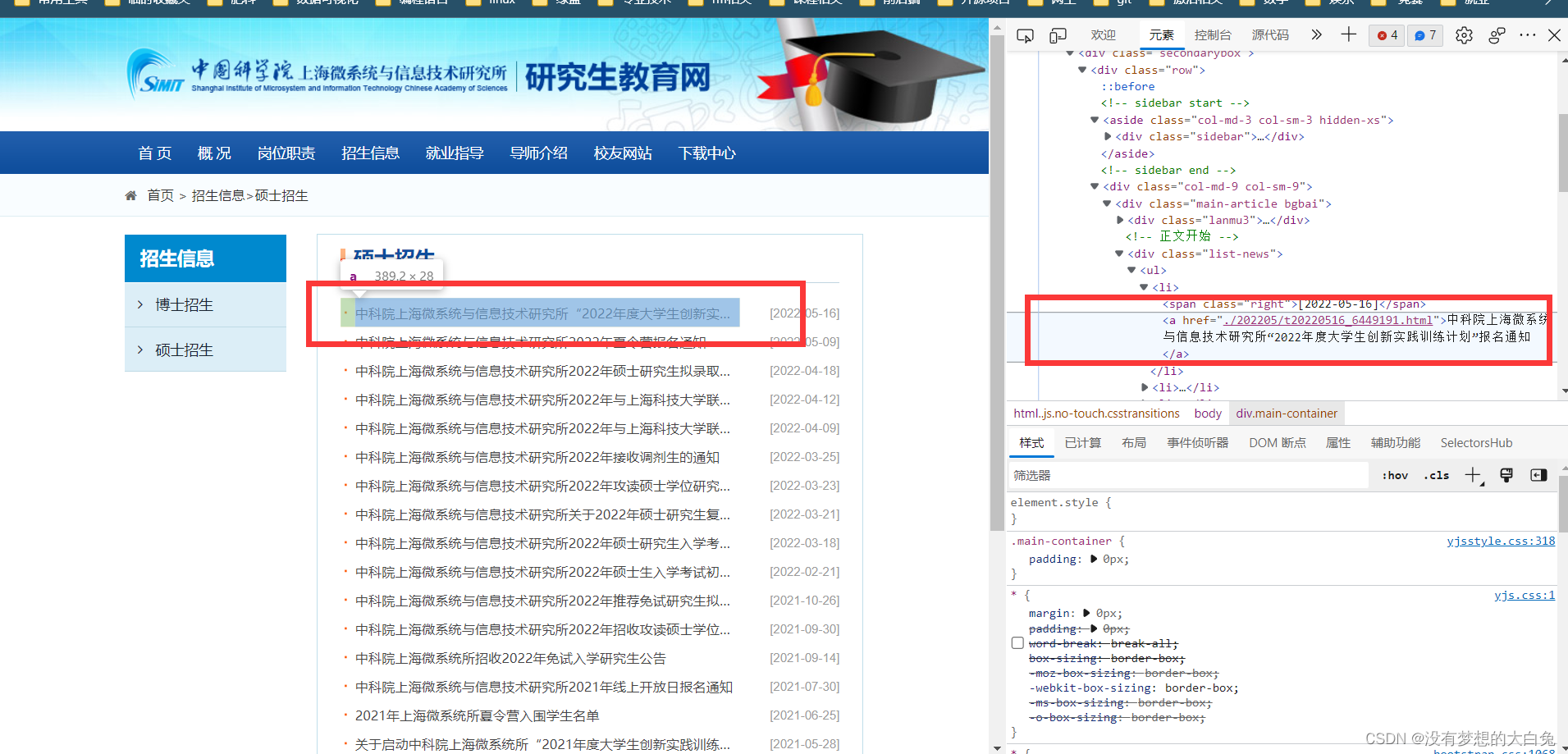
当有消息更新时,第一条标题一般会发生改变。我们通过爬虫不断爬取这条标题,当这条标题发生改变时,发送邮件即可。
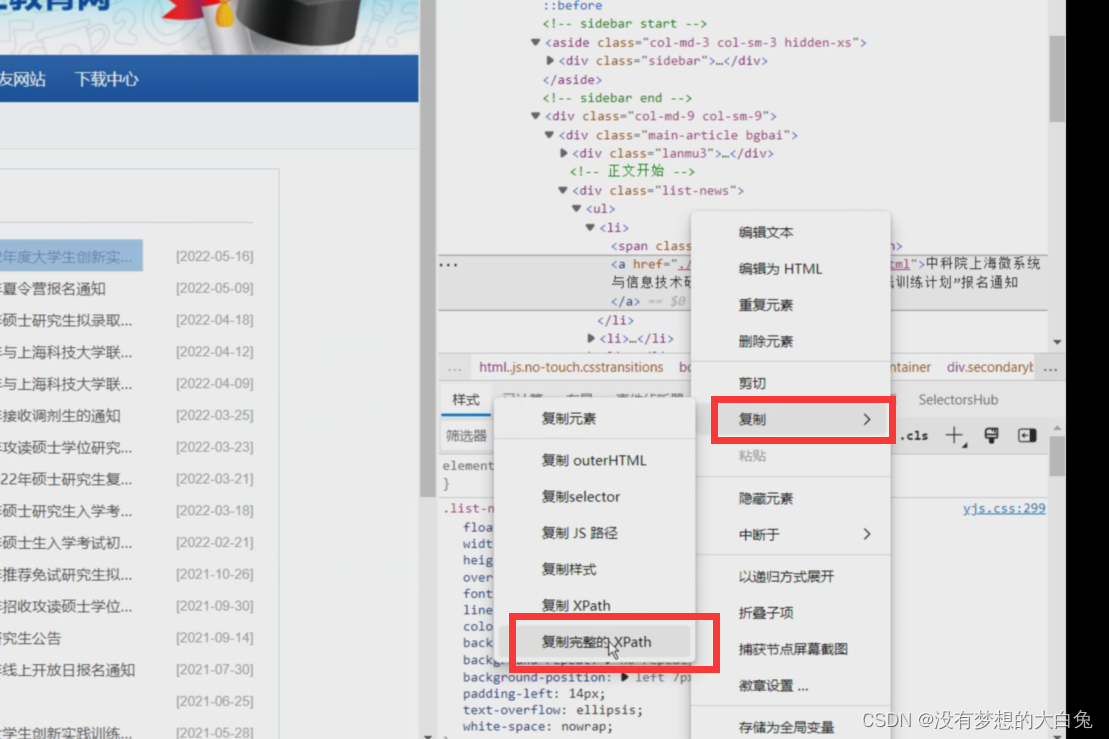
在右侧的工具栏里这条标题上点击右键,复制,复制完整的XPath即可得到这个标题的Xpath,从而可以让爬虫直接从网页中提取出这条标题。
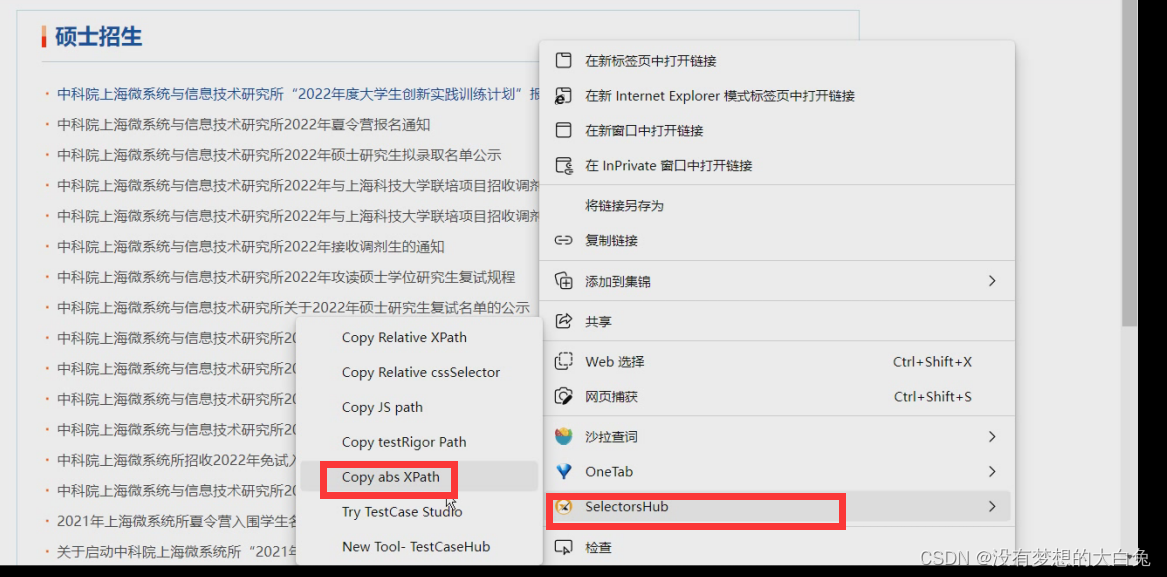
当然也有更为便捷的方案,安装SelectorsHub - Microsoft Edge Addons 扩展后,可以直接在标题右键复制xpath
2. 代码实现
2.1 主要依赖库
from lxml import etree
import csv
import requests
from email.mime.text import MIMEText
import smtplib
import time
import random
from fake_useragent import UserAgent
import traceback
2.2 邮件发送功能实现
sender = 'xxxx@mail.ustc.edu.cn' # 消息发送的邮箱
smtpserver = 'mail.ustc.edu.cn' # 消息发送邮箱的服务器
username = 'xxxx@mail.ustc.edu.cn' # 消息发送的邮箱用户名,一般通消息发送的邮箱
password = 'xxxxxxx' # 消息发送邮箱的密码
receivers = [ # 接收消息的邮箱
'xxxxx@qq.com',
'xxxxx@qq.com'
]
def send_email(title, receiver, message):
msg = MIMEText(message, 'html', 'utf-8')
msg['Subject'] = title
msg['from'] = sender
msg['to'] = receiver
smtp = smtplib.SMTP_SSL(smtpserver, 465) # 加密方式
smtp.esmtp_features["auth"] = "PLAIN"
(code, resp) = smtp.login(username, password)
if code == 0:
print("fail")
else:
print("success")
result = smtp.sendmail(sender, receiver, msg.as_string())
# print(result)
smtp.quit()
pass
2.3 爬取网页和将网页转化为xpath
def request(url):
ua = UserAgent()
headers = {"User-Agent": ua.random}
response = requests.get(url, headers=headers, timeout=5) # 设置超时防止卡死
return response
def use_xpath(response, xpath_txt):
html = etree.HTML(response.content.decode(response.apparent_encoding)) # 这里需要解码一下
return html.xpath(xpath_txt)
2.4 主函数
if __name__ == '__main__':
titles = {}
while True:
with open("schools.csv", "r", encoding='utf-8') as csvFile: # 这里将需要爬取的学校信息整理成了一个csv文件
csv_reader = csv.reader(csvFile)
for s in csv_reader:
if len(s) != 3: # csv文件格式为 校名,链接,xpath
continue
try:
response = request(s[1])
if int(response.status_code / 100) != 2:
continue
if not s[2]: # xpath错误,或者从xpath提取不到信息可以将xpath字段留空,这样会以网页长度为检测标准
title = str(len(response.text))
else: # 这里由于不同网页保存标题的位置不同,因此做了判断,尝试从不同位置读取标题
useful_msg = use_xpath(response, s[2])
try:
title = useful_msg[0].text.strip()
except:
try:
title = useful_msg[0].attrib['title'].strip()
except:
title = useful_msg[0].strip()
# print(title)
if s[0] not in titles:
titles[s[0]] = title
continue
if titles[s[0]] != title:
titles[s[0]] = title
# print(F'{s[0]}新消息: {title}')
for recver in receivers:
send_email(F"{s[0]}有了新消息", recver, title + ' ' + s[1])
except BaseException as e:
# print(F"读取{s[0]}消息出现异常:{e}")
pass
# print(traceback.format_exc())
time.sleep(sleep_time + random.randint(0, 10)) # 控制爬取频率
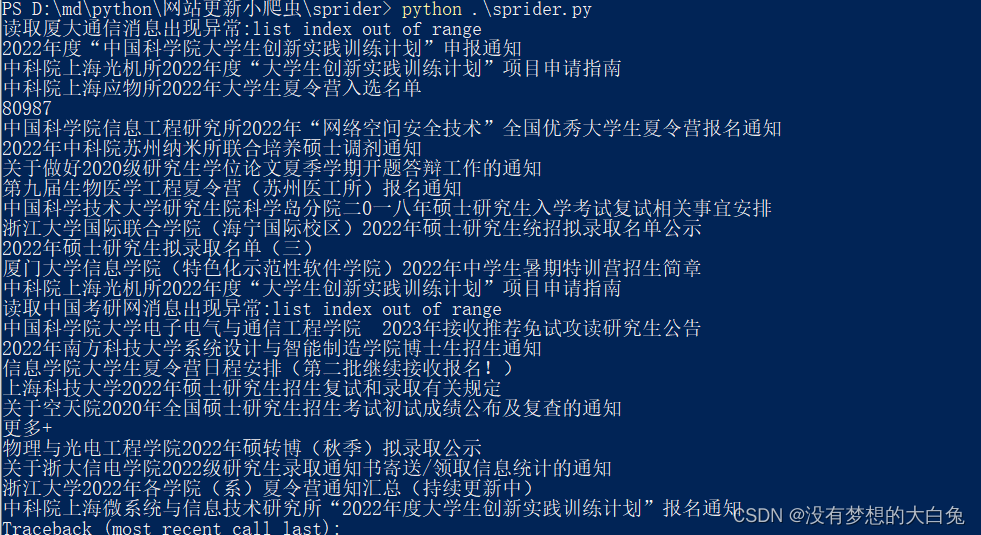
2.5 效果
















 1786
1786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









