







 本文详细解析了TensorFlow Lite模型加载与执行的内部机制,包括模型文件的加载、解析,以及如何将模型文件映射为可执行的操作。同时介绍了GPU delegate的使用,以实现基于OpenGL和Metal的GPU加速。
本文详细解析了TensorFlow Lite模型加载与执行的内部机制,包括模型文件的加载、解析,以及如何将模型文件映射为可执行的操作。同时介绍了GPU delegate的使用,以实现基于OpenGL和Metal的GPU加速。
Tensorflow Lite 代码解析 – 模型加载与执行
1. 整体流程
其Java API的核心类是Interpreter.java,其具体实现是在NativeInterpreterWrappter.java,而最终是调用到Native的nativeinterpreterwraptter_jni.h,自此就进入C++实现的逻辑。

2. 模型文件的加载和解析
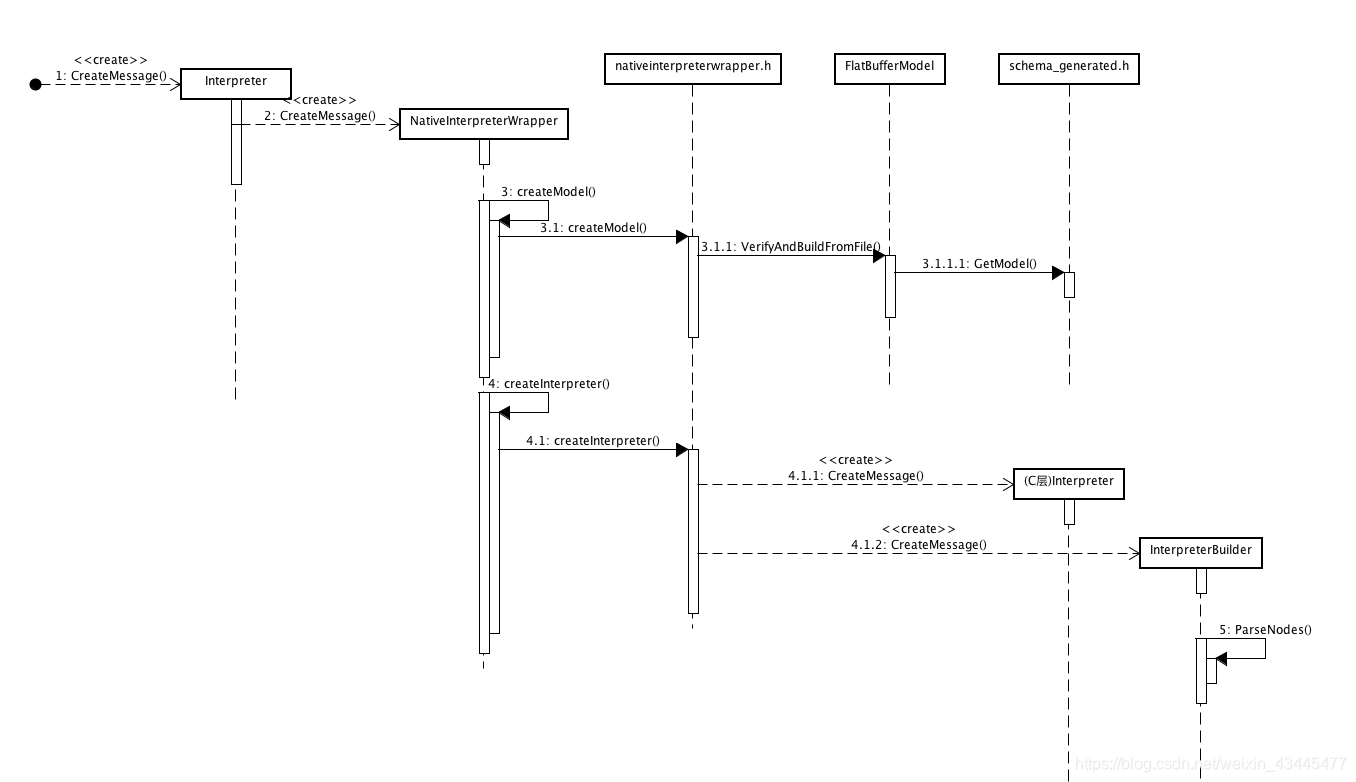
(1)加载模型文件
//nativeinterpreter_jni.cc的createModel()函数是加载和解析文件的入口
JNIEXPORT jlong JNICALL
Java_org_tensorflow_lite_NativeInterpreterWrapper_createModel(
JNIEnv* env, jclass clazz, jstring model_file, jlong error_handle) {
BufferErrorReporter* error_reporter =
convertLongToErrorReporter(env, error_handle);
if (error_reporter == nullptr) return 0;
const char* path = env->GetStringUTFChars(model_file, nullptr);
std::unique_ptr<tflite::TfLiteVerifier> verifier;
verifier.reset(new JNIFlatBufferVerifier());
//读取并解析文件关键代码
auto model = tflite::FlatBufferModel::VerifyAndBuildFromFile(
path, verifier.get(), error_reporter);
if (!model) {
throwException(env, kIllegalArgumentException,
"Contents of %s does not encode a valid "
"TensorFlowLite model: %s",
path, error_reporter->CachedErrorMessage());
env->ReleaseStringUTFChars(model_file, path);
return 0;
}
env->ReleaseStringUTFChars(model_file, path);
return reinterpret_cast<jlong>(model.release());
}
上述逻辑中,最关键之处在于
auto model = tflite::FlatBufferModel::VerifyAndBuildFromFile(path, verifier.get(), error_reporter);
这行代码的作用是读取并解析文件
//代码在model.cc文件中
std::unique_ptr<FlatBufferModel> FlatBufferModel::VerifyAndBuildFromFile(
const char* filename, TfLiteVerifier* verifier,
ErrorReporter* error_reporter) {
error_reporter = ValidateErrorReporter(error_reporter);
std::unique_ptr<FlatBufferModel> model;
//读取文件
auto allocation = GetAllocationFromFile(filename, /*mmap_file=*/true,
error_reporter, /*use_nnapi=*/true);
if (verifier &&
!verifier->Verify(static_cast<const char*>(allocation->base()),
allocation->bytes(), error_reporter)) {
return model;
}
//用FlatBuffers库解析文件
model.reset(new FlatBufferModel(allocation.release(), error_reporter));
if (!model->initialized()) model.reset();
return model;
}
(2)解析模型文件
上面的流程将模型文件读到FlatBuffers的Model数据结构中,具体数据结构定义可以见schema.fbs。接下去,需要文件中的数据映射成对应可以执行的op数据结构。这个工作主要由InterpreterBuilder完成。
/nativeinterpreter_jni.cc的createInterpreter()函数是将模型文件映射成可以执行的op的入口函数。
JNIEXPORT jlong JNICALL
Java_org_tensorflow_lite_NativeInterpreterWrapper_createInterpreter(
JNIEnv* env, jclass clazz, jlong model_handle, jlong error_handle,
jint num_threads) {
tflite::FlatBufferModel* model = convertLongToModel(env, model_handle);
if (model == nullptr) return 0;
BufferErrorReporter* error_reporter =
convertLongToErrorReporter(env, error_handle);
if (error_reporter == nullptr) return 0;
//先注册op,将op的实现和FlatBuffers中的index关联起来。
auto resolver = ::tflite::CreateOpResolver();
std::unique_ptr<tflite::Interpreter> interpreter;
//解析FlatBuffers,将配置文件中的内容映射成可以执行的op实例。
TfLiteStatus status = tflite::InterpreterBuilder(*model, *(resolver.get()))(
&interpreter, static_cast<int>(num_threads));
if (status != kTfLiteOk) {
throwException(env, kIllegalArgumentException,
"Internal error: Cannot create interpreter: %s",
error_reporter->CachedErrorMessage());
return 0;
}
// allocates memory
status = interpreter->AllocateTensors();
if (status != kTfLiteOk) {
throwException(
env, kIllegalStateException,
"Internal error: Unexpected failure when preparing tensor allocations:"
" %s",
error_reporter->CachedErrorMessage());
return 0;
}
return reinterpret_cast<jlong>(interpreter.release());
}
这里首先调用::tflite::CreateOpResolver()完成op的注册,将op实例和FlatBuffers中的索引对应起来,具体索引见schema_generated.h里面的BuiltinOperator枚举。
//builtin_ops_jni.cc
std::unique_ptr<OpResolver> CreateOpResolver() { // NOLINT
return std::unique_ptr<tflite::ops::builtin::BuiltinOpResolver>(
new tflite::ops::builtin::BuiltinOpResolver());
}
//register.cc
BuiltinOpResolver::BuiltinOpResolver() {
AddBuiltin(BuiltinOperator_RELU, Register_RELU());
AddBuiltin(BuiltinOperator_RELU_N1_TO_1, Register_RELU_N1_TO_1());
AddBuiltin(BuiltinOperator_RELU6, Register_RELU6());
AddBuiltin(BuiltinOperator_TANH, Register_TANH());
AddBuiltin(BuiltinOperator_LOGISTIC, Register_LOGISTIC());
AddBuiltin(BuiltinOperator_AVERAGE_POOL_2D, Register_AVERAGE_POOL_2D());
AddBuiltin(BuiltinOperator_MAX_POOL_2D, Register_MAX_POOL_2D());
AddBuiltin(BuiltinOperator_L2_POOL_2D, Register_L2_POOL_2D());
AddBuiltin(BuiltinOperator_CONV_2D, Register_CONV_2D());
AddBuiltin(BuiltinOperator_DEPTHWISE_CONV_2D, Register_DEPTHWISE_CONV_2D()
...
}
InterpreterBuilder则负责根据FlatBuffers内容,构建Interpreter对象。
TfLiteStatus InterpreterBuilder::operator()(
std::unique_ptr<Interpreter>* interpreter, int num_threads) {
.....
// Flatbuffer model schemas define a list of opcodes independent of the graph.
// We first map those to registrations. This reduces string lookups for custom
// ops since we only do it once per custom op rather than once per custom op
// invocation in the model graph.
// Construct interpreter with correct number of tensors and operators.
auto* subgraphs = model_->subgraphs();
auto* buffers = model_->buffers();
if (subgraphs->size() != 1) {
error_reporter_->Report("Only 1 subgraph is currently supported.\n");
return cleanup_and_error();
}
const tflite::SubGraph* subgraph = (*subgraphs)[0];
auto operators = subgraph->operators();
auto tensors = subgraph->tensors();
if (!operators || !tensors || !buffers) {
error_reporter_->Report(
"Did not get operators, tensors, or buffers in input flat buffer.\n");
return cleanup_and_error();
}
interpreter->reset(new Interpreter(error_reporter_));
if ((**interpreter).AddTensors(tensors->Length()) != kTfLiteOk) {
return cleanup_and_error();
}
// Set num threads
(**interpreter).SetNumThreads(num_threads);
// Parse inputs/outputs
(**interpreter).SetInputs(FlatBufferIntArrayToVector(subgraph->inputs()));
(**interpreter).SetOutputs(FlatBufferIntArrayToVector(subgraph->outputs()));
// Finally setup nodes and tensors
if (ParseNodes(operators, interpreter->get()) != kTfLiteOk)
return cleanup_and_error();
if (ParseTensors(buffers, tensors, interpreter->get()) != kTfLiteOk)
return cleanup_and_error();
std::vector<int> variables;
for (int i = 0; i < (*interpreter)->tensors_size(); ++i) {
auto* tensor = (*interpreter)->tensor(i);
if (tensor->is_variable) {
variables.push_back(i);
}
}
(**interpreter).SetVariables(std::move(variables));
return kTfLiteOk;
}
(3)模型执行

经过InterpreterBuilder的工作,模型文件的内容已经解析成可执行的op,存储在interpreter.cc的nodes_and_registration_列表中。剩下的工作就是循环遍历调用每个op的invoke接口。
//interpreter.cc
TfLiteStatus Interpreter::Invoke() {
.....
// Invocations are always done in node order.
// Note that calling Invoke repeatedly will cause the original memory plan to
// be reused, unless either ResizeInputTensor() or AllocateTensors() has been
// called.
// TODO(b/71913981): we should force recalculation in the presence of dynamic
// tensors, because they may have new value which in turn may affect shapes
// and allocations.
for (int execution_plan_index = 0;
execution_plan_index < execution_plan_.size(); execution_plan_index++) {
if (execution_plan_index == next_execution_plan_index_to_prepare_) {
TF_LITE_ENSURE_STATUS(PrepareOpsAndTensors());
TF_LITE_ENSURE(&context_, next_execution_plan_index_to_prepare_ >=
execution_plan_index);
}
int node_index = execution_plan_[execution_plan_index];
TfLiteNode& node = nodes_and_registration_[node_index].first;
const TfLiteRegistration& registration =
nodes_and_registration_[node_index].second;
SCOPED_OPERATOR_PROFILE(profiler_, node_index);
// TODO(ycling): This is an extra loop through inputs to check if the data
// need to be copied from Delegate buffer to raw memory, which is often not
// needed. We may want to cache this in prepare to know if this needs to be
// done for a node or not.
for (int i = 0; i < node.inputs->size; ++i) {
int tensor_index = node.inputs->data[i];
if (tensor_index == kOptionalTensor) {
continue;
}
TfLiteTensor* tensor = &tensors_[tensor_index];
if (tensor->delegate && tensor->delegate != node.delegate &&
tensor->data_is_stale) {
EnsureTensorDataIsReadable(tensor_index);
}
}
EnsureTensorsVectorCapacity();
tensor_resized_since_op_invoke_ = false;
//逐个op调用
if (OpInvoke(registration, &node) == kTfLiteError) {
status = ReportOpError(&context_, node, registration, node_index,
"failed to invoke");
}
// Force execution prep for downstream ops if the latest op triggered the
// resize of a dynamic tensor.
if (tensor_resized_since_op_invoke_ &&
HasDynamicTensor(context_, node.outputs)) {
next_execution_plan_index_to_prepare_ = execution_plan_index + 1;
}
}
if (!allow_buffer_handle_output_) {
for (int tensor_index : outputs_) {
EnsureTensorDataIsReadable(tensor_index);
}
}
return status;
}
2. GPU delegate
-
Tensorflow Lite的GPU加速是基于Open GL(Android)和Metal(Apple)
-
GpuDelegate.java做了接口封装,这部分的源码参考lite/delegates/gpu
-
在执行GPU运算时,数据经常会涉及到从CPU转到GPU的情况,往往这种数据的拷贝与转移会耗费大量的时间,TensorFlow Lite提供了一个解决方案,可以直接读取或直接写入数据到GPU中的硬件缓冲区并绕过可避免的memory copies:
Assuming the camera input is in the GPU memory as GL_TEXTURE_2D, it must be first converted to a shader storage buffer object (SSBO) for OpenGL or to a MTLBuffer object for Metal. One can associate a TfLiteTensor with a user-prepared SSBO or MTLBuffer with TfLiteGpuDelegateBindBufferToTensor() or TfLiteMetalDelegateBindBufferToTensor(), respectively.
// Prepare GPU delegate.
auto* delegate = TfLiteGpuDelegateCreate(nullptr);
interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy
#if defined(__ANDROID__)
if (TfLiteGpuDelegateBindBufferToTensor(delegate, user_provided_input_buffer, interpreter->inputs()[0]) != kTfLiteOk) return;
if (TfLiteGpuDelegateBindBufferToTensor(delegate, user_provided_output_buffer, interpreter->outputs()[0]) != kTfLiteOk) return;
#elif defined(__APPLE__)
if (TfLiteMetalDelegateBindBufferToTensor(delegate, user_provided_input_buffer, interpreter->inputs()[0]) != kTfLiteOk) return;
if (TfLiteMetalDelegateBindBufferToTensor(delegate, user_provided_output_buffer, interpreter->outputs()[0]) != kTfLiteOk) return;
#endif
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return;
// Run inference.
if (interpreter->Invoke() != kTfLiteOk) return;
需要注意的是,上述方法需要在Interpreter::ModifyGraphWithDelegate()之前调用。

















 3018
3018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









