







背景
由于tflite模型设计时考虑到了内存占用等问题,其forward的过程会反复利用中间内存空间,而导致中间层的output数据没有保存下来,模型debug难点较大。(备注:内存复用算法任务是计算整个内存区大小、中间变量重叠内存块的offset。虽然前序计算完后会被后续结果覆盖,但在实际使用中无感的。)
经过查阅相关材料,发现一个最简洁的方式,记录于此。
思路:解析flatbuffer格式的tflite模型, 直接修改tflite模型内容,调整模型output到指定层。
实现
1. 修改tflite模型output的函数。
import flatbuffers
from tensorflow.lite.python import schema_py_generated as schema_fb
def OutputsOffset(subgraph, j):
o = flatbuffers.number_types.UOffsetTFlags.py_type(subgraph._tab.Offset(8))
if o != 0:
a = subgraph._tab.Vector(o)
return a + flatbuffers.number_types.UOffsetTFlags.py_type(j * 4)
return 0
#参考了https://github.com/raymond-li/tflite_tensor_outputter/blob/master/tflite_tensor_outputter.py
#调整output到指定idx
def buffer_change_output_tensor_to(model_buffer, new_tensor_i):
root = schema_fb.Model.GetRootAsModel(model_buffer, 0)
output_tensor_index_offset = OutputsOffset(root.Subgraphs(0), 0)
# Flatbuffer scalars are stored in little-endian.
new_tensor_i_bytes = bytes([
new_tensor_i & 0x000000FF, \
(new_tensor_i & 0x0000FF00) >> 8, \
(new_tensor_i & 0x00FF0000) >> 16, \
(new_tensor_i & 0xFF000000) >> 24 \
])
# Replace the 4 bytes corresponding to the first output tensor index
return model_buffer[:output_tensor_index_offset] + new_tensor_i_bytes + model_buffer[output_tensor_index_offset + 4:]
2.调用方式
# Read the model.
with open('xxx.tflite', 'rb') as f:
model_buffer = f.read()
# 修改输出idx
idx = 35 #可以通过interpreter.get_tensor_details(),查各层的idx值; 或者netron也可以看到
model_buffer = buffer_change_output_tensor_to(model_buffer, idx)
# 推理
interpreter = tf.lite.Interpreter(model_content=model_buffer)
interpreter.allocate_tensors()
input_index = interpreter.get_input_details()[0]["index"]
output_index = interpreter.get_output_details()[0]["index"]
interpreter.set_tensor(input_index, input_data)
interpreter.invoke()
# 中间层的output值
out_val = interpreter.get_tensor(output_index)
# Save the model. 可以用netron打开确认ouput节点,看修改后的模型是否符合预期
with open('xxx_new.tflite', 'wb') as f:
f.write(model_buffer)
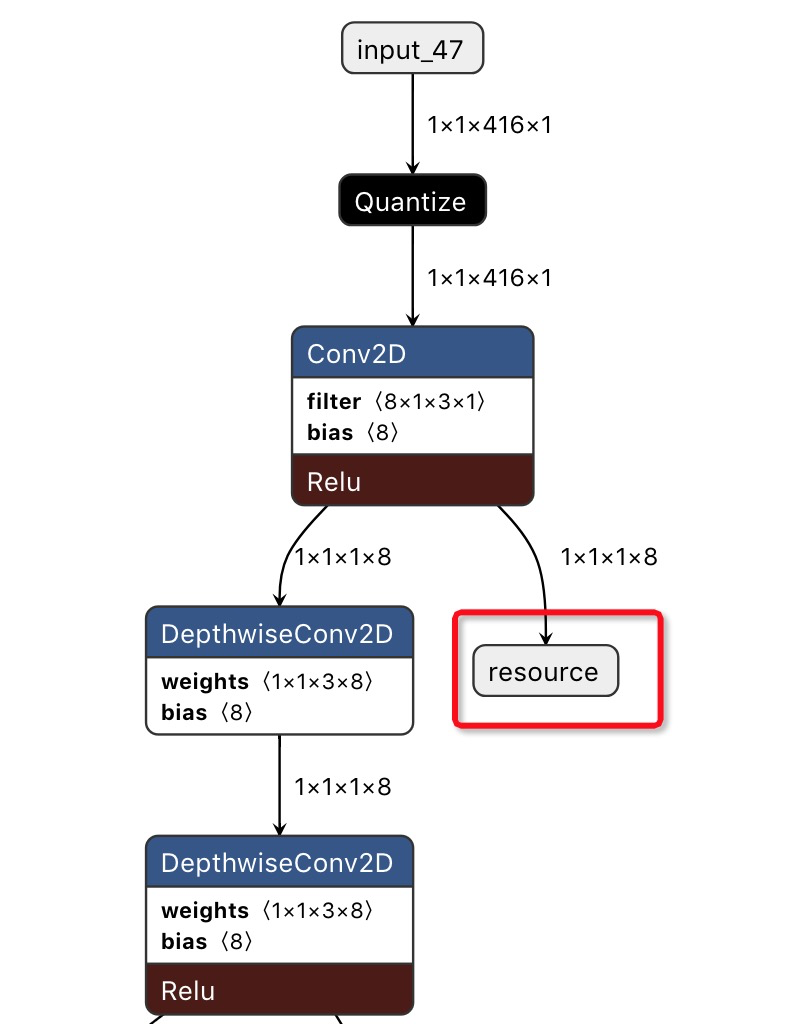
3. 修改后的tflite模型 (netron读取) ,红框位置即是中间层的输出结果















 581
581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









