







数据来源于网络;
使用工具:python,navicat, MySQL,excel
分析分为3块:
1.数据预处理:异常值,重复值,缺失值,(线性回归填充)
2.数据分析:描述型统计分析(MySQL),渠道&平台分析产品TOP分析
3.RFM(k-means),同期群分析(新用户留存,客单价),流失周期
数据概貌:
一张excel表,来源某电商平台,购买订单明细表,以下是字段:

1.在做分析前先对数据进行预处理:
逐一字段,争对,异常值,缺失值,重复值进行分析
这里提一下,chanelID,和payment存在缺失。
对于缺失值的处理方法有:删除和填充
填充又分为:平均数填充,中位数填充,众数填充,和回归预测填充。
对于ChanelID 因为缺失值较少,直接删除。
Payment缺失1038行,又因为是金额重要指标,采用回归填充
这里采用线性回归预测填充
def data_tackle_restart(self,data):
# print(data.info())
# print(data.info())
# print(data.head())
#主要争对重复值,异常值,缺失值进行处理
# data.set_index('id',inplace=True)
data.drop(index=data[data.index=='NaN'].index,inplace=True)
data.drop_duplicates(subset='orderID',inplace=True)
data['userID']=data['userID'].str[5:]
data.drop(index=data[data.payment>data.orderAmount].index,inplace=True)
data.drop(index=data[data.payment<0].index,inplace=True)
data.drop(index=data[data.orderAmount<0].index,inplace=True)
data['orderAmount']=data['orderAmount']/10
data['payment']=data['payment']/10
data.drop(index=data[data.chanelID=='###'].index,inplace=True)
# data['goodsID']=data['goodsID'].str[2:]
data['platformType']=data['platformType'].str.replace(" ","")
d={'WechatShop':'1',
'WEB':'2',
'ALiMP':'3',
'WechatMP':'4',
'Wap':'5',
'APP':'6'}
data=data.replace({'platformType':d})
d={'否':'1','是':'0'}
data=data.replace({'chargeback':d})
df=data.copy()
#对于缺失值在数据量比较小的时候可以进行删除,比较大或者比较关键的时候进行填充
#这里采用线性回归
#金额
data['platformType']=data['platformType'].astype(int)
data['chargeback']=data['chargeback'].astype(int)
# print(data.info())
# print(data.corr())
x_train=np.array(df[df.payment.isnull()==False]['orderAmount']).reshape(-1,1)
x_text=np.array(df[df.payment.isnull()==True]['orderAmount']).reshape(-1,1)
y_train=np.array(df[df.payment.isnull()==False]['payment']).reshape(-1,1)
l=LinearRegression()
l.fit(x_train,y_train)
rr=l.predict(x_text)
# print(rr)
data.loc[data['payment'].isnull()==True,'payment']=rr
# print(cross_val_score(l,np.array(data.orderAmount).reshape(-1,1),np.array(data.payment).reshape(-1,1),cv=5).mean())
data['orderTime']=pd.to_datetime(data.orderTime)
data['payTime']=pd.to_datetime(data.payTime)
data.drop(index=data[data.orderTime > data['payTime']].index,inplace=True)
data.drop(index=data[(data.payTime-data.orderTime).dt.days>1].index,inplace=True)
data['month']=data.payTime.dt.month
data['星期']=data.payTime.dt.day_name()
data['date']=data.payTime.dt.date
data['hour']=data['payTime'].dt.hour
data['order']=1
return data
以上最后一段是关于时间粒度的构建,从年,月,星期,小时,进行拆分。
2.描述性统计分析:
1.描述性统计分析基于mySQL,使用navicat连接操作MYSQL.
1.1先来看一下整体的一个汇总情况:总订单数,GMV,独立用户数,客单价

1.2 联合时间维度;月,星期,小时,集中在销售额和独立用户上,对数据进行描述。
月:


分析:从5月开始整体的GMV呈现上涨趋势,其他指标也对应上涨,且5月的增长率也是最高,虽然之后增长率走低,但是绝对值GMV基本稳定在100万以上
按照星期:

整个GMV基本上符合电商平台的特性,在周末逐渐上涨,周内有所下降,在周三相比最低。
整体GMV都处于150万以上
按照小时:


整体符合电商平台的规律,晚上是黄金时间[17-22]点 一路走高,在21点达到最高,除了在晚上这个时间段发送push多次弹出,以及优惠卷的发放(为了刺激用户消费)以外,还应将一部分优惠卷,积分的发放时间争对不同人群精准在13-14点投放。
按照渠道分解:

分析:就GMV来说,可以明显看到断层,no.1 0896渠道比第二名高出了40万,之后的断层也是在0530 渠道,与0765,0007与0283 ;20万-30万之间,说明整体渠道这方面不是很稳定,超头部渠道达到了170万,而之后的都相差至少40万以上,这还仅仅是购买金额的量 由此可以反推该渠道一开始的流量也是非常巨大的,一旦0896 该渠道关闭或者出现振荡会大幅度影响整个流量的减少;
建议:1.尽量保持该超头部渠道的稳定
2.可以借鉴0896 渠道投放的人群特点进行分析,找出可以进行复刻的特点精准投放与其他头部渠道,并且在其他头部渠道进行精准投放该类似群体时间在13-14或者15到22 一些不好的渠道关注是否投放人群有误,是否存在转化率过低和本身流量过少的问题,进行调整。
对于0896的渠道分析:

我们可以看到前半年基本处于增长的态势,后半年有着略微的下降,但是整体来看依然是处于增长的状态。
再取平台这边的数据看一下该渠道的人数主要分布于哪些平台。

由图可知渠道0896 的人数主要还是分布在4和6之间,人数购买的占比达到了16%左右。
而且,通过以上展示,我们也可以看到GMV也是主要集中在,4-6,判断主要受了渠道0896的影响,从渠道0986 的流量大多在4,6平台上进行购买:
通过对渠道0986的分析,再结合0986 的人群特征我们就可以复刻于其他头部渠道,并且尽可能多的投放于4和6平台。观察效果
商品TOP分析:

可以看到第一名产品与之后的产品相差至少在18%以上,我们对这前10热销产品进行月维度的拆分:
select *,(sum_payment-rnk) ‘增长’ from (
select * ,lag(sum_payment,1) over(partition by goodsID) rnk from (
select benben.goodsID,month,round(sum(payment),2) sum_payment from benben
INNER join (select goodsID from benben
group by goodsID
order by sum(payment) DESC
limit 10)a
on a. goodsID=benben.goodsID
group by benben.goodsID,month
) p )a
order by goodsID



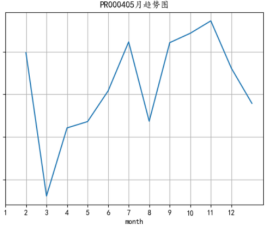






可以看到分别是排名3,4,8,9,10 都开始有大幅度的下降,而且仍旧有往下跌的趋势,要对这几个热销产品进行关注且分别对与对应的店家进行沟通做出补救措施,稳定热销单品的销售,整体的结构并不稳定,除此之外还应关注排名第十之后的产品,对于一路走高的产品,合理抬高价格,牟取利润。
描述性分析结束;
进入深入分析:
RFM:
目的:1.对用户进行分群,对不同的用户群体进行不同的运营策略
2.对该平台自身反馈,明确当前平台定位,明确主要发展方向,明确主要服务群体。
RFM使用了两种方法,通过对指标R,F,M的构建,
1并使用均值或者中位数作为阈值进行分割,再将三列值组合在一起,进行打标签
2.使用K-means算法,通过轮廓系数来进行取最优K。

画了金额的箱型图,在普通数值上来看有很多的异常值,但是基于金额的自身属性无法将其去除,则无法使用平均值作为阈值,于是我们使用中位数来进行分割。
def rfm(self,data):
data=data[['userID','payment','payTime','order']]
payment=data.groupby(by='userID')['payment'].sum()
print(payment.mean())
print(payment.median())
plt.boxplot(payment,vert=True)
plt.show()
data=data.pivot_table(index='userID',values=['payTime','order','payment'],aggfunc={'payTime':'max','payment':'sum','order':'count'})
# print(data)
data.rename(columns={'payTime':'R','order':'F','payment':'M'},inplace=True)
# print(pf)
data['R']=(data['R'].max()-data['R']).dt.days
pf=data.copy()
pf['label']=pf[['R','F','M']].apply(lambda x: x-x.median()).apply(return_def,axis=1)
d={
'011':'重要价值客户',
'111':'重要唤回客户',
'001':'重要深耕客户',
'101':'重要挽留客户',
'010':'潜力客户',
'110':'一般维持客户',
'000':'新客户',
'100':'流失客户',
}
pf=pf.replace({'label':d})
print(pf)
# # print(data)
result=pf['label'].value_counts()
print(result)
sns.barplot(x=result.index,y=result.values)
plt.show()

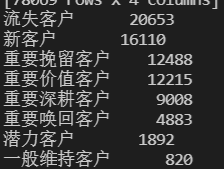
计算每一列的中位数,对其进行中位数的划分,打标签沿用网上通用的划分方法得到以上结果
主要分析流失用户和新客户;
流失用户:可以看到有接近2万的用户处于100状态,对于这种用户要区别对待,不能单单采取常用的发送邮件,短信推送。要去结合该流失用户的主要群体特征分析,对于有相同特征的用户群体提前进行预警,并且两者对比分析,再进行流失用户的召回,除此之外,完善用户流失召回体制,以及辅助指标:客服接受投诉信息,以及投诉电话,都可以作为先见型指标,对于流失进行提前预警。
新客户:1.6万的新用户处于000的状态,说明他们的金额,频率都低于此次分析的中位数,而且可知,这1.6万的用户都是在下半年涌入的,对于新用户进行同期群分析来看看,在不同的阶段新用户的留存和客单价的情况
K-means:
金额存在比较多的离群点:使用归一化来缩放数据,则数据将更集中在均值附近。这是由于归一化的缩放是“拍扁”统一到区间(仅由极值决定),而标准化的缩放是更加“弹性”和“动态”的,和整体样本的分布有很大的关系。所以归一化不能很好地处理离群值,而标准化对异常值的鲁棒性强,在许多情况下,它优于归一化。所以此次对数据标准化
K-means方法,先通过轮廓系数来确定最优的K值,然后计算中位数,通过对阈值的分割之后进行打标签。
df=data.copy()
score_k=[]
df = np.array(df.loc[:,['R','F','M']])
# print(df)
scale=StandardScaler()
df=scale.fit_transform(df)
# print(df)
for i in range(2,10,1):
k_result=KMeans(n_clusters=i,random_state=20)
# df = np.array(df.loc[:,['R','F','M']])
# print(data)
k_result.fit(df)
# print(k_result.inertia_)
# score_k.append(k_result.inertia_)
# print(k_result.labels_)
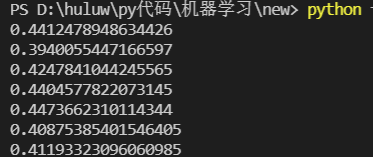
print(silhouette_score(df,k_result.labels_))
score_k.append(silhouette_score(df,k_result.labels_))
k_result=KMeans(n_clusters=6,random_state=20)
k_result.fit(df)
center=k_result.labels_
df=pd.DataFrame(df)
df.rename(columns={'0':'R','1':'F','2':'M'},inplace=True)
print(df)
# print(center)
df['index']=center
center=pd.DataFrame(k_result.cluster_centers_,columns=['R','F','M'])
center['label_name']=(center-center.median()).apply(return_def,axis=1)
print(center)
d={
'011':'重要价值客户',
'111':'重要唤回客户',
'001':'重要深耕客户',
'101':'重要挽留客户',
'010':'潜力客户',
'110':'一般维持客户',
'000':'新客户',
'100':'流失客户',
}
center=center.replace({'label_name':d})
print(center)
center=pd.DataFrame(center[['label_name']],columns=['label_name'])
# print(center)
center.reset_index(inplace=True)
print(center)
k_means_result=pd.merge(left=df,right=center,how='left',on='index')
k_means_result=k_means_result['label_name'].value_counts()
# # print(score_k)
sns.barplot(x=k_means_result.index,y=k_means_result.values)
# plt.xticks(range(len(k_means_result.index)),k_means_result.index)
plt.show()


得到6个聚类点,对于每列取中位数进行分割,按照组合进行打标签。得到以上结果。
一共是6类可以看到其中有几类都划分为新用户,所以K-means聚类实际只有4种结果,可以看到主要还是新用户和流失客户的数量较多。
流失用户:可以看到有2万的用户处于100状态,对于这种用户要区别对待,不能单单采取常用的发送邮件,短信推送。要去结合该流失用户的主要群体特征分析,对于有相同特征的用户群体提前进行预警,并且两者对比分析,再进行流失用户的召回,除此之外,完善用户流失召回体制,以及辅助指标:客服接受投诉信息,以及投诉电话,都可以作为先见型指标,对于流失进行提前预警。
新客户:4.2万的新用户处于000的状态,说明他们的金额,频率都低于此次分析的中位数,而且可知,这4.2万的用户都是在下半年涌入的,对于新用户进行同期群分析来看看,在不同的阶段新用户的留存和客单价的情况。
同期群分析;
同期群分析模型,是通过细分的方法,把同期的数据拿出来,比较相似群体随时间的变化
思路:找到每个用户的最小购买时间并取出粒度为月份求和当作该月的新用户,然后通过取到接下来每个月的相同的客户计算占比,客单价等进行横向纵向对比;
def better_anaylise(self,data):
like=data.groupby(by='userID',as_index=False)['payTime'].min()
like=pd.DataFrame(like)
like['like_month']=pd.to_datetime(like['payTime']).dt.month
first_buy=like.groupby(by='like_month')['payTime'].count()
result_people=pd.DataFrame(index=range(1,13),columns=range(1,13),data=np.zeros((12,12)))
result_atv=pd.DataFrame(index=range(1,13),columns=range(1,13),data=np.zeros((12,12)))
for j in range(1,13):
for i in range(j+1,13):
liucun_people=data[(data['userID'].isin(like[like['like_month']==j]['userID'])) & (data.month==i)]
people=liucun_people['userID'].unique().size
liucun_sum=data[(data['userID'].isin(like[like['like_month']==j]['userID'])) & (data.month==i)]
atv_payment=liucun_sum['payment'].sum()
atv=round(atv_payment/people,0)
result_atv.loc[j,i]=atv
result_people.loc[j,i]=people
result_people.loc[:,1]=first_buy
print(result_people)
result_people=round(result_people.loc[:,2:]/first_buy,5)
for i in range(1,13):
for j in range(i+1,13):
result_people.loc[i,j]="%.2f%%" % (result_people.loc[i,j] * 100)
print(result_people)
print(result_atv)
first_atv_month=[]
for i in range(1,12):
j=i+1
# print(result_atv.loc[i,j])
first_atv_month.append(result_atv.loc[i,j])
# print(first_atv_month)
first_atv_month=pd.DataFrame(first_atv_month,columns=['month_new_atv'])
本次观察新用户留存,客单价情况,以上为同期群结果
此次计算的是新用户在该电商平台的不同阶段所呈现的占比情况,
纵向:可以看到随着时间的变化,产品对于新用户的留存逐渐上升从3.31%,2.42%,逐渐上涨,以此可知,至少在新用户这块,该平台留存在逐渐的变好。
横向:对于不同时期进来的新用户我们可以看到最后基本都稳定在6.5%左右,而且因为数据有限(这只是一张购买表),我们仅能知道,用户在90天以后购买率还是逐渐上升的。说明用户对于该产品的粘性还是比较大的。
特别的:可以看到在5-7月的时候新用户留存都稳定在7.00%以上,在排除自然周期的情况下对他进行更详细的排查,寻找优质人群和当时的产品特点与现在进行对比,进行小流量实验,推往更多用户群体。
对于客单价来说:可以看到有下降的趋势,无论是从横向还是纵向都处于下降的状态,有公式客单价=总金额/总人数 在新用户留存稳定上升的前提下,客单价下降,说明总金额应该是不高的,推测该产品初期进行了大量活动,例如首单减免,反复的薅羊毛导致客单价大大拉低了平均客单价


建议:
1.争对不同的用户群体,进行不同程度的刺激,结合RFM我们知道该平台目前主要集中为新用户,关注整个新用户的用户流程,对用户流程,提高转化且对于新用户首先要能迅速体验到产品价值,并且在尽量降低用户体验的情况下,引导用户下单购买
2.应该提高首单门槛,或者降低活动优惠对于反复享受活动的用户应减少活动优惠的力度
。
流失周期:
流失周期指的就是如果用户在这个时期内没有进行活跃, 在这个流失周期左右的时间是我们最好去干预用户的时间,所以这个流失周期也是一个先见型指标,在用户群体内我们可以知道有多少用户处于流失周期内。
在此次分析里,我们定义活跃为 购买行为,对于a客户第一次购买之后再次购买的时间间隔,
分别取每个用户购买的最小时间,再计算第二次,分别观察整体平均值,中位数,90%分位数。
lost_time=data.groupby(by='userID')['payTime'].min()
# print(lost_time)
second_time=data[(data['userID'].isin(lost_time.index)) & (~data['payTime'].isin(lost_time.values))]
second_time=second_time.groupby(by='userID')['payTime'].min()
result=pd.merge(left=lost_time,right=second_time,how='inner',on='userID')
print(result)
result['distance']=(result['payTime_y']-result['payTime_x']).dt.days
print(result['distance'].quantile(0.9))
print(result['distance'].mean())
print(result['distance'].median())
plot_result=result['distance'].value_counts().sort_values(ascending=False)
# print(plot_result)
plt_plot=pd.DataFrame(plot_result)
# plt_plot['占比']=plt_plot/plt_plot.sum()
print(plt_plot)
sns.lineplot(x=range(len(plot_result)),y=plot_result)
plt.xticks(range(len(plot_result))[::10],list(plot_result)[::10],rotation=90)
plt.show()
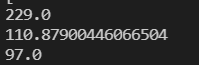

结果如上:我们采取中位数来作为流失周期的天数也就是97天,也就是说如果一个用户在这个周期里都没有在这个周期内不活跃的话, 之后活跃的可能性也不高。所以我们就要尽可能在这个时间段来干预用户,引导用户进行第二次购买。
具体的运营措施可以是:
1.根据不同的用户群体计算更为精细的流失周期,通过不同的流失周期作为先见型指标,在用户流失之前进行干预。
2.基于不同的用户群体群体可以做横向对比:在一些比较重要的用户群体即:具有重要价值的用户流失周期可以进行减小,加强干预能力,结合弃买率等反向指标进行优化。
总结:
1.整体来看:渠道产品的结构都不稳定,存在断层现象,应在保证超头部渠道产品稳定的情况下,提升其他优质渠道产品,达到稳定金字塔的状态,其次可以对0896渠道及超头部产品进行持续跟进,一边深挖目标客户的用户进行复刻,一边在这些大流量的渠道和产品做小规模的探索实验。
2.平台涌入大批量新用户,新用户复购率稳定上升,但是客单价逐渐减少,出现大量薅羊毛的客户,建议提高首单价格,对于反复享受购买优惠的用户应该降低其折扣力度。持续优化新用户用户流程,对于转化率和绝对值进行追踪,如何改进这块,应该进行小流量实验进行决策选择。
3.先见型指标,流失周期的建立,以及完善流失用户的召回机制,对于平台存在大量的流失用户,要进行定期召回,并且分析,用户流失是在哪一个环节,进行反向指标的构建,如弃买率,退货率进行观察。对其转化率较低的环节进行优化调整。















 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









