







某电商平台数据分析报告(1)——代码部分
1.说明:撰写代码更为精进,质量更高,将多次调用的方法和参数打包为函数,一改往日代码冗长的风格。
2.1引入第三方库:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
import datetime2.2 整体数据概况 :
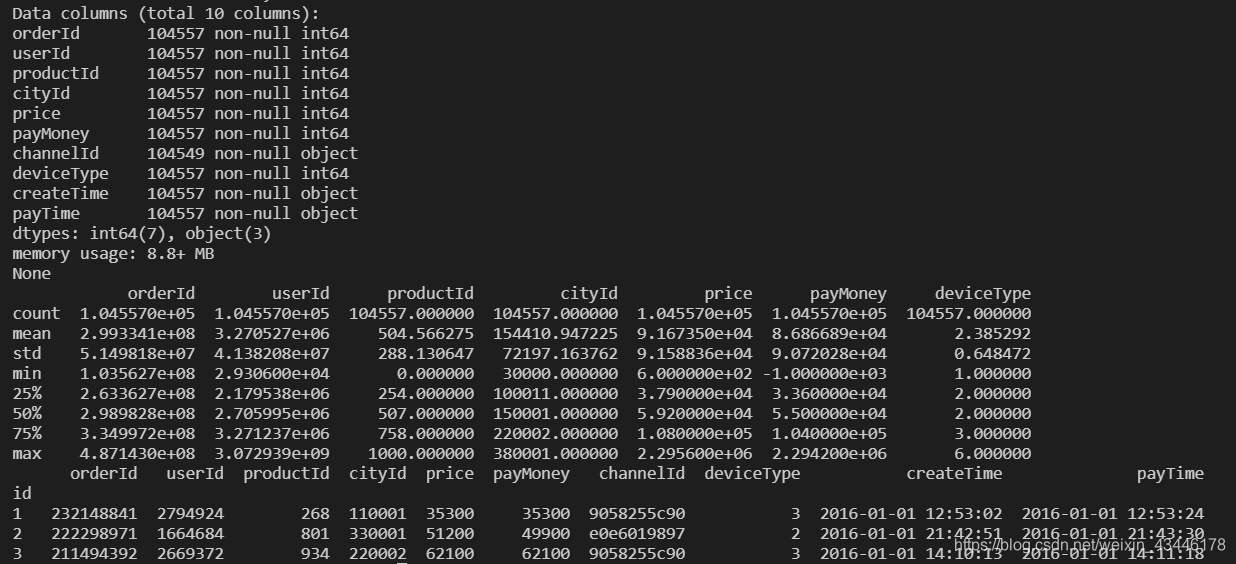
图1
据观察:目前看来,在channeId字段存在缺失,其他数据基本完整,前三条记录无异样。
3.1 数据清洗:采用各个字段分别处理,相关字段合并处理的方法。对其异常值,重复值,缺失值进行相关的处理。
orderId(订单ID) :去重
print(df.orderId.unique().size)
df.drop(index=df[df['orderId'].duplicated()].index,inplace=True)userId(用户ID):可以出现多个相同ID,也没有缺失值,无操作。
productId: 无缺失值,允许存在重复值,观察可知,字段中有0出现,可能是刚刚上架\下架所致,因为没有关于productId的具体数据,且该字段为0的数据不多,删除。
df.drop(index=df[df['productId']==0].index,inplace=True)cityId(城市ID):无缺失无异常,允许重复值,无操作。
price&payMoney(价格&实付金额):联合处理。据观察,price字段最小值为600,不合常理,且价格后两位都为0,判断该数据单位为分,除以100即可,去除payMoney <=0 的值,查看是否存在支付金额大于原价格的记录。
df['price']=df['price']/100
df['payMoney']=df['payMoney']/100
df.drop(index=df[df['payMoney']<0].index,inplace=True)
print(df[df['payMoney']>df['price']])
channeId(渠道ID):存在缺失值,无异常,可重复。
df.drop(index=df[df['channelId'].isnull()].index,inplace=True)deviceType(设备类型):无异常,可重复。数据显示为类型ID共6种,文本说明里对应5种,将其ID改为原有设备名,对于第六种,因缺失对应值删除。
df.drop(index=df[df['deviceType']==6].index,inplace=True)
d={'1':'PC',
'2':'Android',
'3':'iPhone',
'4':'Wap',
'5':'other'}
df['deviceType']=df['deviceType'].astype(str).replace(d)createTime&payTime(订单时间&支付时间)
时间格式转换为pandas类型,无重复无缺失,删除订单时间大于支付时间,删除订单时间和支付时间相隔较长,设定此次时间间隔为30分钟,以下单时间为准,只取在2016.1.1-2016.12.31.23.59.59时间段内。
start_time=datetime.datetime(2016,1,1)
final_time=datetime.datetime(2016,12,31,23,59,59)
df['createTime']=pd.to_datetime(df['createTime'])
df['payTime']=pd.to_datetime(df['payTime'])
df.drop(index=df[df['createTime']<start_time].index,inplace=True)
df.drop(index=df[df.createTime > df['payTime']].index,inplace=True)
df.drop(index=df[(df['payTime']-df['createTime']).dt.total_seconds()>1800].index,inplace=True)至此,数据清洗完毕。
4.数据分析(代码):
4.1
GMV: 9.47 千万
实际支付额:8.98 千万
客单价: 869.54元
全年订单数量:103308
全年用户数量:101450
#GMV 9.47千万
print(df.price.sum()/10000000)#94793726.0
#净成交总额 8.98千万
print(df.payMoney.sum())#89831006.4
#客单价
print(df.payMoney.sum()/df.userId.count())
# 订单数量
print(df.orderId.unique().size)
# 用户数量
print(df.userId.unique().size)每月销售额:
#每月销售额\实际成交额
df['month']=df['createTime'].dt.month
month_GMV=df.groupby('month')['price'].sum()/1000000#百万为单位
month_clean_amount=df.groupby('month')['payMoney'].sum()/1000000#百万为单位 一周七天内订单数量:
df['day']=df['createTime'].dt.dayofweek
week=['星期一','星期二','星期三','星期四','星期五','星期六','星期天']
day=df.groupby(by='day')['orderId'].count()
day.index=week获取渠道前20 和后20:
channelId_data1=df.groupby(by='channelId')['userId'].count().sort_values(ascending=False)[:20]
channelId_data2=df.groupby(by='channelId')['userId'].count().sort_values(ascending=True)[:20]
城市ID划分前20和后20:
city_id1=df.groupby(by='cityId')['userId'].count().sort_values(ascending=False)[:20]
city_id2=df.groupby(by='cityId')['userId'].count().sort_values(ascending=True)[:20]流量来源:
data_device=df.groupby(by='deviceType')['userId'].count()最优价格区间:
#最优价格区间
bins=[0,1000,3000,6000,10000,20000]
df['price_around']=pd.cut(df['price'],bins)
price_around=df['price_around'].value_counts()
print(price_around)最受欢迎产品前10 和后10名:
product1=df.groupby(by='productId')['userId'].count().sort_values(ascending=False)[:10]
product2=df.groupby(by='productId')['userId'].count().sort_values(ascending=True)[:10] 复购率(调用pivot_table()用户为行,月份为列,计算每个月的复购率):
#复购率
user_count=df.pivot_table(index='userId',columns='month',values='createTime',aggfunc='count').fillna(0)
# print(user_count)
twice_user=user_count.applymap(lambda x:1 if x>1 else np.nan if x==0 else 0)
repeat_prpority=round(twice_user.sum()/twice_user.count(),4)
# print(repeat_prpority)RFM模型:
def func(x):
level=x.apply(lambda x:'1' if x>=1 else '0')
label=level.R+level.F+level.M
d={'011':'重要价值客户','111':'重要唤回客户','001':'重要深耕客户','101':'重要挽留客户','010':'潜力客户','110':'一般维持客户','000':'新客户','100':'流失客户',}
return d[label]
#RFM
df['order']=1
df['createTime']=pd.to_datetime(df['createTime'],format='%Y-%m-%d')
dff=df.pivot_table(index=df['userId'],values=['payMoney','createTime','order'],
aggfunc={'payMoney':'sum', 'createTime':'max','order':'count'})
dff['R']=(dff['createTime'].max()-dff['createTime']).dt.days
# print(dff)
dff=dff.rename(columns={'order':'F','payMoney':'M'})
dff['label']=dff[['R','F','M']].apply(lambda x:x-x.mean()).apply(func,axis=1)
# print(dff)
label=dff['label'].value_counts()
# sns_bar(label)
print(label)可视化分别打包成函数,方便调用,调用时,改变个别参数即可:
def sns_bar(a):
plt.figure(figsize=(20,8),dpi=80)
sns.barplot(x=a.index,y=a.values,palette='deep')
#x_label=['{}月份'.format(i) for i in a.index]
#plt.xticks(range(len(a.index)),a.index,rotation=90)
plt.xlabel('类型')
plt.ylabel('人数')
plt.title('RFM模型')
sns.barplot(x=a.index,y=a.values,palette='deep')
plt.xticks(range(len(a.index)),a.index)
for a,b in zip(range(len(a.index)),a.values):
plt.text(a,b,b,ha='center')
plt.show()
def plt_plot(a,b):
plt.title('各个月份 GMV\实际成交额 ')
plt.plot(a.index,a.values,marker='*',label='GMV')
plt.plot(a.index,b.values,marker='o',label='实际成交额')
# x_label=['{}月份'.format(i) for i in a.index]
plt.xticks(a.index,rotation=45)
plt.xlabel('月份')
plt.ylabel('金额')
plt.legend()
#折线坐标
for a,b in zip(a.index,a.values):
plt.annotate('(%.2f万)'%b,xy=(a,b),xytext=(-10,10),textcoords='offset points')
plt.show()
def plt_pie(a):
plt.figure(figsize=(20,8),dpi=80)
plt.title('最优价格区间')
plt.pie(a,labels=a.index,shadow=True,autopct='%1.2f%%')
plt.show()













 2100
2100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









