







 本文介绍了基于策略的强化学习,包括策略梯度的基础知识、降低方差的方法和Actor-Critic策略。讨论了策略梯度的优化目标、蒙特卡罗策略梯度及如何利用baseline和Critic来减小方差。还提到了现代RL算法如A2C、A3C、TRPO、PPO和SAC,以及策略和价值函数学派的差异。
本文介绍了基于策略的强化学习,包括策略梯度的基础知识、降低方差的方法和Actor-Critic策略。讨论了策略梯度的优化目标、蒙特卡罗策略梯度及如何利用baseline和Critic来减小方差。还提到了现代RL算法如A2C、A3C、TRPO、PPO和SAC,以及策略和价值函数学派的差异。
课程大纲
基于策略的强化学习:前面讲的都是基于价值的强化学习,这次讲基于策略函数去优化的强化学习
蒙特卡罗策略梯度
如何降低策略梯度的方差
Actor-Critic:同时学习策略函数和价值函数
基于策略的强化学习基础知识
Value-based RL 与 Policy-based RL:
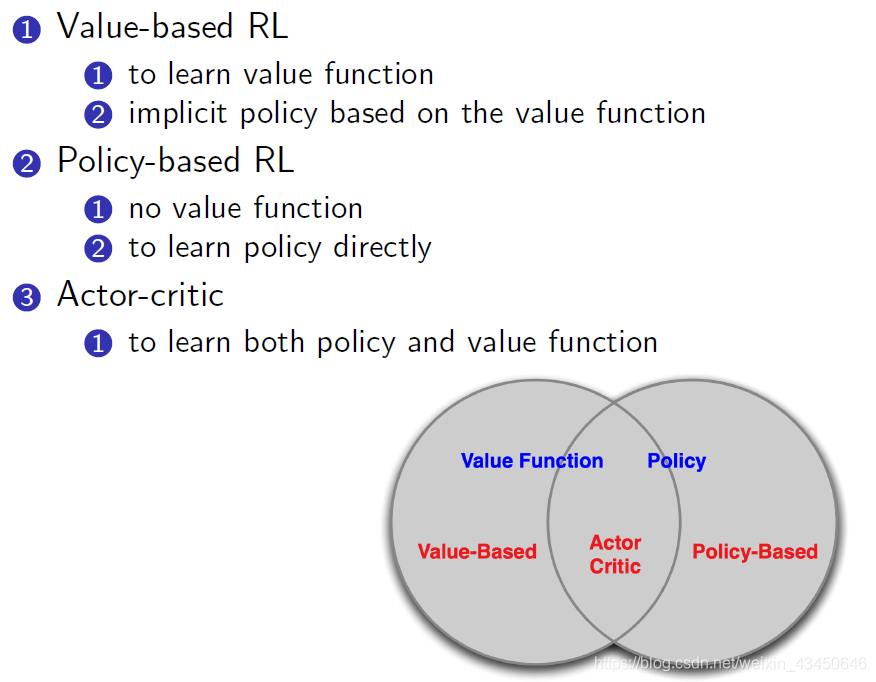
Policy-based RL 的优势与劣势:

策略的分类:
(1)确定性策略
(2)概率分布性策略
对策略进行优化的过程中,优化目标是什么?
给定一个带参数的策略逼近函数(类似于值函数逼近),我们就是要找到最优的
怎么去评价一个策略 呢?【废话,当然是用值函数啊】
从环境的角度去看:
(1)对于 episodic 的环境:可以用最开始的那个 value
![]()
(2)对于 continuing 环境:可以用平均的 value;也可以用平均的 reward
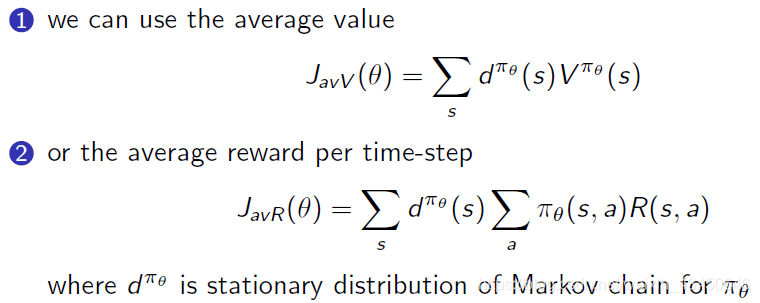
从轨迹的角度去看:

怎么去优化我们的目标方程 呢?
(1)当目标方程
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









