







 本文详细介绍了Kubernetes中对Container、Pod、Namespace的内存和CPU资源限制,包括LimitRange和ResourceQuota的配置与作用。此外,还讨论了节点选择器nodeSelector、节点亲和性与反亲和性、污点与容忍度,以及如何通过daemonset和sidecar模式进行日志收集。通过对资源限制、调度策略和日志管理的深入探讨,帮助读者更好地理解Kubernetes集群的资源管理和优化。
本文详细介绍了Kubernetes中对Container、Pod、Namespace的内存和CPU资源限制,包括LimitRange和ResourceQuota的配置与作用。此外,还讨论了节点选择器nodeSelector、节点亲和性与反亲和性、污点与容忍度,以及如何通过daemonset和sidecar模式进行日志收集。通过对资源限制、调度策略和日志管理的深入探讨,帮助读者更好地理解Kubernetes集群的资源管理和优化。
一、Kubernetes Container、Pod、Namespace内存及CPU限制
1、限制范围 | Kubernetes
默认情况下, Kubernetes 集群上的容器运行使用的计算资源没有限制。 使用 Kubernetes 资源配额, 管理员(也称为 集群操作者)可以在一个指定的命名空间内限制集群资源的使用与创建。 在命名空间中,一个 Pod 最多能够使用命名空间的资源配额所定义的 CPU 和内存用量。 作为集群操作者或命名空间级的管理员,你可能也会担心如何确保一个 Pod 不会垄断命名空间内所有可用的资源。
LimitRange 是限制命名空间内可为每个适用的对象类别 (例如 Pod 或 PersistentVolumeClaim) 指定的资源分配量(限制和请求)的策略对象。
一个 LimitRange(限制范围) 对象提供的限制能够做到:
- 在一个命名空间中实施对每个 Pod 或 Container 最小和最大的资源使用量的限制。
- 在一个命名空间中实施对每个 PersistentVolumeClaim 能申请的最小和最大的存储空间大小的限制。
- 在一个命名空间中实施对一种资源的申请值和限制值的比值的控制。
- 设置一个命名空间中对计算资源的默认申请/限制值,并且自动的在运行时注入到多个 Container 中。
当某命名空间中有一个 LimitRange 对象时,将在该命名空间中实施 LimitRange 限制。
1、资源限制和请求的约束
- 管理员在一个命名空间内创建一个
LimitRange对象。 - 用户在此命名空间内创建(或尝试创建) Pod 和 PersistentVolumeClaim 等对象。
- 首先,
LimitRanger准入控制器对所有没有设置计算资源需求的所有 Pod(及其容器)设置默认请求值与限制值。 - 其次,
LimitRange跟踪其使用量以保证没有超出命名空间中存在的任意LimitRange所定义的最小、最大资源使用量以及使用量比值。 - 若尝试创建或更新的对象(Pod 和 PersistentVolumeClaim)违反了
LimitRange的约束, 向 API 服务器的请求会失败,并返回 HTTP 状态码403 Forbidden以及描述哪一项约束被违反的消息。 - 若你在命名空间中添加
LimitRange启用了对cpu和memory等计算相关资源的限制, 你必须指定这些值的请求使用量与限制使用量。否则,系统将会拒绝创建 Pod。 LimitRange的验证仅在 Pod 准入阶段进行,不对正在运行的 Pod 进行验证。 如果你添加或修改 LimitRange,命名空间中已存在的 Pod 将继续不变。- 如果命名空间中存在两个或更多
LimitRange对象,应用哪个默认值是不确定的。
2、Pod 的 LimitRange 和准入检查
LimitRange 不 检查所应用的默认值的一致性。 这意味着 LimitRange 设置的 limit 的默认值可能小于客户端提交给 API 服务器的规约中为容器指定的 request 值。 如果发生这种情况,最终 Pod 将无法调度。
3、资源需求与限制
相比较而言,CPU属于可压缩型资源,即资源额度可按需弹性变化,而内存(当前)则是不可压缩型资源,对其执行压缩操作可能会导致某种程度的问题,例如进程崩溃等。目前,资源隔离仍属于容器级别,CPU和内存资源的配置主要在Pod对象中的容器上进行,并且每个资源存在如图4-16所示的需求和限制两种类型。为了表述方便,人们通常把资源配置称作Pod资源的需求和限制,只不过它是指Pod内所有容器上的某种类型资源的请求与限制总和。

-
资源需求:定义需要系统预留给该容器使用的资源最小可用值,容器运行时可能用不到这些额度的资源,但用到时必须确保有相应数量的资源可用。
-
资源限制:定义该容器可以申请使用的资源最大可用值,超出该额度的资源使用请求将被拒绝;显然,该限制需要大于等于requests的值,但系统在某项资源紧张时,会从容器回收超出request值的那部分。
在Kubernetes系统上,1个单位的CPU相当于虚拟机上的1颗虚拟CPU(vCPU)或物理机上的一个超线程(Hyperthread,或称为一个逻辑CPU),它支持分数计量方式,一个核心(1 core)相当于1000个微核心(millicores,以下简称为m),因此500m相当于是0.5个核心,即1/2个核心。内存的计量方式与日常使用方式相同,默认单位是字节,也可以使用E、P、T、G、M和K为单位后缀,或Ei、Pi、Ti、Gi、Mi和Ki形式的单位后缀。
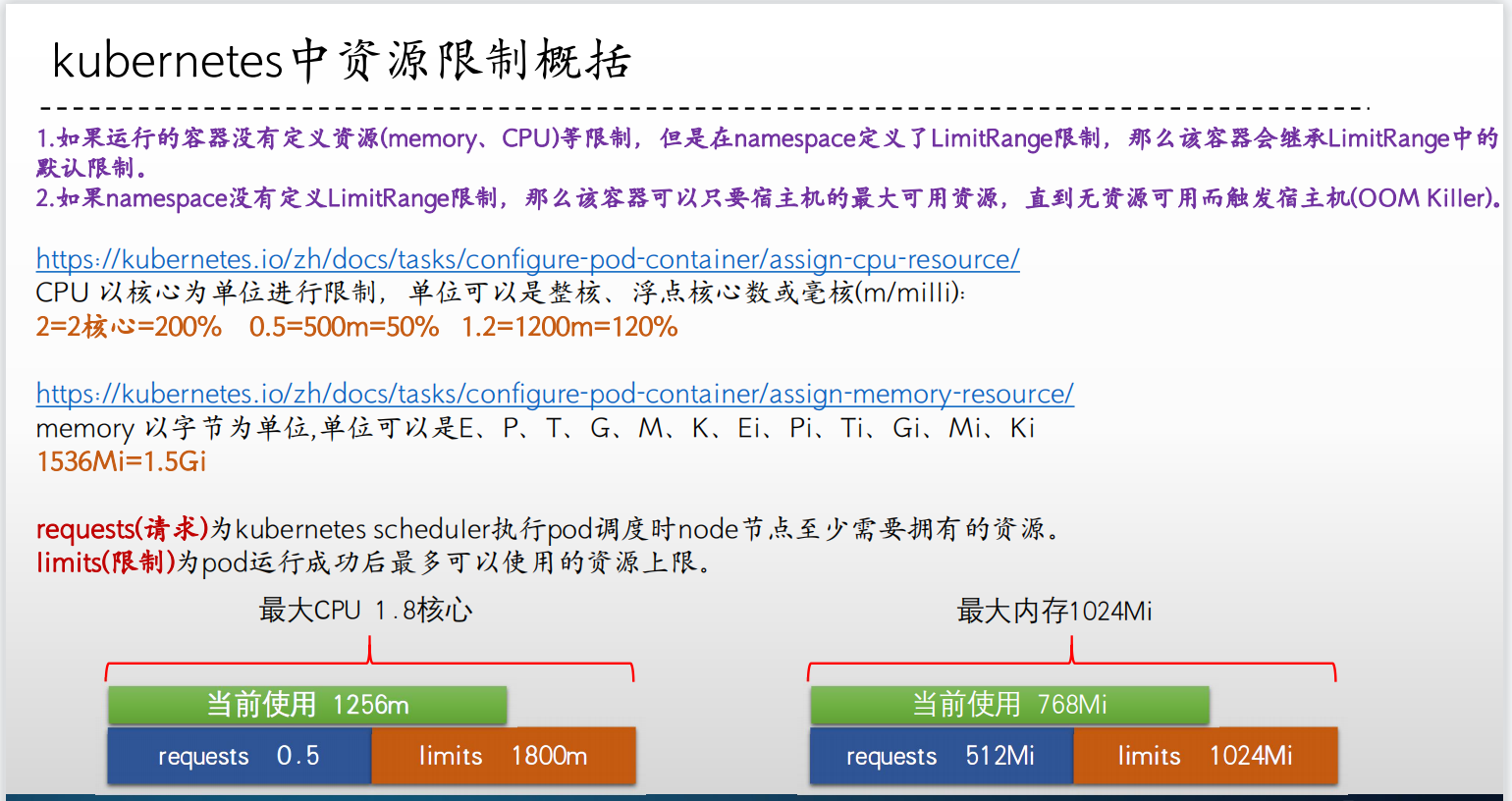
2、单个容器的 memory 资源限制
为容器和 Pods 分配 CPU 资源 | Kubernetes
root@k8s-deploy:/yaml/20220821/magedu-limit-case# vim case1-pod-memory-limit.yml
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
kind: Deployment
metadata:
name: limit-test-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels: #rs or deployment
app: limit-test-pod
# matchExpressions:
# - {key: app, operator: In, values: [ng-deploy-80,ng-rs-81]}
template:
metadata:
labels:
app: limit-test-pod
spec:
containers:
- name: limit-test-container
image: lorel/docker-stress-ng
resources:
limits:
memory: "256Mi" # 限制256Mi
requests:
memory: "256Mi" # 需求256Mi
#command: ["stress"]
args: ["--vm", "2", "--vm-bytes", "256M"] # 启动2个线程,每个线程占用256Mi内存(总共512Mi内存)
#nodeSelector:
# env: group1
memory 使用始终在 256Mi 下,cpu 没做限制,所以把剩余 cpu 占满了。
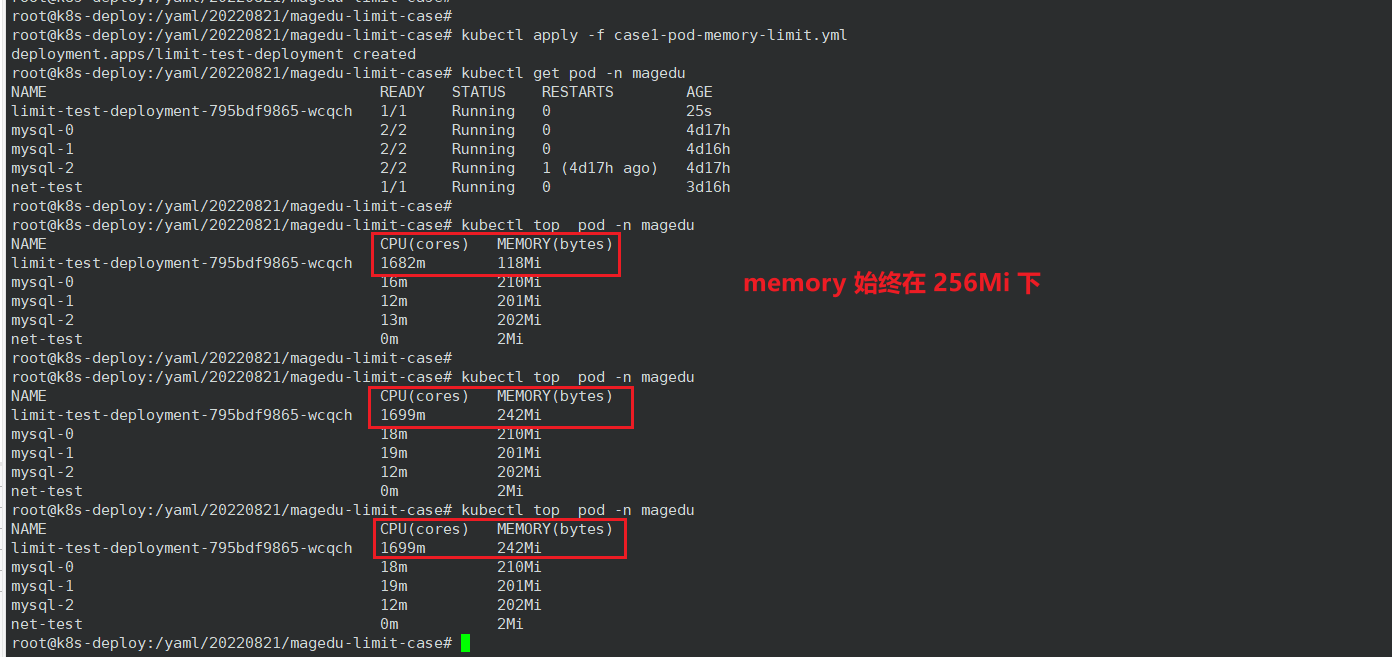
3、单个容器的 CPU 和 memory 资源限制
root@k8s-deploy:/yaml/20220821/magedu-limit-case# vim case2-pod-memory-and-cpu-limit.yml
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
kind: Deployment
metadata:
name: limit-test-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels: #rs or deployment
app: limit-test-pod
# matchExpressions:
# - {key: app, operator: In, values: [ng-deploy-80,ng-rs-81]}
template:
metadata:
labels:
app: limit-test-pod
spec:
containers:
- name: limit-test-container
image: lorel/docker-stress-ng
resources:
limits:
cpu: "300m" # cpu 限制300毫核
memory: "256Mi"
requests:
memory: "256Mi"
cpu: "300m"
#command: ["stress"]
args: ["--vm", "3", "--vm-bytes", "256M"]
#nodeSelector:
# env: group1
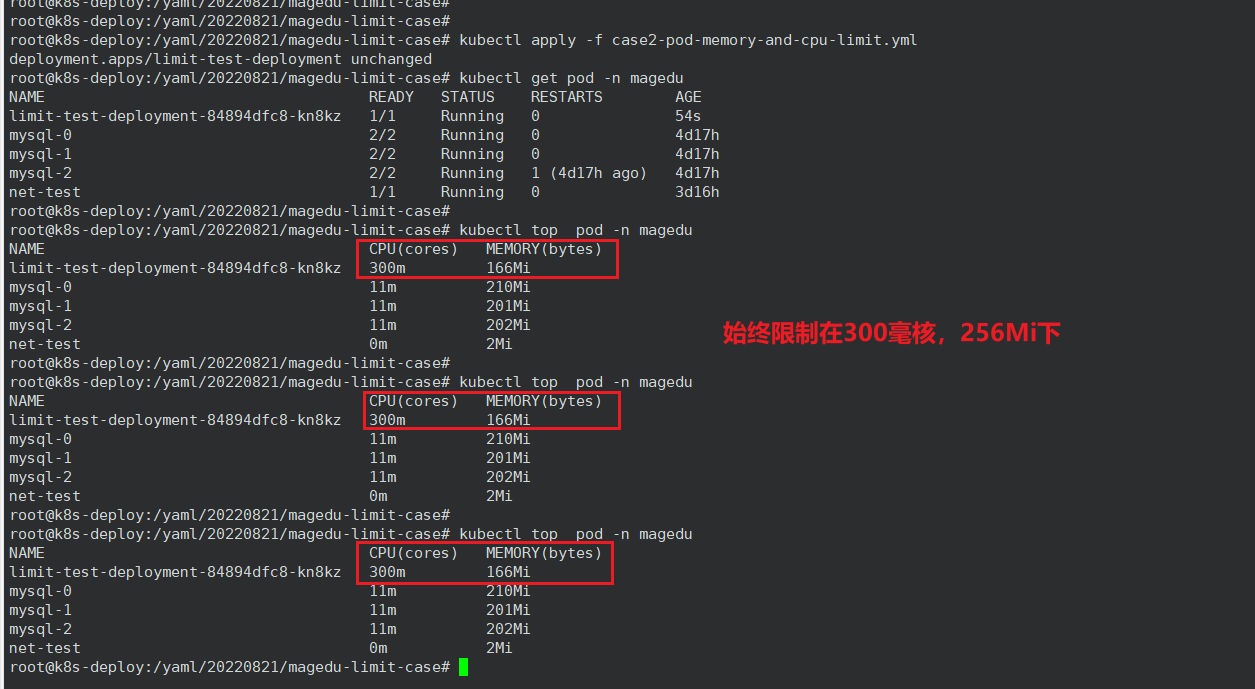
4、LimitRange 准入控制器
LimitRange 是限制命名空间内可为每个适用的对象类别 (例如 Pod 或 PersistentVolumeClaim) 指定的资源分配量(限制和请求)的策略对象。
一个 LimitRange(限制范围) 对象提供的限制能够做到:
- 在一个命名空间中实施对每个 Pod 或 Container 最小和最大的资源使用量的限制。
- 在一个命名空间中实施对每个 PersistentVolumeClaim 能申请的最小和最大的存储空间大小的限制。
- 在一个命名空间中实施对一种资源的申请值和限制值的比值的控制。
- 设置一个命名空间中对计算资源的默认申请/限制值,并且自动的在运行时注入到多个 Container 中。
当某命名空间中有一个 LimitRange 对象时,将在该命名空间中实施 LimitRange 限制。
1、创建 LimitRange
root@k8s-deploy:/yaml/20220821/magedu-limit-case# vim case3-LimitRange.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: limitrange-magedu
namespace: magedu
spec:
limits:
- type: Container #限制的资源类型(容器、pod、pvc 等)
max:
cpu: "2" #限制单个容器的最大CPU
memory: "2Gi" #限制单个容器的最大内存
min:
cpu: "500m" #限制单个容器的最小CPU
memory: "512Mi" #限制单个容器的最小内存
default:
cpu: "500m" #默认单个容器的CPU限制
memory: "512Mi" #默认单个容器的内存限制
defaultRequest:
cpu: "500m" #默认单个容器的CPU创建请求
memory: "512Mi" #默认单个容器的内存创建请求
maxLimitRequestRatio:
cpu: 2 #限制CPU limit/request比值最大为2
memory: 2 #限制内存 limit/request比值最大为2
- type: Pod
max:
cpu: "4" #限制单个Pod的最大CPU
memory: "4Gi" #限制单个Pod最大内存
- type: PersistentVolumeClaim
max:
storage: 50Gi #限制PVC最大的requests.storage
min:
storage: 30Gi #限制PVC最小的requests.storage
2、cpu 的 limit/request 比值超出 LimitRange 定义的最大值
此处演示 cpu 的 limit/request 比值超过 LimitRange 定义的最大值2,导致了 Pod 无法创建。
root@k8s-deploy:/yaml/20220821/magedu-limit-case# cat case4-pod-RequestRatio-limit.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
app: magedu-wordpress-deployment-label
name: magedu-wordpress-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels:
app: magedu-wordpress-selector
template:
metadata:
labels:
app: magedu-wordpress-selector
spec:
containers:
- name: magedu-wordpress-nginx-container
image: nginx:1.16.1
imagePullPolicy: Always
ports:
- containerPort: 80
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits:
cpu: 1.5 # 限制1.5核 cpu
memory: 1Gi
requests:
cpu: 500m # 请求500毫核 cpu,limit/request 比值为3,超过了 LimitRange 定义的最大值2,所以 pod 无法创建。
memory: 512Mi
- name: magedu-wordpress-php-container
image: php:5.6-fpm-alpine
imagePullPolicy: Always
ports:
- containerPort: 80
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits:
cpu: 2
#cpu: 2
memory: 1Gi
requests:
cpu: 2000m
memory: 512Mi
---
kind: Service
apiVersion: v1
metadata:
labels:
app: magedu-wordpress-service-label
name: magedu-wordpress-service
namespace: magedu
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
nodePort: 30033
selector:
app: magedu-wordpress-selector
本例中 limit 为1.5核 cpu,request 为500毫核 cpu,cpu 的 RequestRatio 比值为3,超过了 LimitRange 定义的最大值2,所以 pod 无法创建。表现为:明明 kubectl apply 了,但是 kubectl get pod 查不到任何痕迹。
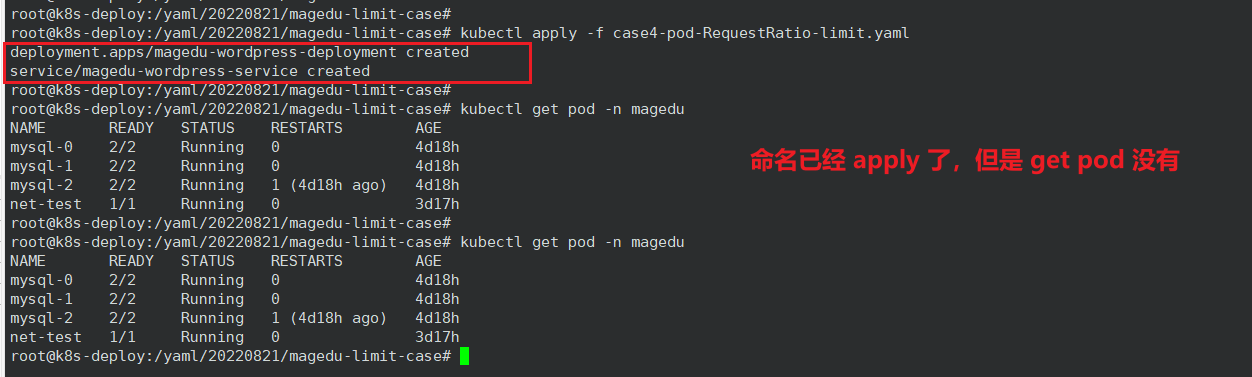
我们可以查询 deployment ,发现没有 ready,使用 kubectl -n magedu get deployments.apps magedu-wordpress-deployment -o json 命令查看 deployment ,可以看到报错:pods \"magedu-wordpress-deployment-b78d895b6-vc29d\" is forbidden: cpu max limit to request ratio per Container is 2, but provided ratio is 3.000000

此处涉及到了 RBAC 鉴权流程:身份验证和鉴权通过了,但是第三步准入控制没通过。

同理,Pod 的 cpu 和内存超出限制、容器的 cpu 和内存超出限制、limit/request 比值超出限制都可以这样查找原因。
5、整个 namespace 的 CPU 和内存资源限制
-
限定某个对象类型(如 pod、service)可创建对象的总数
-
限定某个对象类型可消耗的计算资源(CPU、内存)与存储资源(存储卷声明)总数
资源配额 | Kubernetes,通过 ResourceQuota 对象来定义,对每个命名空间的资源消耗总量提供限制。 它可以限制命名空间中某种类型的对象的总数目上限,也可以限制命名空间中的 Pod 可以使用的计算资源的总上限。
资源配额的工作方式如下:
- 不同的团队可以在不同的命名空间下工作。这可以通过 RBAC 强制执行。
- 集群管理员可以为每个命名空间创建一个或多个 ResourceQuota 对象。
- 当用户在命名空间下创建资源(如 Pod、Service 等)时,Kubernetes 的配额系统会跟踪集群的资源使用情况, 以确保使用的资源用量不超过 ResourceQuota 中定义的硬性资源限额。
- 如果资源创建或者更新请求违反了配额约束,那么该请求会报错(HTTP 403 FORBIDDEN), 并在消息中给出有可能违反的约束。
- 如果命名空间下的计算资源 (如
cpu和memory)的配额被启用, 则用户必须为这些资源设定请求值(request)和约束值(limit),否则配额系统将拒绝 Pod 的创建。 提示: 可使用LimitRanger准入控制器来为没有设置计算资源需求的 Pod 设置默认值。
说明:
- 对于
cpu和memory资源:ResourceQuota 强制该命名空间中的每个(新)Pod 为该资源设置限制。 如果你在命名空间中为cpu和memory实施资源配额, 你或其他客户端必须为你提交的每个新 Pod 指定该资源的requests或limits。 否则,控制平面可能会拒绝接纳该 Pod。 - 对于其他资源:ResourceQuota 可以工作,并且会忽略命名空间中的 Pod,而无需为该资源设置限制或请求。 这意味着,如果资源配额限制了此命名空间的临时存储,则可以创建没有限制/请求临时存储的新 Pod。 你可以使用限制范围自动设置对这些资源的默认请求。
计算资源配额
用户可以对给定命名空间下的可被请求的 计算资源 总量进行限制。
配额机制所支持的资源类型:
| 资源名称 | 描述 |
|---|---|
limits.cpu | 所有非终止状态的 Pod,其 CPU 限额总量不能超过该值。 |
limits.memory | 所有非终止状态的 Pod,其内存限额总量不能超过该值。 |
requests.cpu | 所有非终止状态的 Pod,其 CPU 需求总量不能超过该值。 |
requests.memory | 所有非终止状态的 Pod,其内存需求总量不能超过该值。 |
hugepages-<size> | 对于所有非终止状态的 Pod,针对指定尺寸的巨页请求总数不能超过此值。 |
cpu | 与 requests.cpu 相同。 |
memory | 与 requests.memory 相同。 |
1、创建 ResourceQuota
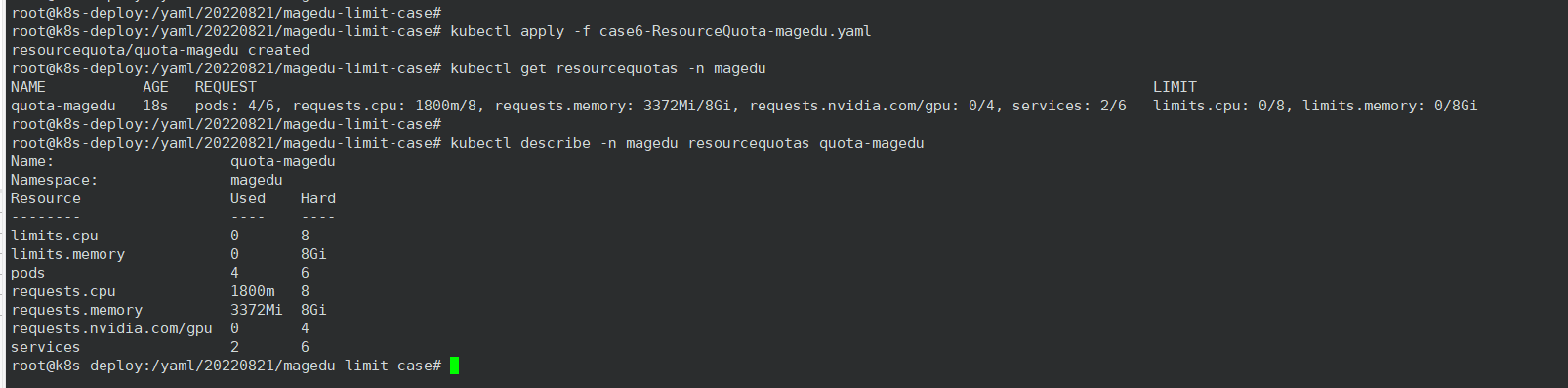
root@k8s-deploy:/yaml/20220821/magedu-limit-case# vim case6-ResourceQuota-magedu.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: quota-magedu
namespace: magedu
spec:
hard:
requests.cpu: "8" # 在该命名空间中所有 Pod 的 CPU 请求总和不能超过 8 cpu
limits.cpu: "8" # 在该命名空间中所有 Pod 的 CPU 限制总和不能超过 8 cpu
requests.memory: 8Gi # 在该命名空间中所有 Pod 的内存请求总和不能超过 8 GiB
limits.memory: 8Gi # 在该命名空间中所有 Pod 的内存限制总和不能超过 8 GiB
requests.nvidia.com/gpu: 4
pods: "6" # 在该命名空间中只能创建 6 个 pod
services: "6" # 在该命名空间中只能创建 6 个 service
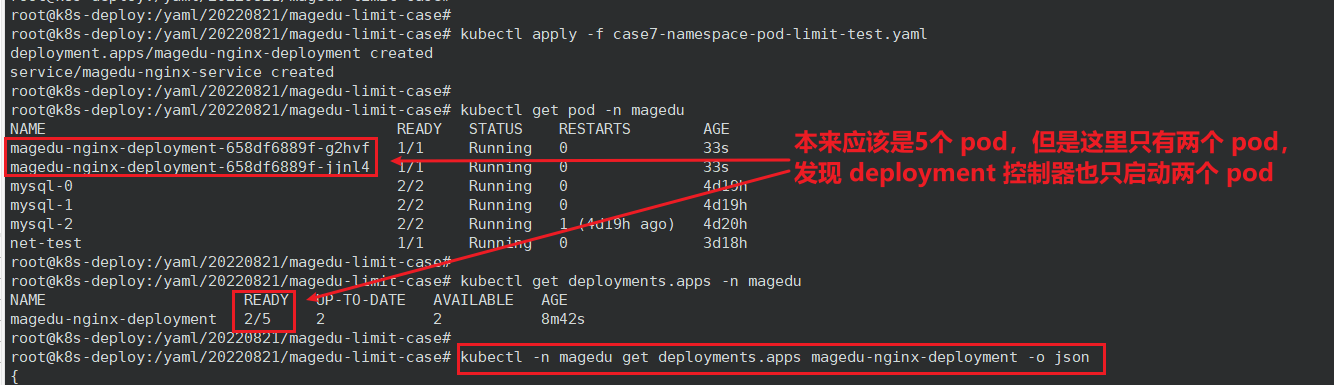
2、Pod 副本数超出限制
本例中我要创建5个副本,但是该 namespace 已经存在4个 Pod 了,所以最后只能创建两个 Pod 。
root@k8s-deploy:/yaml/20220821/magedu-limit-case# cat case7-namespace-pod-limit-test.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
app: magedu-nginx-deployment-label
name: magedu-nginx-deployment
namespace: magedu
spec:
replicas: 5
selector:
matchLabels:
app: magedu-nginx-selector
template:
metadata:
labels:
app: magedu-nginx-selector
spec:
containers:
- name: magedu-nginx-container
image: nginx:1.16.1
imagePullPolicy: Always
ports:
- containerPort: 80
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits:
cpu: 1
memory: 1Gi
requests:
cpu: 500m
memory: 512Mi
---
kind: Service
apiVersion: v1
metadata:
labels:
app: magedu-nginx-service-label
name: magedu-nginx-service
namespace: magedu
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
nodePort: 30033
selector:
app: magedu-nginx-selector

3、CPU 总计核数超出限制
在本例中,我创建两个副本,每个 Pod 请求4核 cpu 和4g内存,已经超出限制。
root@k8s-deploy:/yaml/20220821/magedu-limit-case# cat case8-namespace-cpu-limit-test.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
app: magedu-nginx-deployment-label
name: magedu-nginx-deployment
namespace: magedu
spec:
replicas: 2
selector:
matchLabels:
app: magedu-nginx-selector
template:
metadata:
labels:
app: magedu-nginx-selector
spec:
containers:
- name: magedu-nginx-container
image: nginx:1.16.1
imagePullPolicy: Always
ports:
- containerPort: 80
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits:
cpu: 8
memory: 4Gi
requests:
cpu: 4
memory: 4Gi
---
kind: Service
apiVersion: v1
metadata:
labels:
app: magedu-nginx-service-label
name: magedu-nginx-service
namespace: magedu
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
nodePort: 30033
selector:
app: magedu-nginx-selector
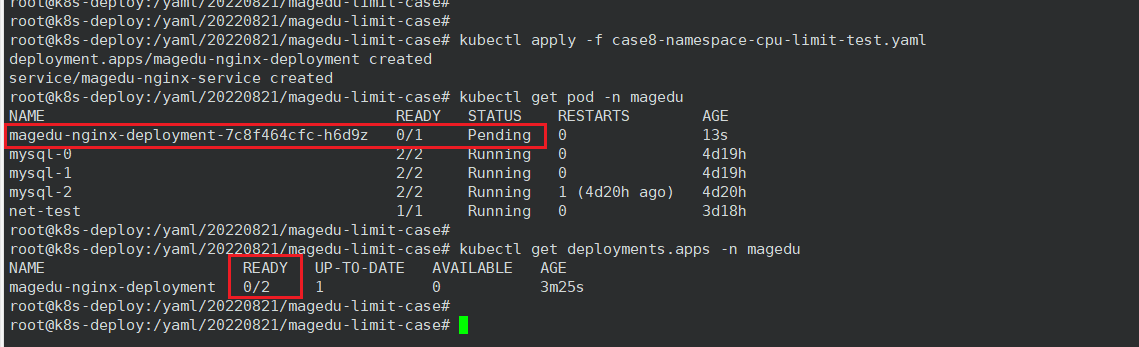
root@k8s-deploy:/yaml/20220821/magedu-limit-case# kubectl describe -n magedu pod magedu-nginx-deployment-7c8f464cfc-h6d9z

root@k8s-deploy:/yaml/20220821/magedu-limit-case# kubectl -n magedu get deployments.apps magedu-nginx-deployment -o json

二、nodeSelector、nodeName、node亲和与反亲和、pod亲和与反亲和、污点与容忍、驱逐
1、将 Pod 指派给节点 | Kubernetes
你可以约束一个 Pod 以便 限制 其只能在特定的节点上运行, 或优先在特定的节点上运行。 有几种方法可以实现这点,推荐的方法都是用 标签选择算符来进行选择。 通常这样的约束不是必须的,因为调度器将自动进行合理的放置(比如,将 Pod 分散到节点上, 而不是将 Pod 放置在可用资源不足的节点上等等)。但在某些情况下,你可能需要进一步控制 Pod 被部署到哪个节点。例如,确保 Pod 最终落在连接了 SSD 的机器上, 或者将来自两个不同的服务且有大量通信的 Pods 被放置在同一个可用区。
你可以使用下列方法中的任何一种来选择 Kubernetes 对特定 Pod 的调度:
节点标签
与很多其他 Kubernetes 对象类似,节点也有标签。 你可以手动地添加标签。 Kubernetes 也会为集群中所有节点添加一些标准的标签。 参见常用的标签、注解和污点以了解常见的节点标签。
说明:
这些标签的取值是取决于云提供商的,并且是无法在可靠性上给出承诺的。 例如,kubernetes.io/hostname 的取值在某些环境中可能与节点名称相同, 而在其他环境中会取不同的值。
nodeSelector
nodeSelector 是节点选择约束的最简单推荐形式。你可以将 nodeSelector 字段添加到 Pod 的规约中设置你希望目标节点所具有的节点标签。 Kubernetes 只会将 Pod 调度到拥有你所指定的每个标签的节点上。
进一步的信息可参见将 Pod 指派给节点。
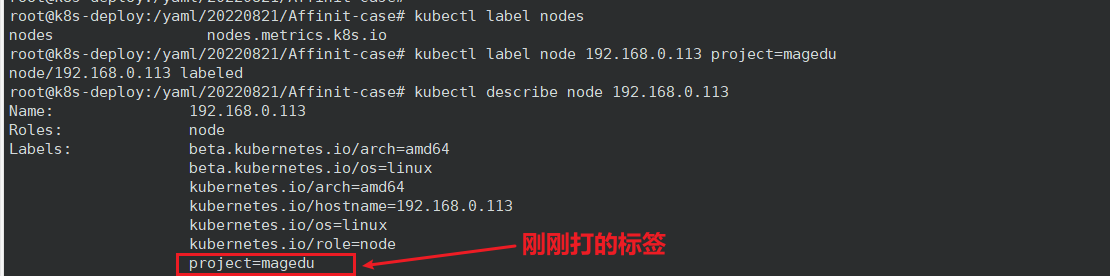
如何给节点打标签?
# 打标签,key=value
kubectl label node 192.168.0.113 project=magedu
# 取消标签,在 key 后面加上减号“-”
kubectl label node 192.168.0.113 project-
nodeSelector 案例
本例将 Pod 调度到含有标签 project: magedu的节点上。
root@k8s-deploy:/yaml/20220821/Affinit-case# cat case1-nodeSelector.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits:
cpu: 1
memory: "512Mi"
requests:
cpu: 500m
memory: "512Mi"
nodeSelector:
project: magedu # 将 pod 调度到有 project: magedu 标签的节点
#disktype: ssd

问题现象:Pod的状态为Pending。
问题原因:若Pod停留在Pending状态,说明该Pod不能被调度到某一个节点上。通常是由于资源依赖、资源不足、该Pod使用了hostPort、污点和容忍等原因导致集群中缺乏需要的资源。
Pod 不能被调度到节点是说明这个可能是节点的标签打错了,我们用 describe 看下节点的标签:
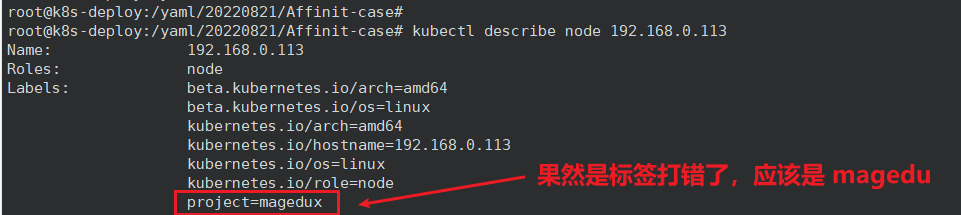
修改节点标签后不用重新 apply ,因为是动态生效的:

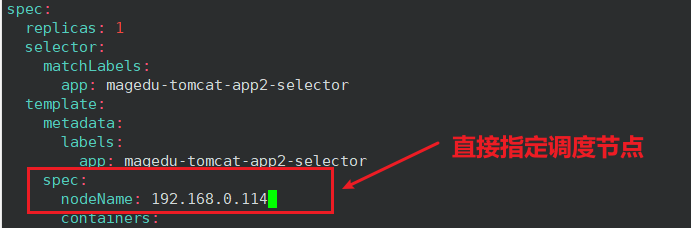
nodeName 案例
直接指定 Pod 调度到某个节点。用的很少。
2、亲和性与反亲和性
nodeSelector 提供了一种最简单的方法来将 Pod 约束到具有特定标签的节点上。 亲和性和反亲和性扩展了你可以定义的约束类型。使用亲和性与反亲和性的一些好处有:
- 亲和性、反亲和性语言的表达能力更强。
nodeSelector只能选择拥有所有指定标签的节点。 亲和性、反亲和性为你提供对选择逻辑的更强控制能力。 - 你可以标明某规则是“软需求”或者“偏好”,这样调度器在无法找到匹配节点时仍然调度该 Pod。
- 你可以使用节点上(或其他拓扑域中)运行的其他 Pod 的标签来实施调度约束, 而不是只能使用节点本身的标签。这个能力让你能够定义规则允许哪些 Pod 可以被放置在一起。
亲和性功能由两种类型的亲和性组成:
- 节点亲和性功能类似于
nodeSelector字段,但它的表达能力更强,并且允许你指定软规则。 - Pod 间亲和性/反亲和性允许你根据其他 Pod 的标签来约束 Pod。
2.1、节点亲和性 nodeaffinity
在Pod上定义节点亲和规则时有两种类型的节点亲和关系:强制(required)亲和和首选(preferred)亲和,或分别称为硬亲和与软亲和,本书会不加区别地使用这两种称呼。强制亲和限定了调度Pod资源时必须要满足的规则,无可用节点时Pod对象会被置为Pending状态,直到满足规则的节点出现。相比较来说,首选亲和规则实现的是一种柔性调度限制,它同样倾向于将Pod运行在某类特定的节点之上,但无法满足调度需求时,调度器将选择一个无法匹配规则的节点,而非将Pod置于Pending状态。
节点亲和性概念上类似于 nodeSelector, 它使你可以根据节点上的标签来约束 Pod 可以调度到哪些节点上。 节点亲和性有两种:
requiredDuringSchedulingIgnoredDuringExecution: 硬亲和,调度器只有在规则被满足的时候才能执行调度。此功能类似于nodeSelector, 但其语法表达能力更强。preferredDuringSchedulingIgnoredDuringExecution: 软亲和,调度器会尝试寻找满足对应规则的节点。如果找不到匹配的节点,调度器仍然会调度该 Pod。
说明:
在上述类型中,IgnoredDuringExecution 意味着如果节点标签在 Kubernetes 调度 Pod 后发生了变更,Pod 仍将继续运行。
在Pod资源基于节点亲和规则调度至某节点之后,因节点标签发生了改变而变得不再符合Pod定义的亲和规则时,调度器也不会将Pod从此节点上移出,因而
亲和调度仅在调度执行的过程中进行一次即时的判断,而非持续地监视亲和规则是否能够得以满足。

2.1.1、硬亲和
Pod规范中的.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution字段用于定义节点的强制亲和关系,它的值是一个对象列表,可由一到多个nodeSelectorTerms对象组成,彼此间为“逻辑或”关系。nodeSelectorTerms用于定义节点选择器,其值为对象列表,它支持matchExpressions和matchFields两种复杂的表达机制。
- matchExpressions:标签选择器表达式,基于节点标签进行过滤;可重复使用以表达不同的匹配条件,各条件间为“或”关系。
- matchFields:以字段选择器表达的节点选择器;可重复使用以表达不同的匹配条件,各条件间为“或”关系。
硬亲和案例一:
先将节点打上标签
root@k8s-deploy:/yaml/20220821/Affinit-case# kubectl label node 192.168.0.114 disktype=ssd
node/192.168.0.114 labeled
root@k8s-deploy:/yaml/20220821/Affinit-case# kubectl label node 192.168.0.115 disktype=ssd
node/192.168.0.115 labeled
root@k8s-deploy:/yaml/20220821/Affinit-case# kubectl label node 192.168.0.113 disktype=hhd
node/192.168.0.113 labeled
有多个 matchExpressions,满足任何一个 matchExpressions 就算匹配成功;
一个 matchExpressions 里面有多个 key ,同时满足这几个 kye 要才算这个 matchExpressions 匹配成功;
一个 key 里有多个 value ,只要满足一个 value 就算这个 key 匹配成功
root@k8s-deploy:/yaml/20220821/Affinit-case# cat case3-1.1-nodeAffinity-requiredDuring-matchExpressions.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 5
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions: #匹配条件1,有一个key但是有多个values、则只要匹配成功一个value就可以调度
- key: disktype
operator: In
values:
- ssd # 只有一个value是匹配成功也可以调度
- xxx
- matchExpressions: #匹配条件2,有一个key但是有多个values、则只要匹配成功一个value就可以调度
- key: project
operator: In
values:
- mmm #即使这俩条件都匹配不上也可以调度,即多个matchExpressions只要有任意一个能匹配任何一个value就可以调用。
- nnn
本例中没有节点满足 project=mmm 或 project=nnn ,但是192.168.0.114和115这两个节点满足 disktype=ssd ,所以 Pod 将会被调度到这两个节点上:

如果我把两个 matchExpressions 匹配条件改了,使得没有一个节点满足条件,那么 Pod 的状态就会变成 Pending ,这就是硬亲和:硬亲和限定了调度Pod资源时必须要满足的规则,无可用节点时Pod对象会被置为Pending状态:
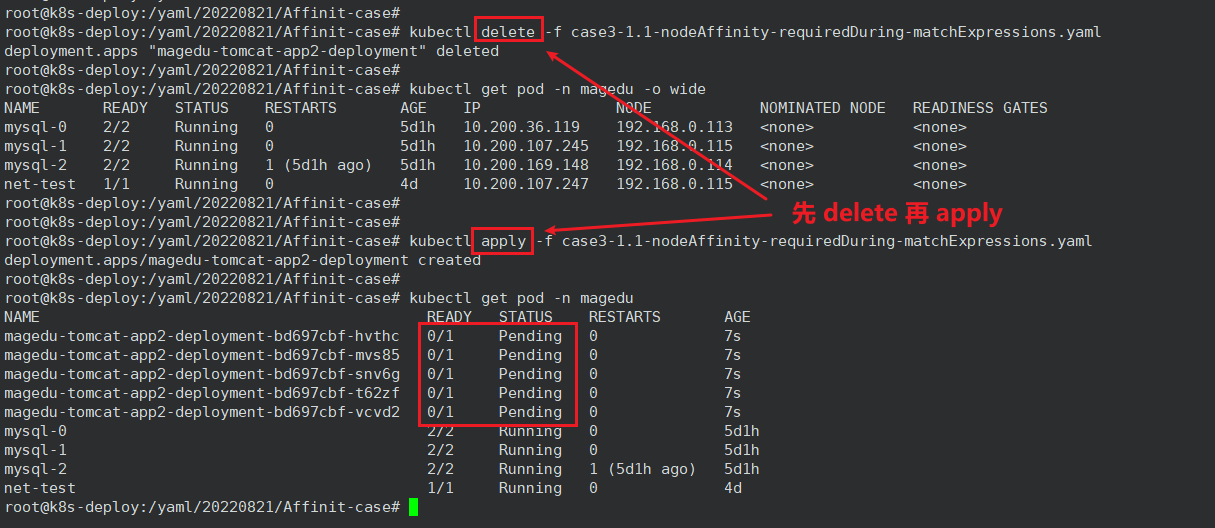
前面说了是动态更新,那么为什么还要先 delete 再 apply 呢?因为 yaml 文件的 requiredDuringSchedulingIgnoredDuringExecution 中的 IgnoredDuringExecution 意味着如果节点标签在 Kubernetes 调度 Pod 后发生了变更,Pod 仍将继续运行。
硬亲和案例二:
先给节点打上标签
root@k8s-deploy:/yaml/20220821/Affinit-case# kubectl label node 192.168.0.114 project=magedu
那么此时:
192.168.0.113 有标签 project=magedu,disktype=hhd
192.168.0.114 有标签 project=magedu,disktype=ssd
192.168.0.115 有标签 disktype=ssd
观察本例有一个 matchExpressions 中有两个 key ,所以要同时满足两个 key 才算匹配成功,所以 Pod 只会调度到114这个节点上。
root@k8s-deploy:/yaml/20220821/Affinit-case# cat case3-1.2-nodeAffinity-requiredDuring-matchExpressions.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions: #匹配条件1,同一个key的多个value只有有一个匹配成功就认为当前key匹配成功
- key: disktype
operator: In
values:
- ssd
- hddx
- key: project #匹配条件2,当前key也要匹配成功一个value,即条件1和条件2必须同时每个key匹配成功一个value,否则不调度
operator: In
values:
- magedu

2.1.2、软亲和
节点首选亲和机制(软亲和)为节点选择机制提供了一种柔性控制逻辑,被调度的Pod对象不再是“必须”,而是“应该”放置到某些特定节点之上,但条件不满足时,该Pod也能够接受被编排到其他不符合条件的节点之上。另外,多个软亲和条件并存时,它还支持为每个条件定义weight属性以区别它们优先级,取值范围是1~100,数字越大优先级越高。
软亲和案例一:
下面配置清单示例中,Pod模板定义了两个节点软亲和约束条件,它们有着不同的权重。示例中,Pod资源模板定义了节点软亲和,以选择尽量运行在指定范围内拥有 magedu 标签或者 ssd 标签的节点之上,其中 magedu 标签是更为重要的倾向性规则,它的权重为80,相比较来说 ssd 标签的重要性低了一级,因为它的权重为60。
这么一来,如果集群中拥有足够多的节点,它将被此规则分为4类:在指定范围内拥有 magedu 标签和 ssd 标签、仅满足 magedu 一个标签条件、仅满足 ssd 一个标签条件,以及不满足任何标签筛选条件的节点。
root@k8s-deploy:/yaml/20220821/Affinit-case# cat case3-2.1-nodeAffinity-preferredDuring.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 80 # 软亲和条件1,weight值越大优先级越高,越优先匹配调度
preference:
matchExpressions:
- key: project
operator: In
values:
- magedu
- weight: 60 # 软亲和条件2,在条件1不满足时匹配条件2
preference:
matchExpressions:
- key: disktype
operator: In
values:
- ssd
此时各节点标签情况:
192.168.0.113 有标签 project=magedu,disktype=hhd
192.168.0.114 有标签 project=magedu,disktype=ssd
192.168.0.115 有标签 disktype=ssd
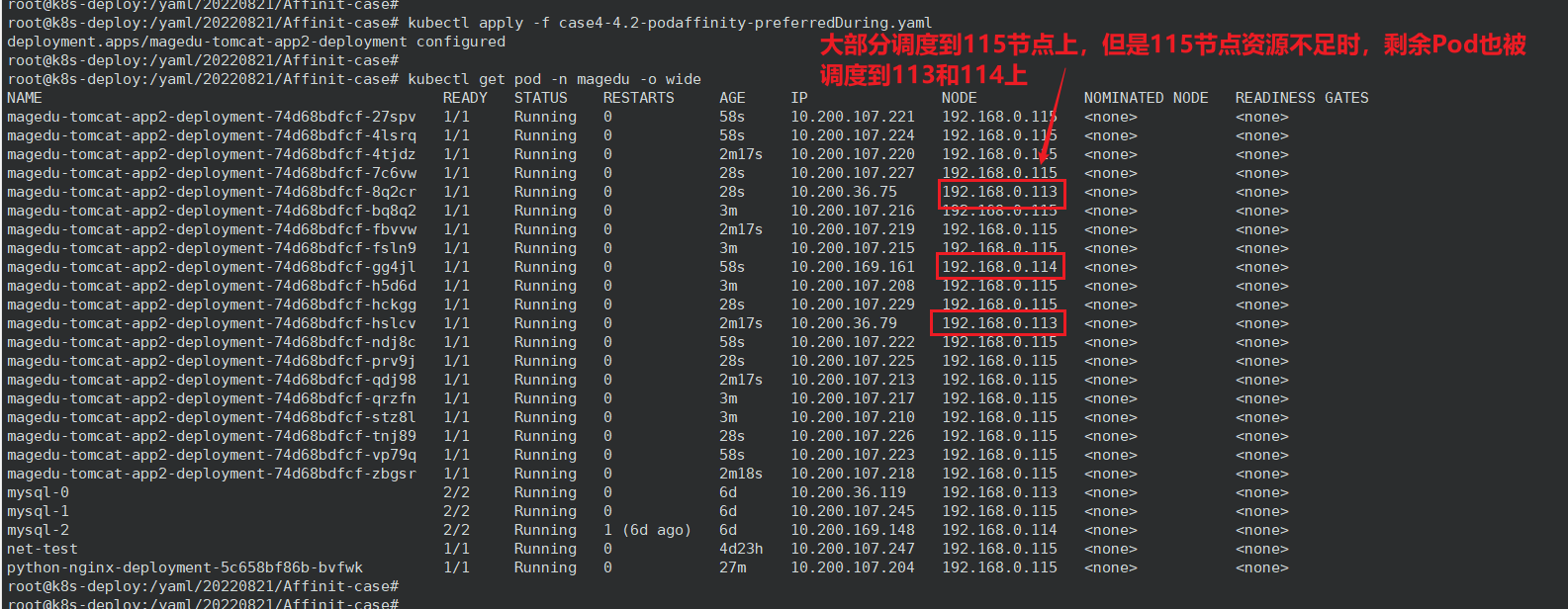
所以 Pod 会优先调度到 114 上,114 资源不足时就调度到 113 上,113 资源不足时就调度到 115 上。

硬亲和与软亲和结合使用
基于硬亲和与软亲和实现 Pod 调度:1、绝不会调度到哪些节点上。2、优先调度到哪些节点上。
本例中的调度机制:
1、硬亲和:不会调度到master节点(node反亲和);
2、软亲和:优先调度到有标签 magedu 和 hhd 的节点,次之是有标签 magedu 的节点,再次是有标签 hhd 的节点,最后是没有任何标签的节点。
root@k8s-deploy:/yaml/20220821/Affinit-case# cat case3-2.2-nodeAffinity-requiredDuring-preferredDuring.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: #硬亲和
nodeSelectorTerms:
- matchExpressions: #硬匹配条件1
- key: "kubernetes.io/role"
operator: NotIn
values:
- "master" #硬性匹配key 的值kubernetes.io/role不包含master的节点,即绝对不会调度到master节点(node反亲和)
preferredDuringSchedulingIgnoredDuringExecution: #软亲和
- weight: 80
preference:
matchExpressions:
- key: project
operator: In
values:
- magedu
- weight: 60
preference:
matchExpressions:
- key: disktype
operator: In
values:
- hdd
2.2、节点反亲和性 nodeantiaffinity
本例中 Pod 不会调度到有标签 disktype=hhd 的节点上。
此时各节点标签情况:
192.168.0.113 有标签 project=magedu,disktype=hhd
192.168.0.114 有标签 project=magedu,disktype=ssd
192.168.0.115 有标签 disktype=ssd
即不会调度到113这个节点上。
root@k8s-deploy:/yaml/20220821/Affinit-case# cat case3-3.1-nodeantiaffinity.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 3
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions: #匹配条件1
- key: disktype
operator: NotIn #调度的目的节点没有key为disktype且值为hhd的标签
values:
- hhd #绝对不会调度到含有label的key为disktype且值为hdd的hdd的节点,即会调度到没有key为disktype且值为hdd的hhd的节点

2.3、Pod 亲和性 podaffinity
出于高效通信等需求,偶尔需要把一些Pod对象组织在相近的位置(同一节点、机架、区域或地区等),例如应用程序的Pod及其后端提供数据服务的Pod等,我们可以认为这是一类具有亲和关系的Pod对象。偶尔,出于安全或分布式容灾等原因,也会需要把一些Pod对象与其所运行的位置隔离开来,例如在IDC中的区域运行某应用的单个代理Pod对象等,我们可把这类Pod对象间的关系称为反亲和。

2.3.1、硬亲和
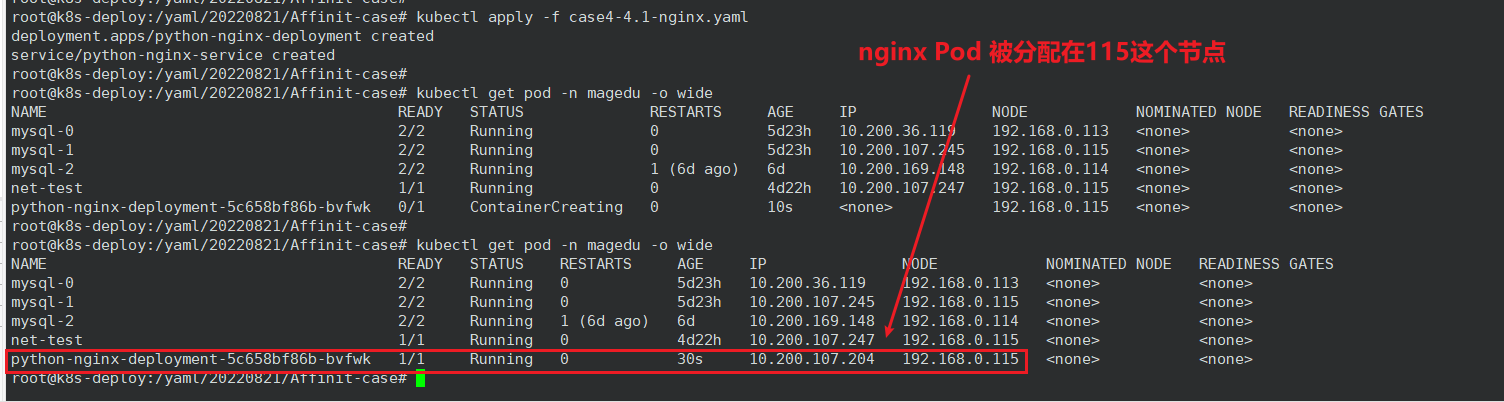
编写 yaml 文件,在 magedu namespace 部署一个 nginx 服务,nginx Pod 将用于后续的 Pod 亲和及反亲和测试,且该 nginx Pod 的 label 如下:
app: python-nginx-selector
project: python
部署 nginx WEB 服务:
root@k8s-deploy:/yaml/20220821/Affinit-case# cat case4-4.1-nginx.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: python-nginx-deployment-label
name: python-nginx-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels:
app: python-nginx-selector
template:
metadata:
labels:
app: python-nginx-selector
project: python
spec:
containers:
- name: python-nginx-container
image: nginx:1.20.2-alpine
#command: ["/apps/tomcat/bin/run_tomcat.sh"]
#imagePullPolicy: IfNotPresent
imagePullPolicy: Always
ports:
- containerPort: 80
protocol: TCP
name: http
- containerPort: 443
protocol: TCP
name: https
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
# resources:
# limits:
# cpu: 2
# memory: 2Gi
# requests:
# cpu: 500m
# memory: 1Gi
---
kind: Service
apiVersion: v1
metadata:
labels:
app: python-nginx-service-label
name: python-nginx-service
namespace: magedu
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
nodePort: 30014
- name: https
port: 443
protocol: TCP
targetPort: 443
nodePort: 30453
selector:
app: python-nginx-selector
project: python #一个或多个selector,至少能匹配目标pod的一个标签
基于硬亲和使得后续 Pod 必须和 nginx 在一个节点上,如果匹配不成功或者 nginx 所在节点资源不足时则拒绝调度,Pod将处于 Pending 状态。
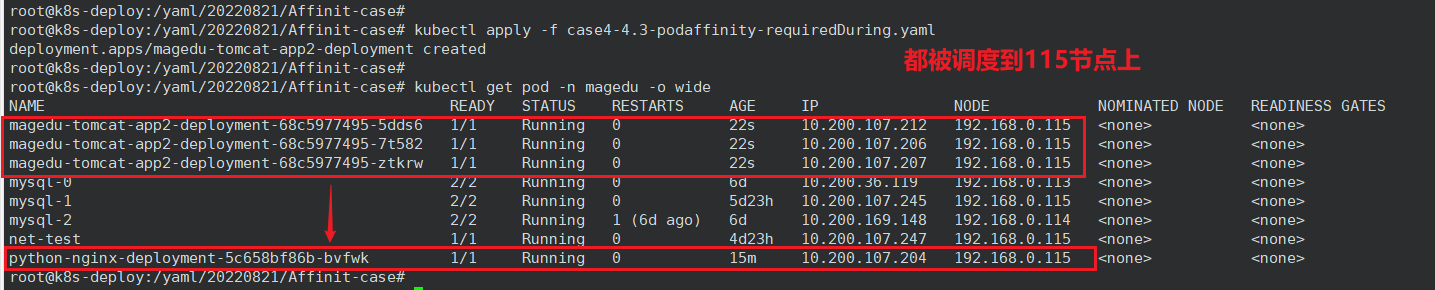
root@k8s-deploy:/yaml/20220821/Affinit-case# vim case4-4.3-podaffinity-requiredDuring.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 3
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # #硬亲和,必须匹配成功才调度,如果匹配失败则拒绝调度。
- labelSelector: # 标签选择
matchExpressions: # 正则匹配
- key: project
operator: In
values:
- python
topologyKey: "kubernetes.io/hostname" # 此处表示调度在同一个主机,本例中即为115节点
namespaces:
- magedu # 在 magedu 这个命名空间
2.3.2、软亲和
基于软亲和使得后续 Pod 尽量和 nginx 在一个节点上,如果匹配不成功或者 nginx 所在节点资源不足时则由 kubernetes 自行调度。
root@k8s-deploy:/yaml/20220821/Affinit-case# vim case4-4.2-podaffinity-preferredDuring.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 20
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
affinity:
podAffinity: #Pod亲和
#requiredDuringSchedulingIgnoredDuringExecution: #硬亲和,必须匹配成功才调度,如果匹配失败则拒绝调度。
preferredDuringSchedulingIgnoredDuringExecution: #软亲和,能匹配成功就调度到一个topology,匹配不成功会由kubernetes自行调度。
- weight: 100
podAffinityTerm:
labelSelector: #标签选择
matchExpressions: #正则匹配
- key: project
operator: In
values:
- python
topologyKey: kubernetes.io/hostname
namespaces:
- magedu
2.4、Pod 反亲和性 podantiaffinity
2.4.1、硬反亲和
基于硬反亲和使得后续 Pod 与 nginx 必须不在一个节点上
root@k8s-deploy:/yaml/20220821/Affinit-case# vim case4-4.4-podAntiAffinity-requiredDuring.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
affinity:
podAntiAffinity: # pod 反亲和
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: project
operator: In
values:
- python
topologyKey: "kubernetes.io/hostname"
namespaces:
- magedu

2.4.2、软反亲和
基于软反亲和使得后续 Pod 与 nginx 尽量不在一个节点上,如果剩余节点资源不足时则也会调度到 nginx 所在节点
root@k8s-deploy:/yaml/20220821/Affinit-case# vim case4-4.5-podAntiAffinity-preferredDuring.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app2-deployment-label
name: magedu-tomcat-app2-deployment
namespace: magedu
spec:
replicas: 1
selector:
matchLabels:
app: magedu-tomcat-app2-selector
template:
metadata:
labels:
app: magedu-tomcat-app2-selector
spec:
containers:
- name: magedu-tomcat-app2-container
image: tomcat:7.0.94-alpine
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100 # 权重值越大表示我越不想和带有python标签的Pod在一个节点
podAffinityTerm:
labelSelector:
matchExpressions:
- key: project
operator: In
values:
- python
- weight: 80 # 表示我第二不想和带有java标签的Pod在一个节点。也表示当剩余节点资源都不足时,我宁愿和java在一起,也不想和python在一起。
podAffinityTerm:
labelSelector:
matchExpressions:
- key: project
operator: In
values:
- java
topologyKey: kubernetes.io/hostname
namespaces:
- magedu

3、污点和容忍度 | Kubernetes
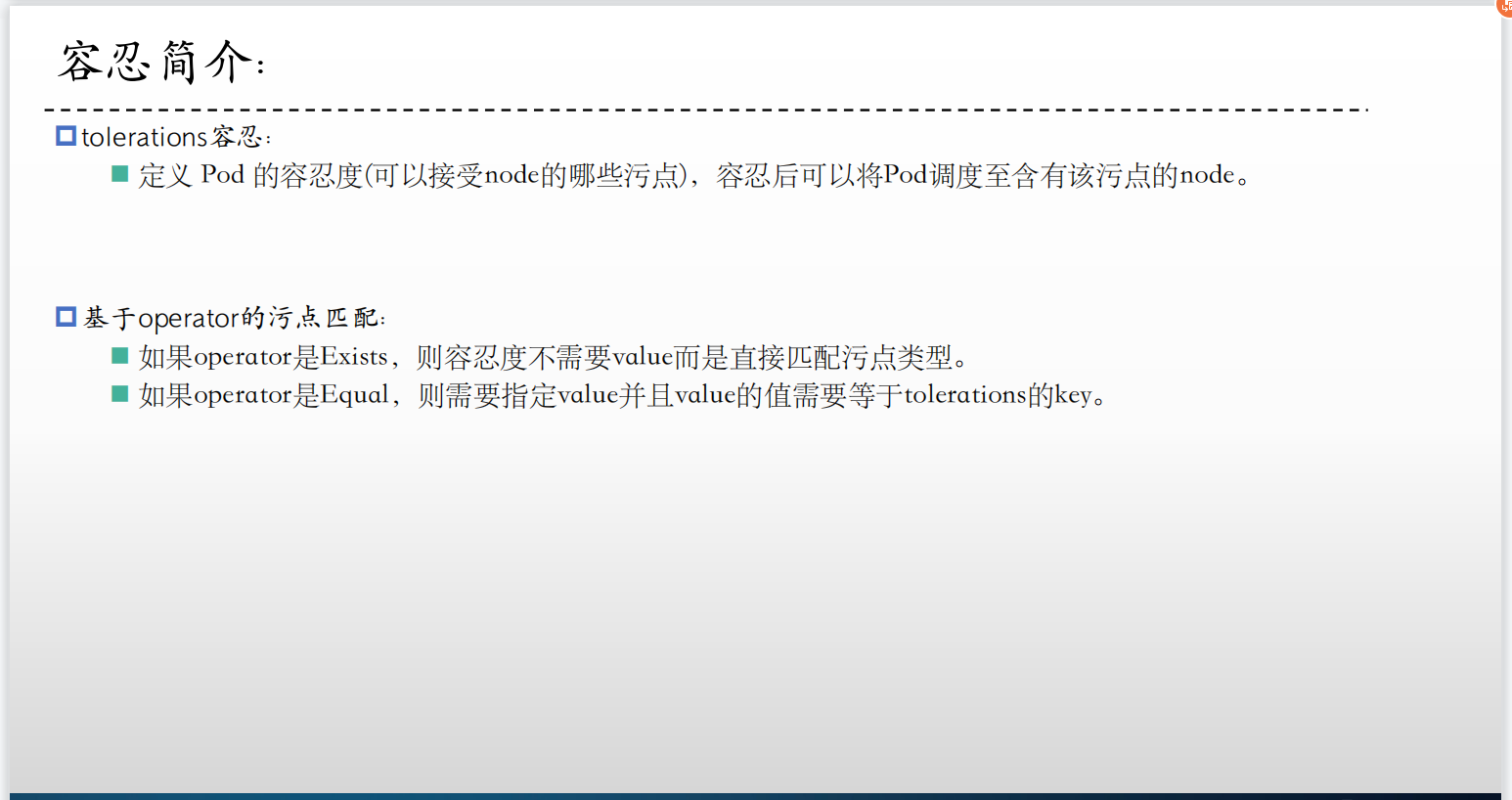
**污点(Taint)**是定义在节点之上的键值型属性数据,用于让节点有能力主动拒绝调度器将Pod调度运行到节点上,除非该Pod对象具有接纳节点污点的容忍度。**容忍度(tolerations)**则是定义在Pod对象上的键值型属性数据,用于配置该Pod可容忍的节点污点。
节点选择器(nodeSelector)和节点亲和性(nodeAffinity)两种调度方式都是通过在Pod对象上添加标签选择器来完成对特定类型节点标签的匹配,从而完成节点选择和绑定,相对而言,基于污点和容忍度的调度方式则是通过向节点添加污点信息来控制Pod对象的调度结果,从而给了节点控制何种Pod对象能够调度于其上的控制权。换句话说,节点亲和调度使得Pod对象被吸引到一类特定的节点,而污点的作用则相反,它为节点提供了排斥特定Pod对象的能力。
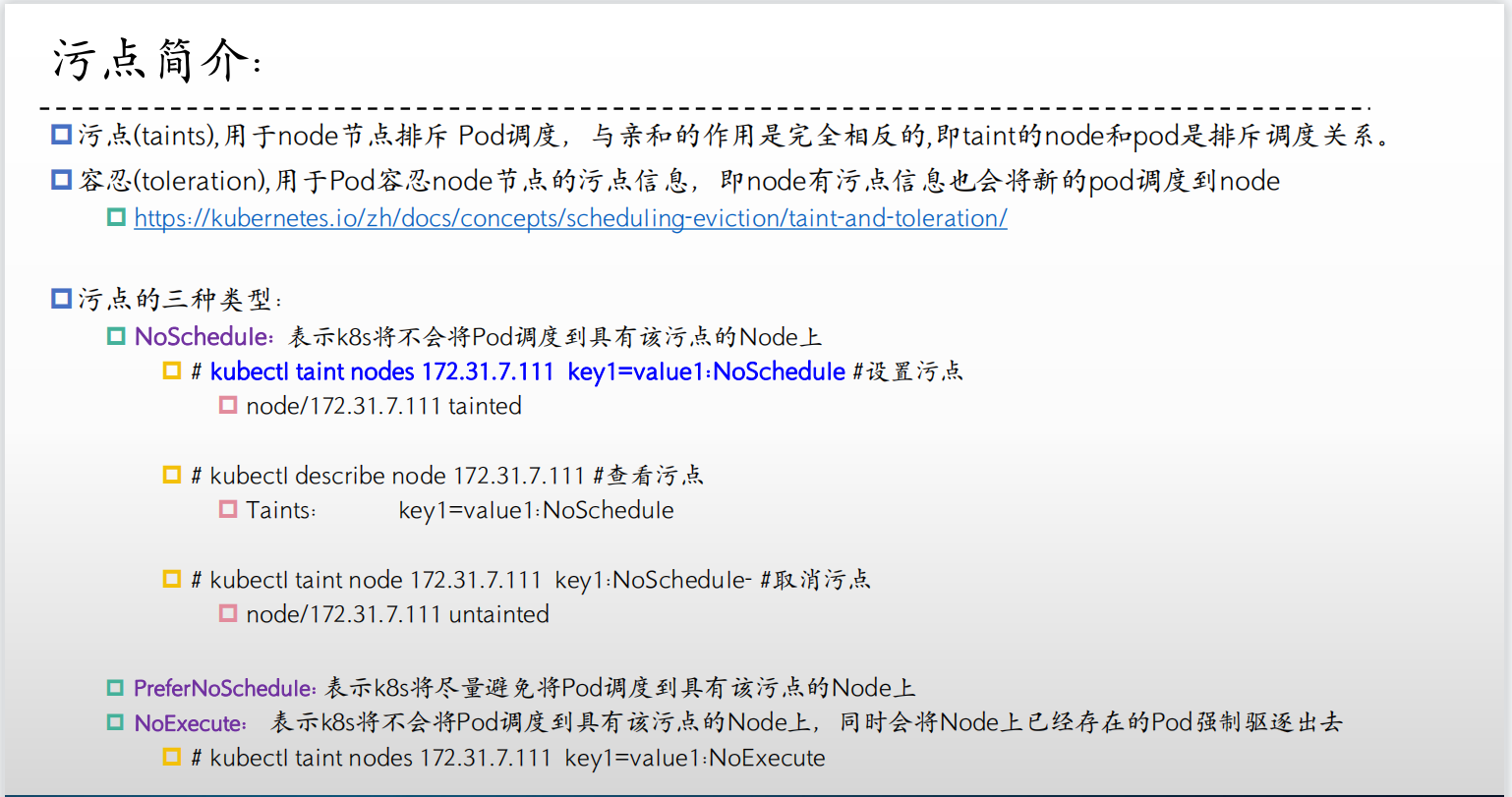
- NoSchedule:不能容忍此污点的Pod对象不可调度至当前节点,属于强制型约束关系,但添加污点对节点上现存的Pod对象不产生影响。
- PreferNoSchedule:NoSchedule的柔性约束版本,即调度器尽量确保不会将那些不能容忍此污点的Pod对象调度至当前节点,除非不存在其他任何能够容忍此污点的可用节点;添加该类效用的污点同样对节点上现存的Pod对象不产生影响。
- NoExecute:不能容忍此污点的新Pod对象不可调度至当前节点,属于强制型约束关系,而且节点上现存的Pod对象因节点污点变动或Pod容忍度变动而不再满足匹配条件时,Pod对象将会被驱逐。
# master 是不被调度的 SchedulingDisabled
root@k8s-deploy:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.0.110 Ready,SchedulingDisabled master 59d v1.24.8
192.168.0.111 Ready,SchedulingDisabled master 59d v1.24.8
192.168.0.112 Ready,SchedulingDisabled master 59d v1.24.8
192.168.0.113 Ready node 59d v1.24.8
192.168.0.114 Ready node 59d v1.24.8
192.168.0.115 Ready node 59d v1.24.8
# 取消 SchedulingDisabled
root@k8s-deploy:~# kubectl uncordon 192.168.0.110
node/192.168.0.110 uncordoned
root@k8s-deploy:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.0.110 Ready master 59d v1.24.8
192.168.0.111 Ready,SchedulingDisabled master 59d v1.24.8
192.168.0.112 Ready,SchedulingDisabled master 59d v1.24.8
192.168.0.113 Ready node 59d v1.24.8
192.168.0.114 Ready node 59d v1.24.8
192.168.0.115 Ready node 59d v1.24.8
# 再重新加上 SchedulingDisabled
root@k8s-deploy:~# kubectl cordon 192.168.0.110
node/192.168.0.110 cordoned
NoExecute:不会将 Pod 调度到具有该污点的 Node 上,而且会将 Node 上已存在的 Pod 强制驱逐出去,常用于紧急下线。
root@k8s-deploy:~# kubectl get pod -n magedu -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
mysql-0 2/2 Running 0 6d1h 10.200.36.119 192.168.0.113 <none> <none>
mysql-1 2/2 Running 14 (17m ago) 55m 10.200.36.85 192.168.0.113 <none> <none>
mysql-2 2/2 Running 1 (6d2h ago) 6d2h 10.200.169.148 192.168.0.114 <none> <none>
# 把113节点打上污点 NoExecute,驱逐113上面的Pod
root@k8s-deploy:~# kubectl taint node 192.168.0.113 key1=value1:NoExecute
node/192.168.0.113 tainted
# 查看发现113上面的Pod正在停止
root@k8s-deploy:~# kubectl get pod -n magedu -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
mysql-0 2/2 Terminating 0 6d1h 10.200.36.119 192.168.0.113 <none> <none>
mysql-1 2/2 Terminating 14 (18m ago) 56m 10.200.36.85 192.168.0.113 <none> <none>
mysql-2 2/2 Running 1 (6d2h ago) 6d2h 10.200.169.148 192.168.0.114 <none> <none>
# 然后在其他节点上重建了
root@k8s-deploy:~# kubectl get pod -n magedu -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
mysql-0 2/2 Running 0 32s 10.200.107.203 192.168.0.115 <none> <none>
mysql-1 2/2 Running 0 20s 10.200.107.205 192.168.0.115 <none> <none>
mysql-2 2/2 Running 1 (6d2h ago) 6d2h 10.200.169.148 192.168.0.114 <none> <none>
# 取消污点
root@k8s-deploy:~# kubectl taint node 192.168.0.113 key1:NoExecute-
node/192.168.0.113 untainted
# 类似drain驱逐
root@k8s-deploy:~# kubectl drain 192.168.0.113
3.1、容忍案例
节点打上污点信息
root@k8s-deploy:~# kubectl taint node 192.168.0.113 key1=value1:NoSchedule
node/192.168.0.113 tainted
root@k8s-deploy:~# kubectl describe node 192.168.0.113 | grep Taints
Taints: key1=value1:NoSchedule
测试对污点容忍和不容忍分别能否调度,以下示例表示 Pod 能够容忍键值对为 key1=value1 ,效用标识为 NoSchedule 的污点
root@k8s-deploy:/yaml/20220821/Affinit-case# vim case5.1-taint-tolerations.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app1-deployment-label
name: magedu-tomcat-app1-deployment
namespace: magedu
spec:
replicas: 5
selector:
matchLabels:
app: magedu-tomcat-app1-selector
template:
metadata:
labels:
app: magedu-tomcat-app1-selector
spec:
containers:
- name: magedu-tomcat-app1-container
#image: harbor.magedu.net/magedu/tomcat-app1:v7
image: tomcat:7.0.93-alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
protocol: TCP
name: http
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
---
kind: Service
apiVersion: v1
metadata:
labels:
app: magedu-tomcat-app1-service-label
name: magedu-tomcat-app1-service
namespace: magedu
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
#nodePort: 40003
selector:
app: magedu-tomcat-app1-selector

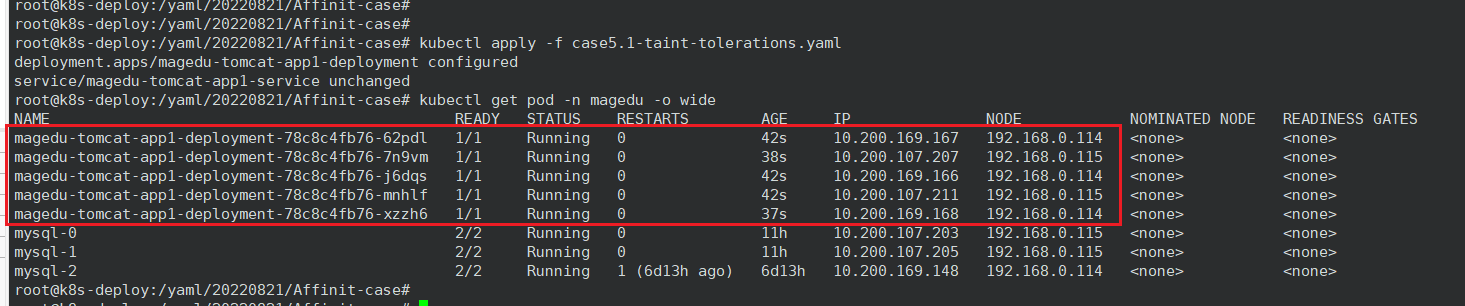
我们将容忍度修改为如下配置,发现 Pod 将不会被调度到113节点上
tolerations:
- key: "key1"
operator: "Equal"
value: "value2"
effect: "NoSchedule"
删除污点
root@k8s-deploy:/yaml/20220821/Affinit-case# kubectl taint node 192.168.0.113 key1:NoSchedule-
node/192.168.0.113 untainted
4、节点压力驱逐 | Kubernetes
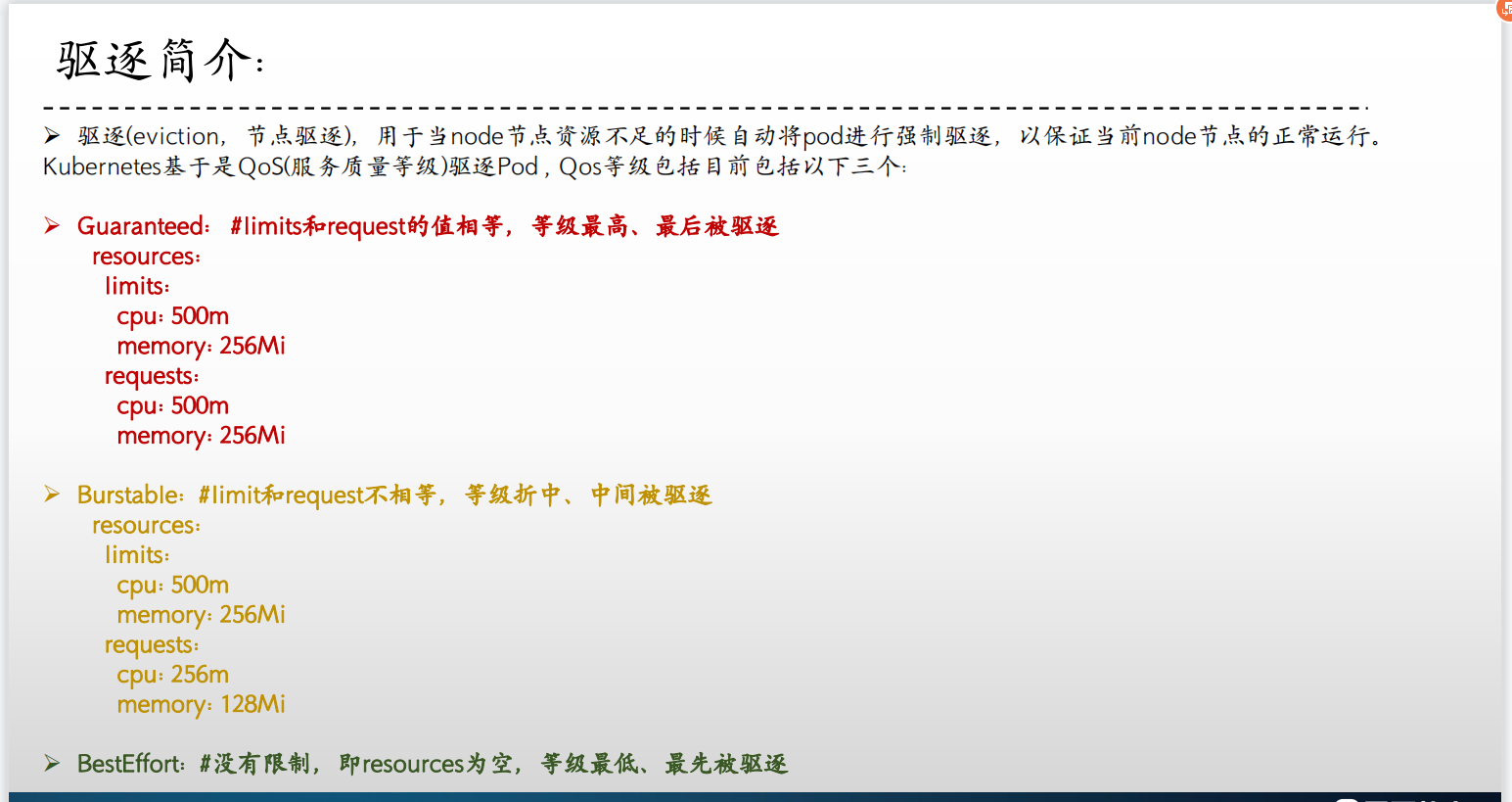
节点压力驱逐是 kubelet 主动终止 Pod 以回收节点上资源的过程。
kubelet 监控集群节点的内存、磁盘空间和文件系统的 inode 等资源。 当这些资源中的一个或者多个达到特定的消耗水平, kubelet 可以主动地使节点上一个或者多个 Pod 失效,以回收资源防止饥饿,以防止当前node节点资源无法正常分配而引发的OOM(OutOfMemory)。
在节点压力驱逐期间,kubelet 将所选 Pod 的 PodPhase 设置为 Failed。这将终止 Pod。
节点压力驱逐不同于 API 发起的驱逐。
kubelet 并不理会你配置的 PodDisruptionBudget 或者是 Pod 的 terminationGracePeriodSeconds。 如果你使用了软驱逐条件,kubelet 会考虑你所配置的 eviction-max-pod-grace-period。 如果你使用了硬驱逐条件,它使用 0s 宽限期来终止 Pod。
如果 Pod 是由替换失败 Pod 的工作负载资源 (例如 StatefulSet 或者 Deployment)管理, 则控制平面或 kube-controller-manager 会创建新的 Pod 来代替被驱逐的 Pod。
说明:
kubelet 在终止最终用户 Pod 之前会尝试回收节点级资源。 例如,它会在磁盘资源不足时删除未使用的容器镜像。
kubelet 使用各种参数来做出驱逐决定,如下所示:
- 驱逐信号
- 驱逐条件
- 监控间隔
4.1、驱逐信号
驱逐信号是特定资源在特定时间点的当前状态。 kubelet 使用驱逐信号,通过将信号与驱逐条件进行比较来做出驱逐决定, 驱逐条件是节点上应该可用资源的最小量。
kubelet 使用以下驱逐信号:
| 驱逐信号 | 描述 |
|---|---|
memory.available | node节点可用内存,默认 <100Mi |
nodefs.available | nodefs的可用空间,默认<10% |
nodefs.inodesFree | nodefs的可用inode,默认<5% |
imagefs.available | imagefs的磁盘空间可用百分比,默认<15% |
imagefs.inodesFree | imagefs的inode可用百分比 |
pid.available | 可用pid百分比 |
kubelet 支持以下文件系统分区:
nodefs:nodefs是节点的主要文件系统,用于保存本地磁盘卷、emptyDir、日志存储等数据,默认是/var/lib/kubelet/,或者是通过kubelet通过--root-dir所指定的磁盘挂载目录。imagefs:可选文件系统,供容器运行时存储容器镜像和容器可写层。
示例
evictionHard:
imagefs.inodesFree: 5%
imagefs.available: 15%
memory.available: 300Mi
nodefs.available: 10%
nodefs.inodesFree: 5%
pid.available: 5%
4.2、驱逐条件
你可以为 kubelet 指定自定义驱逐条件,以便在作出驱逐决定时使用。
驱逐条件的形式为 [eviction-signal][operator][quantity],其中:
-
eviction-signal是要使用的驱逐信号。kubelet捕获node节点驱逐触发信号,进行判断是否驱逐,比如通过cgroupfs获取memory.available的值来进行下一步匹配。
-
operator是你想要的关系运算符, 比如<(小于)。通过操作符对比条件是否匹配资源量是否触发驱逐。 -
quantity是驱逐条件数量,例如1Gi。quantity的值必须与 Kubernetes 使用的数量表示相匹配。 你可以使用文字值或百分比(%)。
例如,如果一个节点的总内存为 10Gi 并且你希望在可用内存低于 1Gi 时触发驱逐, 则可以将驱逐条件定义为 memory.available<10% 或 memory.available< 1G。 你不能同时使用二者。
你可以配置软和硬驱逐条件。

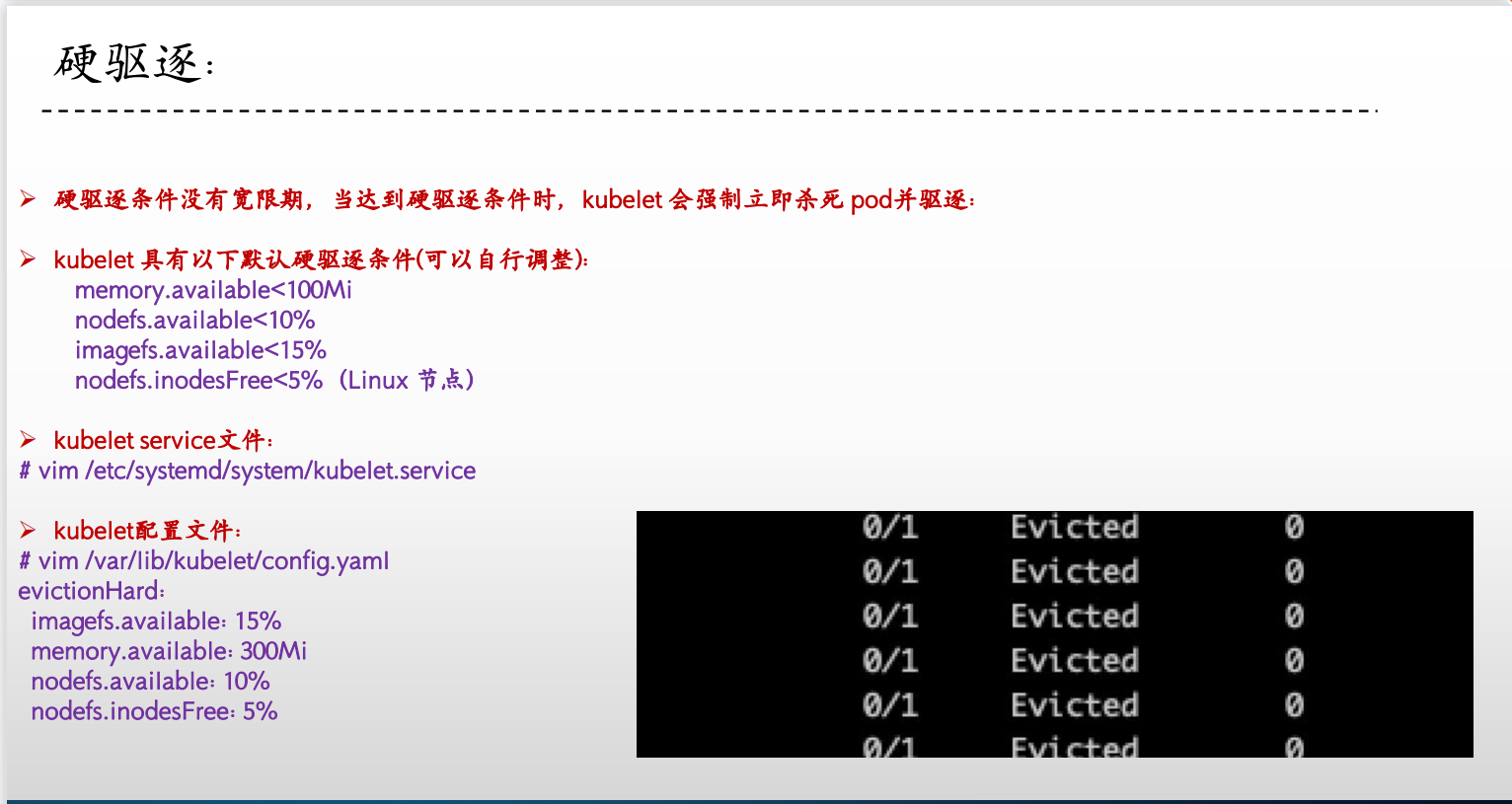
root@node01:~# vim /var/lib/kubelet/config.yaml
29 evictionHard:
30 imagefs.available: 15%
31 memory.available: 300Mi
32 nodefs.available: 10%
33 nodefs.inodesFree: 5%
三、搭建ELK及kafka日志收集环境(daemonset、sidecar)
1、日志收集的目的

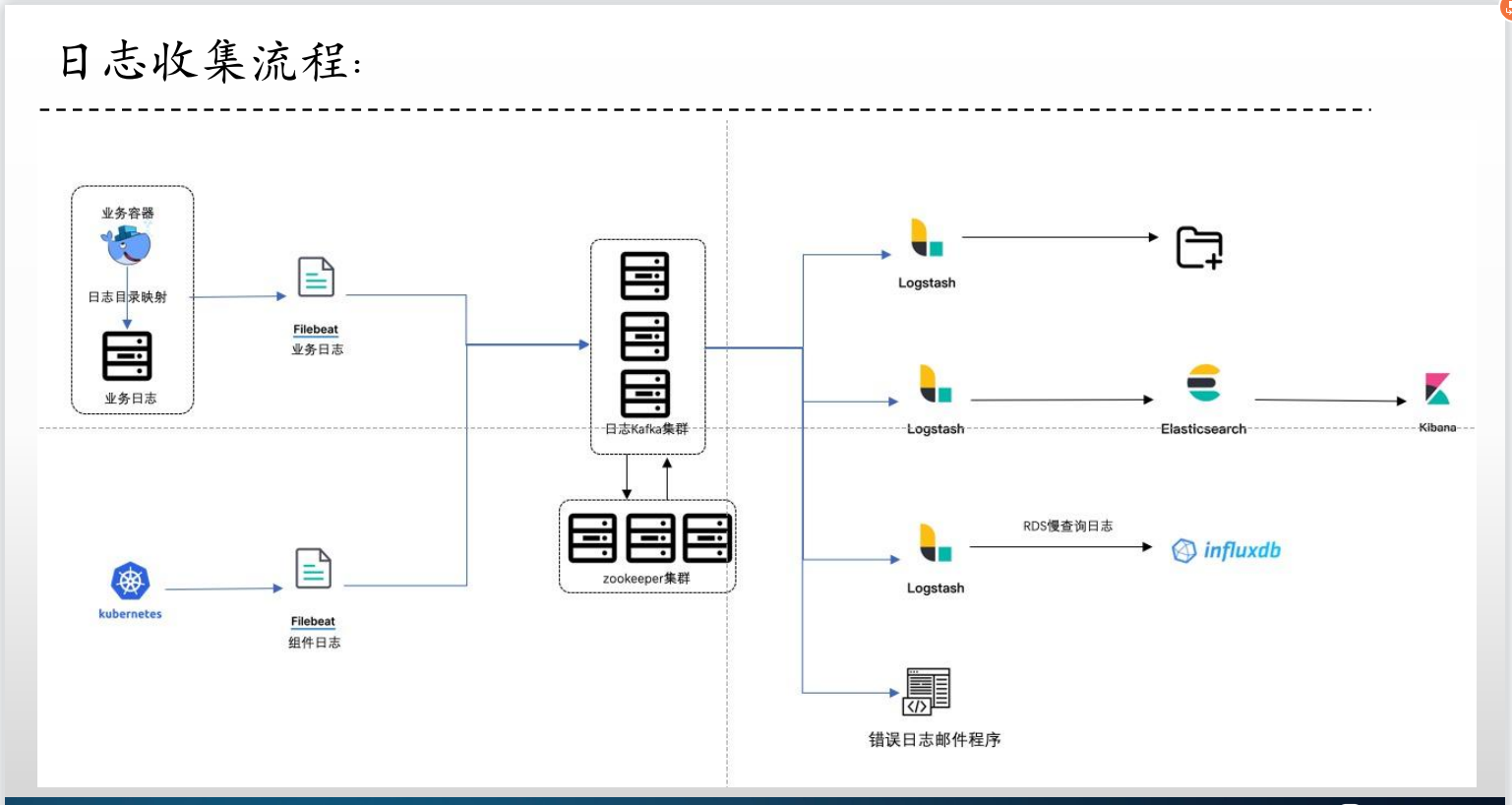
2、日志收集流程
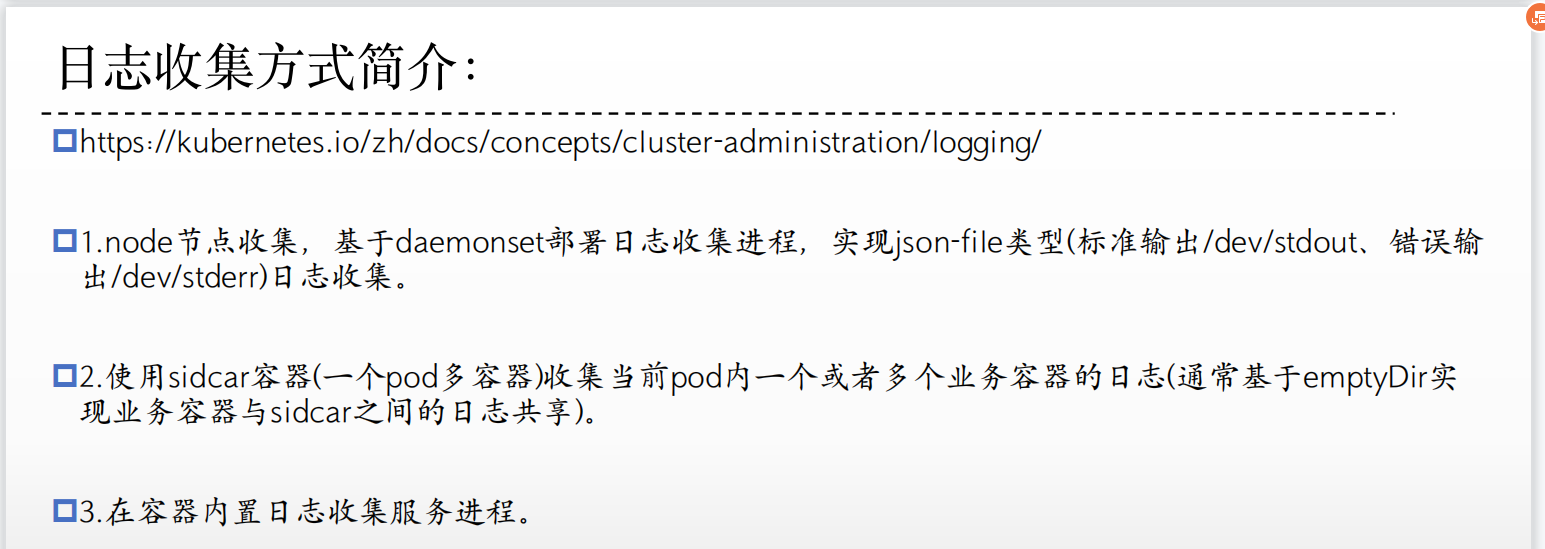
3、日志收集方式
4、ELK及kafka日志收集环境
1、安装 Elasticsearch
官方帮助文档 https://www.elastic.co/guide/en/enterprise-search/index.html
清华大学镜像https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/apt/pool/main/e/elasticsearch/
每个节点下载镜像并安装
root@ELK01:~# wget https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/apt/pool/main/e/elasticsearch/elasticsearch-7.12.1-amd64.deb
root@ELK01:~# dpkg -i elasticsearch-7.12.1-amd64.deb
每个节点修改 elasticsearch 主配置文件
root@ELK01:~# vim /etc/elasticsearch/elasticsearch.yml
# 修改集群名称
17 cluster.name: magedu-cluster1
# 修改节点名称,各节点都不一样
23 node.name: node-1
# elasticsearch 数据路径和日志路径,可将其挂载到存储服务器上
33 path.data: /var/lib/elasticsearch
37 path.logs: /var/log/elasticsearch
# elasticsearch在启动过程中就直接占用宿主机内存,占用大小在 /etc/elasticsearch/jvm.options 里修改 “-Xms4g”
43 #bootstrap.memory_lock: true
# 修改监听地址和端口,地址可以是本机IP或者0.0.0.0
56 network.host: 192.168.0.122
61 http.port: 9200
# 发现,传递初始主机列表以在此节点启动时执行发现
70 discovery.seed_hosts: ["192.168.0.122", "192.168.0.123","192.168.0.124"]
# 哪些节点可以选举为 master
74 cluster.initial_master_nodes: ["192.168.0.122", "192.168.0.123","192.168.0.124"]
# 删除索引时需要显式完整名字,拒绝模糊匹配防止误删除
82 action.destructive_requires_name: true
设置开机启动
root@ELK01:~# systemctl restart elasticsearch.service
root@ELK01:~# systemctl enable elasticsearch.service
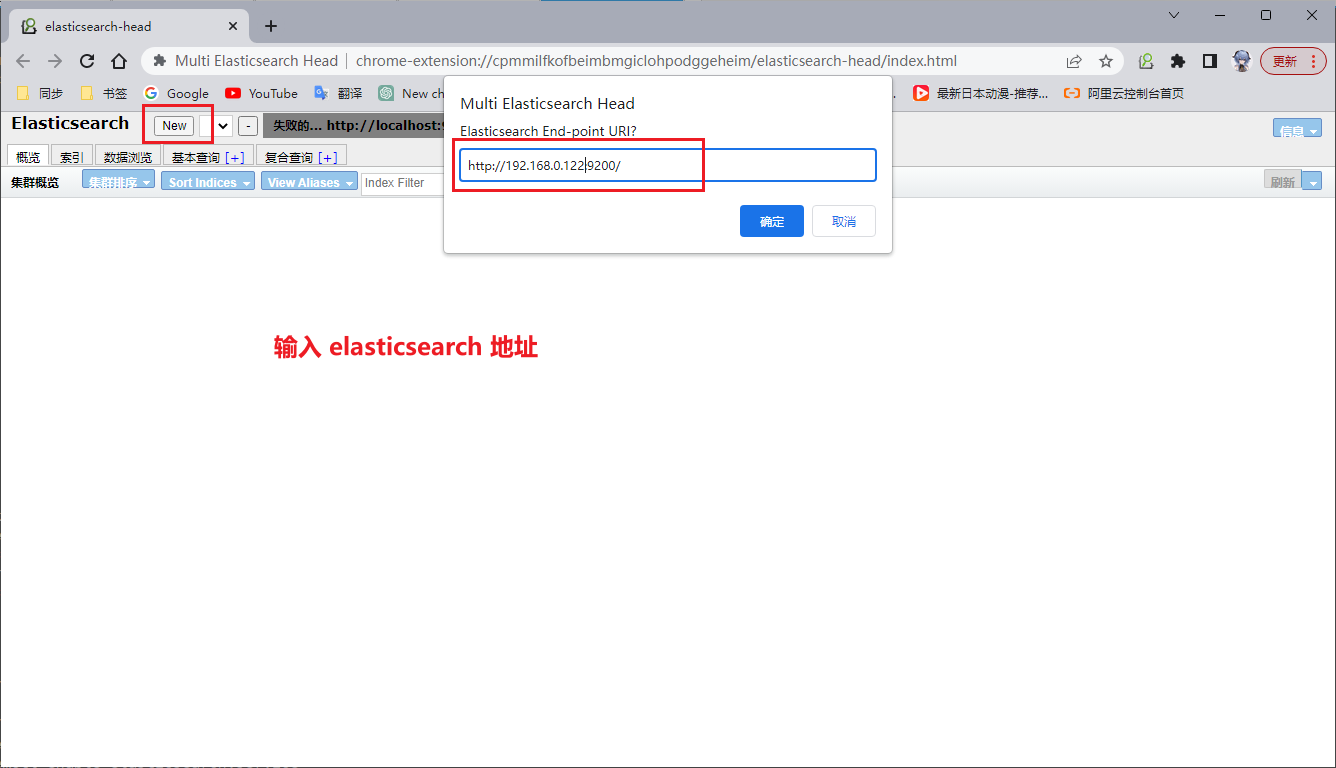
在浏览器安装Multi Elasticsearch Head插件
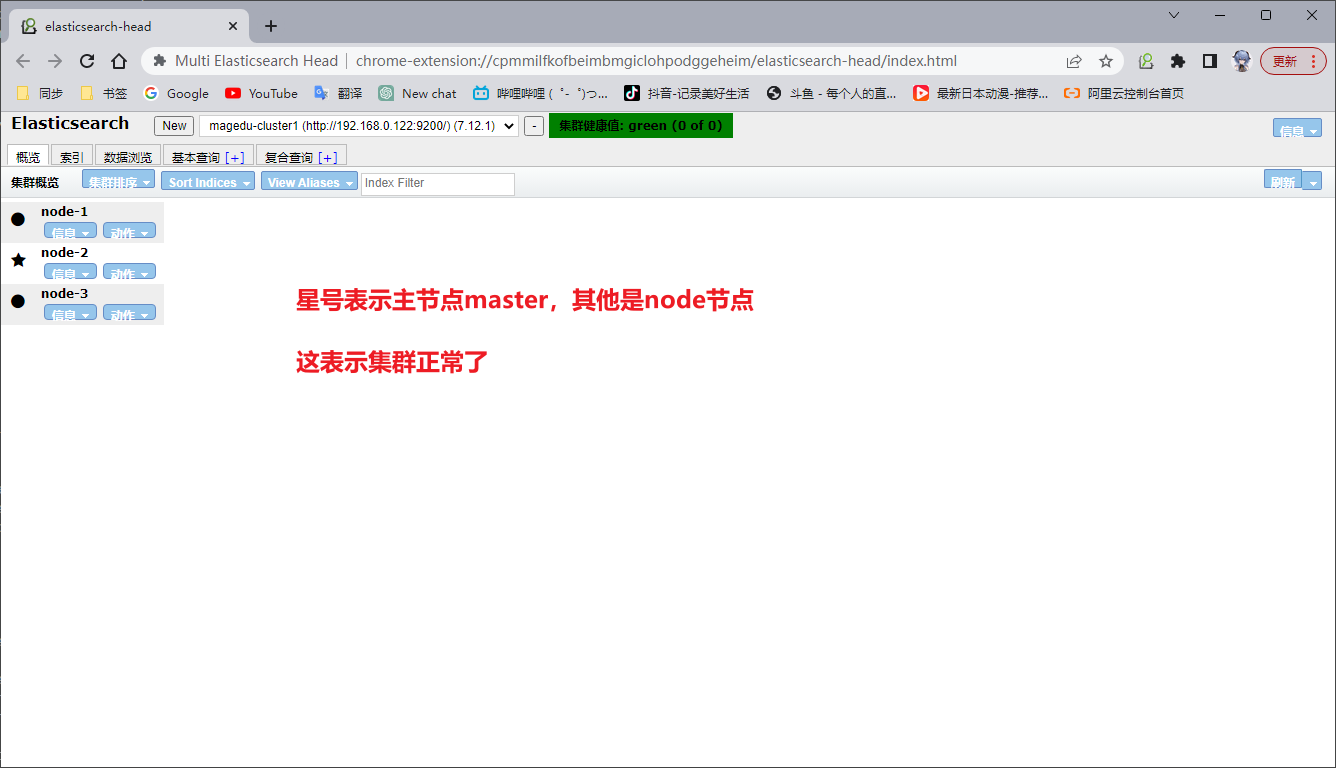
2、安装 kibana
单独一台服务器下载并安装,也可以和 Elasticsearch 装在一起
root@ELK01:~# wget https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/apt/pool/main/k/kibana/kibana-7.12.1-amd64.deb
root@ELK01:~# dpkg -i kibana-7.12.1-amd64.deb
编制主配置文件
root@ELK01:~# vim /etc/kibana/kibana.yml
# 修改监听端口
2 server.port: 5601
# 修改监听地址,可以是本机地址也可以是0.0.0.0
7 server.host: "192.168.0.122"
# 修改 elasticsearch 地址,可以是任一节点的地址
32 elasticsearch.hosts: ["http://192.168.0.123:9200"]
# 修改语言
111 i18n.locale: "zh-CN"
设置开机启动
root@ELK01:~# systemctl restart kibana.service
root@ELK01:~# systemctl enable kibana.service
# 查看是否监听端口
root@ELK01:~# ss -anptl | grep 5601
LISTEN 0 511 192.168.0.122:5601 0.0.0.0:* users:(("node",pid=5188,fd=42))
浏览器访问
kibana 起来后会在 elasticsearch 创建自己的隐藏索引
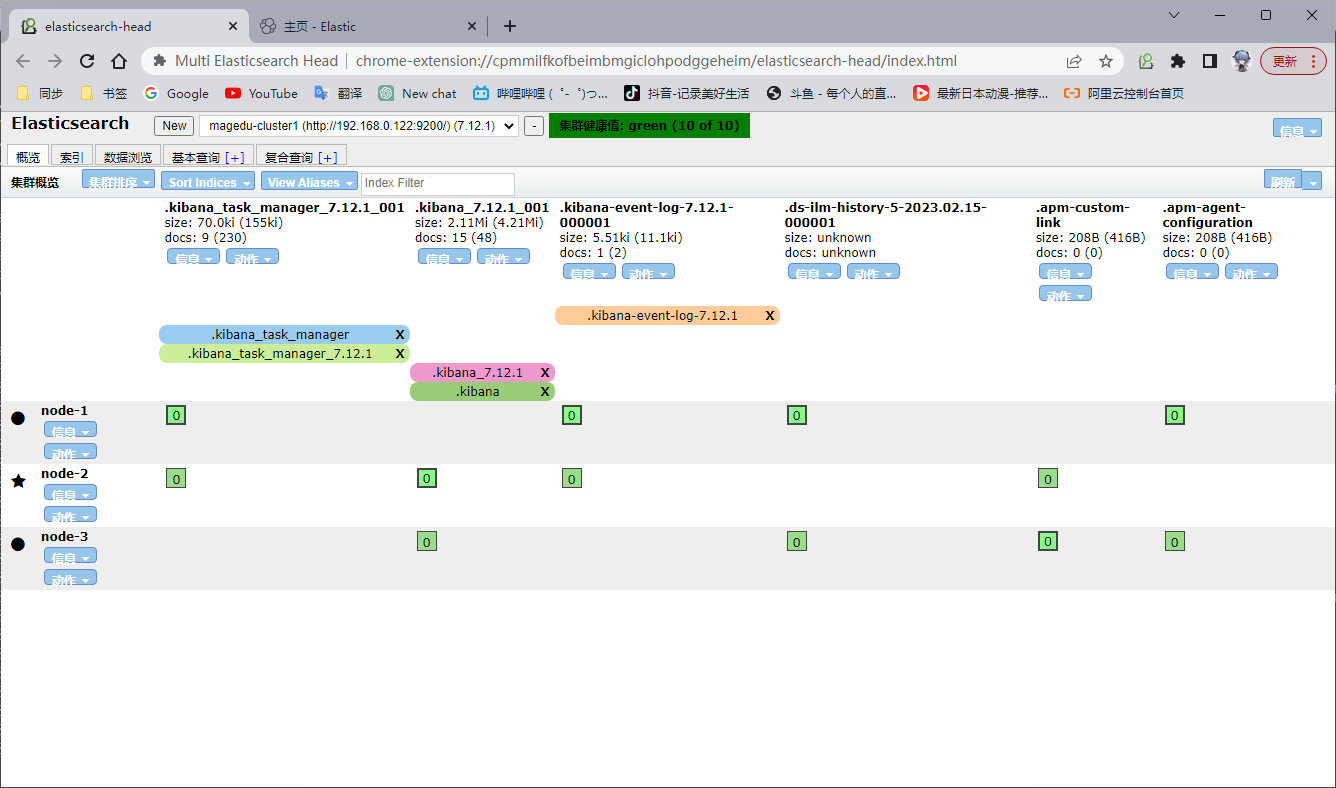
3、安装 zookeeper
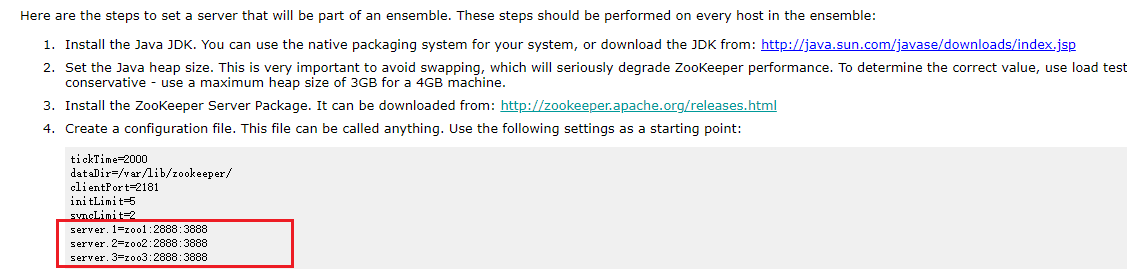
官网地址https://zookeeper.apache.org/releases.html
zookeeper依赖环境https://zookeeper.apache.org/doc/r3.6.4/zookeeperAdmin.html#sc_systemReq
更新镜像源,使用阿里云的ubuntu镜像_ubuntu下载地址_ubuntu安装教程-阿里巴巴开源镜像站 (aliyun.com)
所有节点安装Java环境
# 更新镜像源
root@zookeeper01:~# apt update
# 安装java8或者java11
root@zookeeper01:~# apt install openjdk-8-jdk -y
root@zookeeper01:~# java -version
openjdk version "1.8.0_352"
OpenJDK Runtime Environment (build 1.8.0_352-8u352-ga-1~20.04-b08)
OpenJDK 64-Bit Server VM (build 25.352-b08, mixed mode)
下载和安装 zookeeper
root@zookeeper01:~# mkdir /apps
root@zookeeper01:/apps# wget https://dlcdn.apache.org/zookeeper/zookeeper-3.6.4/apache-zookeeper-3.6.4-bin.tar.gz
# 解压
root@zookeeper01:/apps# tar xf apache-zookeeper-3.6.3-bin.tar.gz
root@zookeeper01:/apps# ln -sv apache-zookeeper-3.6.3-bin /apps/zookeeper
'/apps/zookeeper' -> 'apache-zookeeper-3.6.3-bin'
root@zookeeper01:/apps# cd /apps/zookeeper
# 进入 conf/ 目录,里面有三个配置文件模板。zoo.cfg 是主配置文件
root@zookeeper01:/apps/zookeeper# cd conf/
root@zookeeper01:/apps/zookeeper/conf# cp zoo_sample.cfg zoo.cfg
修改主配置文件 zoo.cfg
root@zookeeper03:/apps/zookeeper/conf# vim zoo.cfg
# 修改数据目录
12 dataDir=/data/zookeeper
# 在末尾追加集群配置
37 server.1=192.168.0.125:2888:3888
38 server.2=192.168.0.126:2888:3888
39 server.3=192.168.0.127:2888:3888
根据前面配置文件里的集群信息创建 id 文件
# 创建数据目录
root@zookeeper01:/apps/zookeeper/conf# mkdir -p /data/zookeeper
# node1节点
root@zookeeper01:/apps/zookeeper/conf# echo 1 > /data/zookeeper/myid
# node2节点
root@zookeeper02:/apps/zookeeper/conf# echo 2 > /data/zookeeper/myid
# node3节点
root@zookeeper03:/apps/zookeeper/conf# echo 3 > /data/zookeeper/myid
# 启动集群
root@zookeeper01:/apps/zookeeper/conf# /apps/zookeeper/bin/zkServer.sh start
# 依次查看集群状态,发现本例中node1和node2节点是 follower,node3节点是 master
root@zookeeper01:/apps/zookeeper/conf# /apps/zookeeper/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /apps/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
4、安装 kafka
下载并解压,这里和 zookeeper 安装在一起
root@zookeeper01:/apps# wget https://dlcdn.apache.org/kafka/3.4.0/kafka_2.13-3.4.0.tgz
root@zookeeper03:/apps# ln -sv kafka_2.13-3.1.1 /apps/kafka
root@zookeeper03:/apps# cd /apps/kafka
修改主配置文件 /apps/kafka/config/server.properties
root@zookeeper01:/apps/kafka/config# vim server.properties
# 修改节点id,每个节点都不一样。本例分别为125、126、127
21 broker.id=125
# 修改监听地址,写本机IP
31 listeners=PLAINTEXT://192.168.0.125:9092
# 修改kafka数据存放目录
60 log.dirs=/data/kafka-logs
# 修改zookeeper连接地址,默认连接本机地址的2181端口
123 zookeeper.connect=192.168.0.125:2181,192.168.0.126:2181,192.168.0.127:2181
以 daemon 方式启动 kafka
root@zookeeper01:/apps/kafka/config# /apps/kafka/bin/kafka-server-start.sh -daemon /apps/kafka/config/server.properties
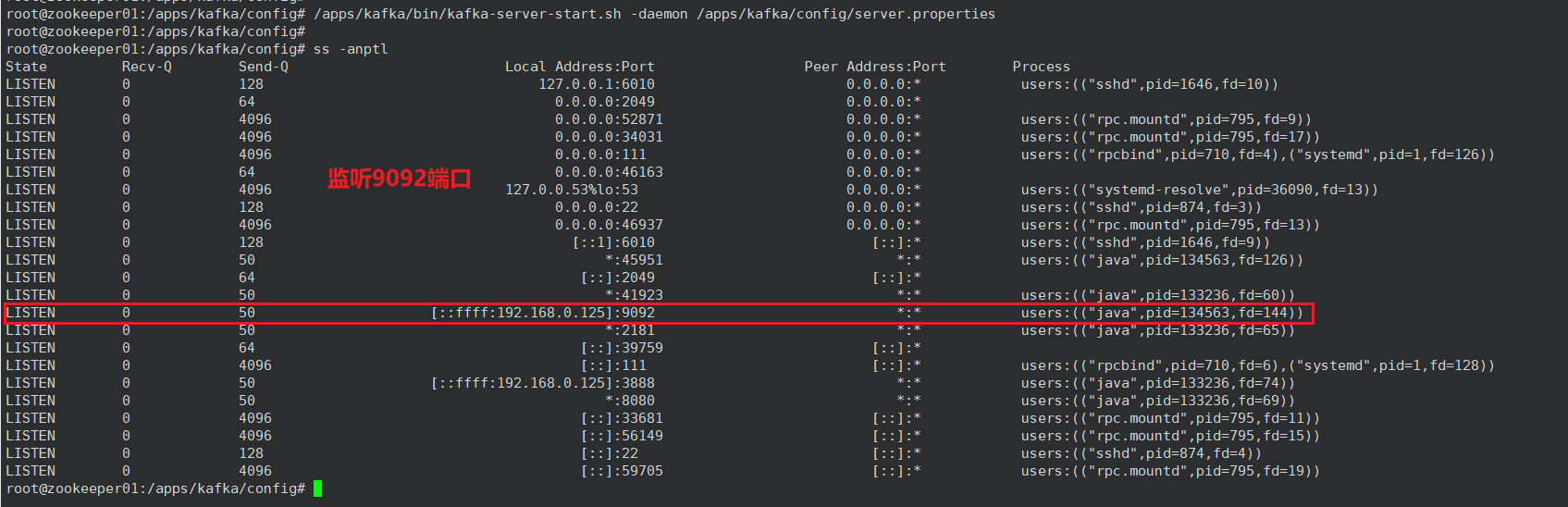
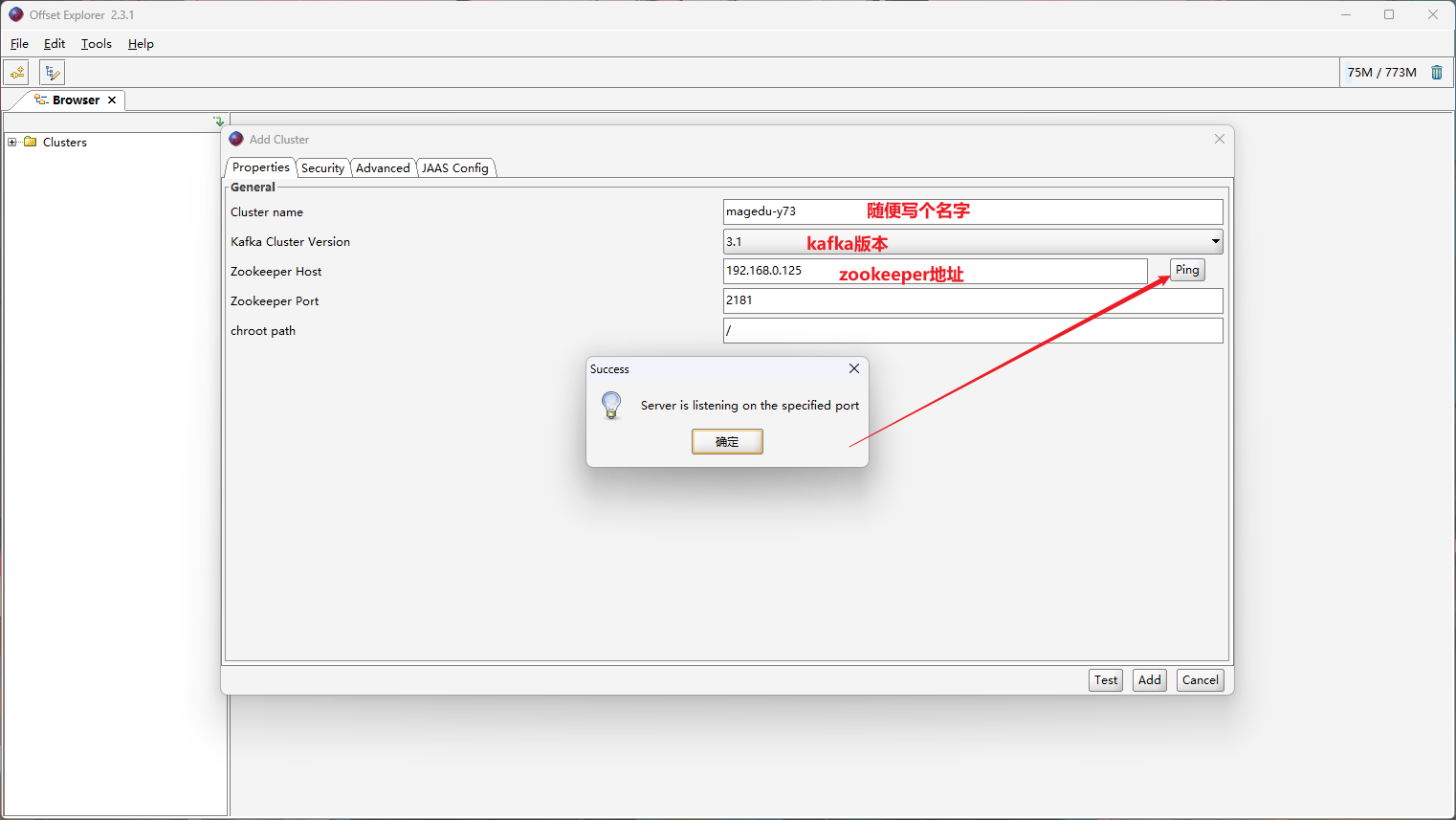
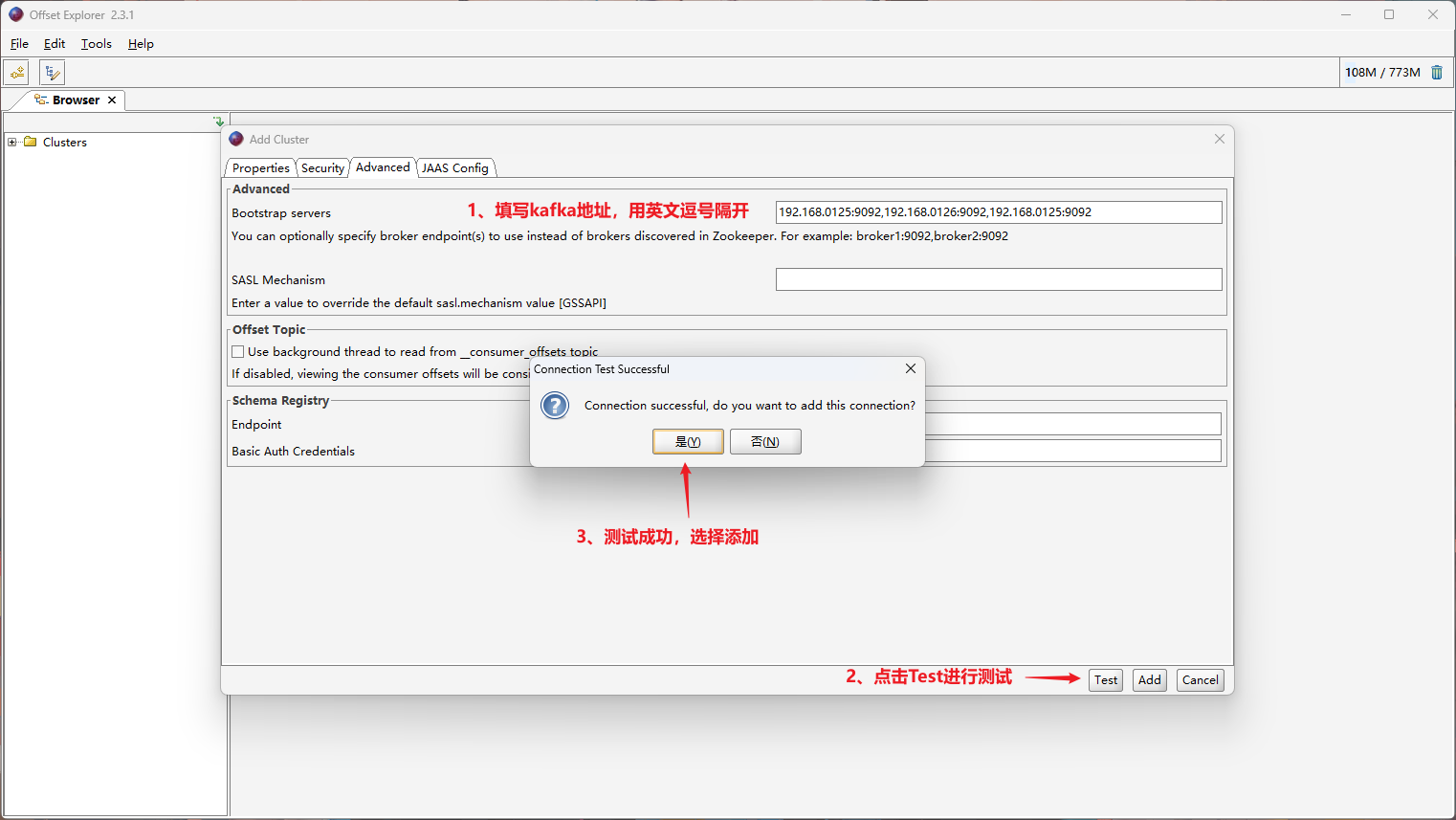
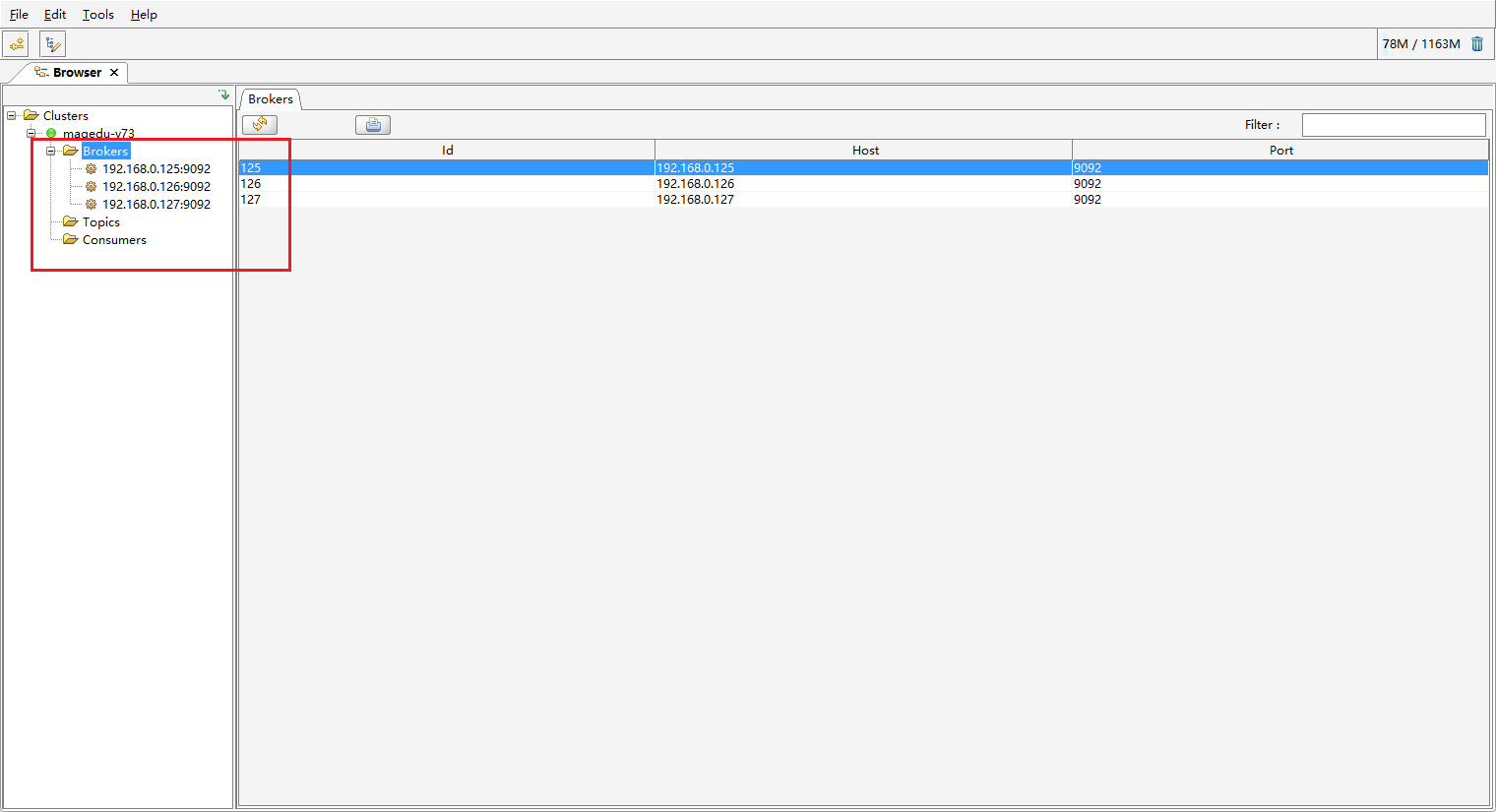
使用 kafka 客户端验证,下载地址https://www.kafkatool.com/download2/offsetexplorer_64bit.exe
5、示例一:daemonset收集日志

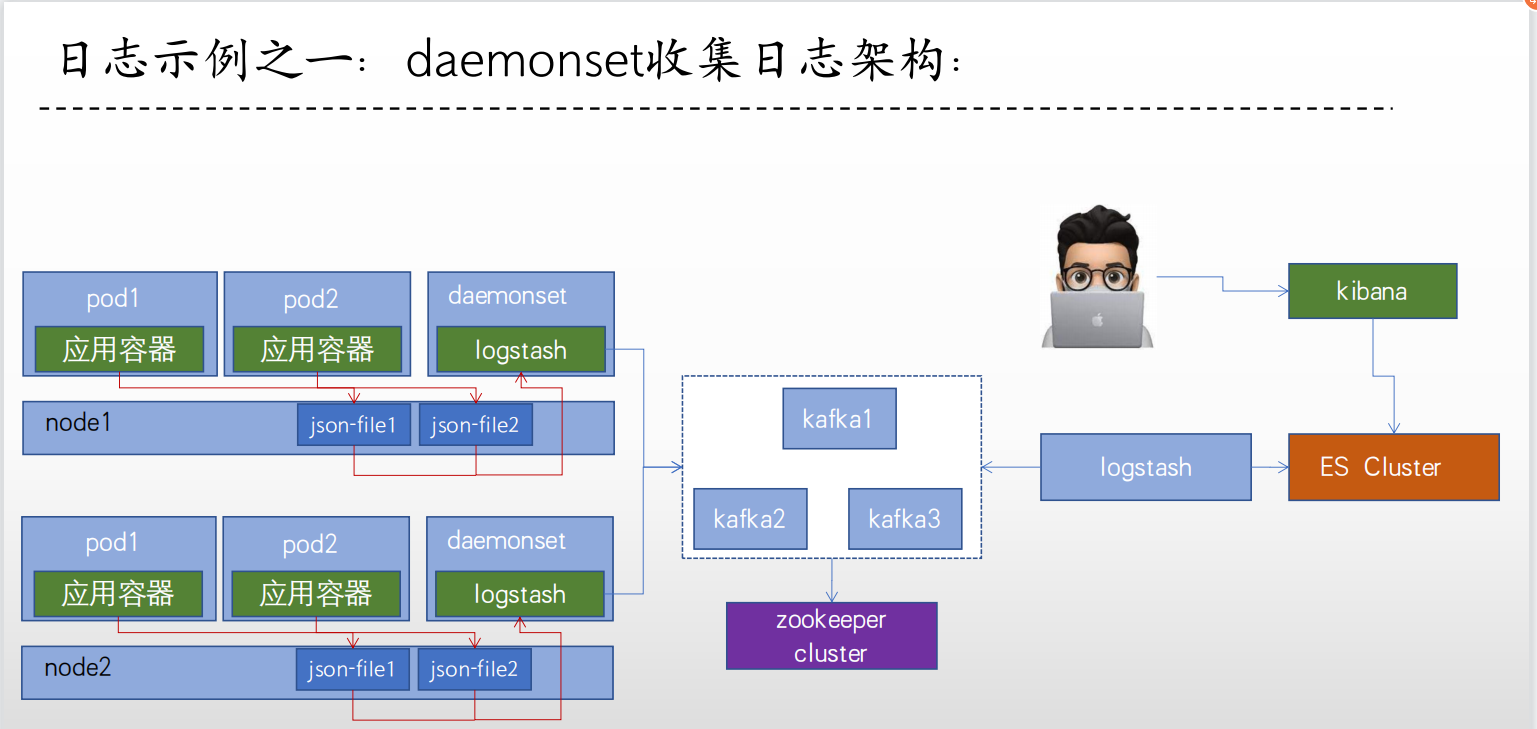
1、安装 logsatsh
1、镜像准备
logstash.yml:指定监听地址
http.host: "0.0.0.0"
#xpack.monitoring.elasticsearch.hosts: [ "http://elasticsearch:9200" ]
logstash.conf:用来配置日志收集选项,由于使用的是 daemonset ,所以日志实际上宿主机的
input {
file {
#path => "/var/lib/docker/containers/*/*-json.log" # 如果使用的运行时是docker,那么日志在宿主机这个路径
path => "/var/log/pods/*/*/*.log" # 如果使用的运行时是containerd,那么日志在宿主机这个路径
start_position => "beginning" # logstash启动后,如果日志文件已经存在且有数据,那么之前的日志也会收集。默认是end:logstash起来之后新产生的日志才会收集
type => "jsonfile-daemonset-applog"
}
file {
path => "/var/log/*.log" # 宿主机本身的系统日志也收集
start_position => "beginning"
type => "jsonfile-daemonset-syslog"
}
}
output {
if [type] == "jsonfile-daemonset-applog" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384 #logstash每次向ES传输的数据量大小,单位为字节
codec => "${CODEC}"
} }
if [type] == "jsonfile-daemonset-syslog" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384
codec => "${CODEC}" #系统日志不是json格式
}}
}
Dockerfile
FROM logstash:7.12.1
USER root
WORKDIR /usr/share/logstash
#RUN rm -rf config/logstash-sample.conf
ADD logstash.yml /usr/share/logstash/config/logstash.yml
ADD logstash.conf /usr/share/logstash/pipeline/logstash.conf
build-commond.sh
#!/bin/bash
docker build -t y73.harbor.com/y73/logstash:v7.12.1-json-file-log-v1 .
docker push y73.harbor.com/y73/logstash:v7.12.1-json-file-log-v1
#nerdctl build -t y73.harbor.com/y73/logstash:v7.12.1-json-file-log-v1 .
#nerdctl push y73.harbor.com/y73/logstash:v7.12.1-json-file-log-v1
执行构建脚
root@k8s-deploy:/yaml/20220821/ELK cases/1.daemonset-logstash/1.logstash-image-Dockerfile# chmod a+x *.sh
root@k8s-deploy:/yaml/20220821/ELK cases/1.daemonset-logstash/1.logstash-image-Dockerfile# ./build-commond.sh
2、部署 logsatsh Pod
使用 DaemonSet 控制器部署 ,这样每个节点都会有一个 Pod ,可以搜集每个节点的日志。
root@k8s-deploy:/yaml/20220821/ELK cases/1.daemonset-logstash# vim 2.DaemonSet-logstash.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: logstash-elasticsearch
namespace: kube-system
labels:
k8s-app: logstash-logging
spec:
selector:
matchLabels:
name: logstash-elasticsearch
template:
metadata:
labels:
name: logstash-elasticsearch
spec:
tolerations:
# this toleration is to have the daemonset runnable on master nodes
# remove it if your masters can't run pods
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: logstash-elasticsearch
image: y73.harbor.com/y73/logstash:v7.12.1-json-file-log-v1
env:
- name: "KAFKA_SERVER" # kafka地址
value: "192.168.0.125:9092,192.168.0.126:9092,192.168.0.127:9092"
- name: "TOPIC_ID"
value: "jsonfile-log-topic"
- name: "CODEC"
value: "json"
# resources:
# limits:
# cpu: 1000m
# memory: 1024Mi
# requests:
# cpu: 500m
# memory: 1024Mi
volumeMounts:
- name: varlog #定义宿主机系统日志挂载路径
mountPath: /var/log #宿主机系统日志挂载点
- name: varlibdockercontainers #定义容器日志挂载路径,和logstash配置文件中的收集路径保持一致
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log #宿主机系统日志
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers #docker的宿主机日志路径
path: /var/log/pods #containerd的宿主机日志路径
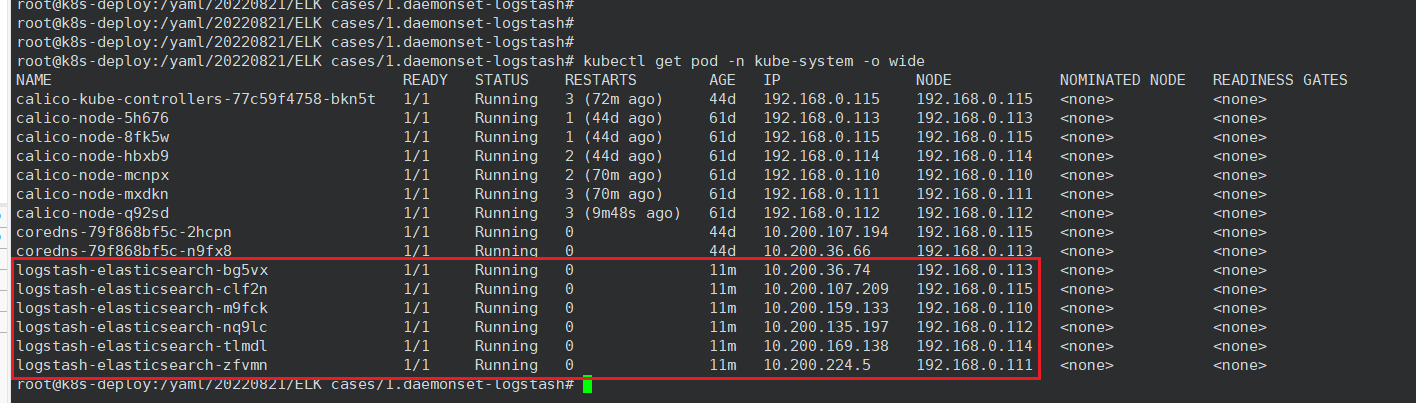
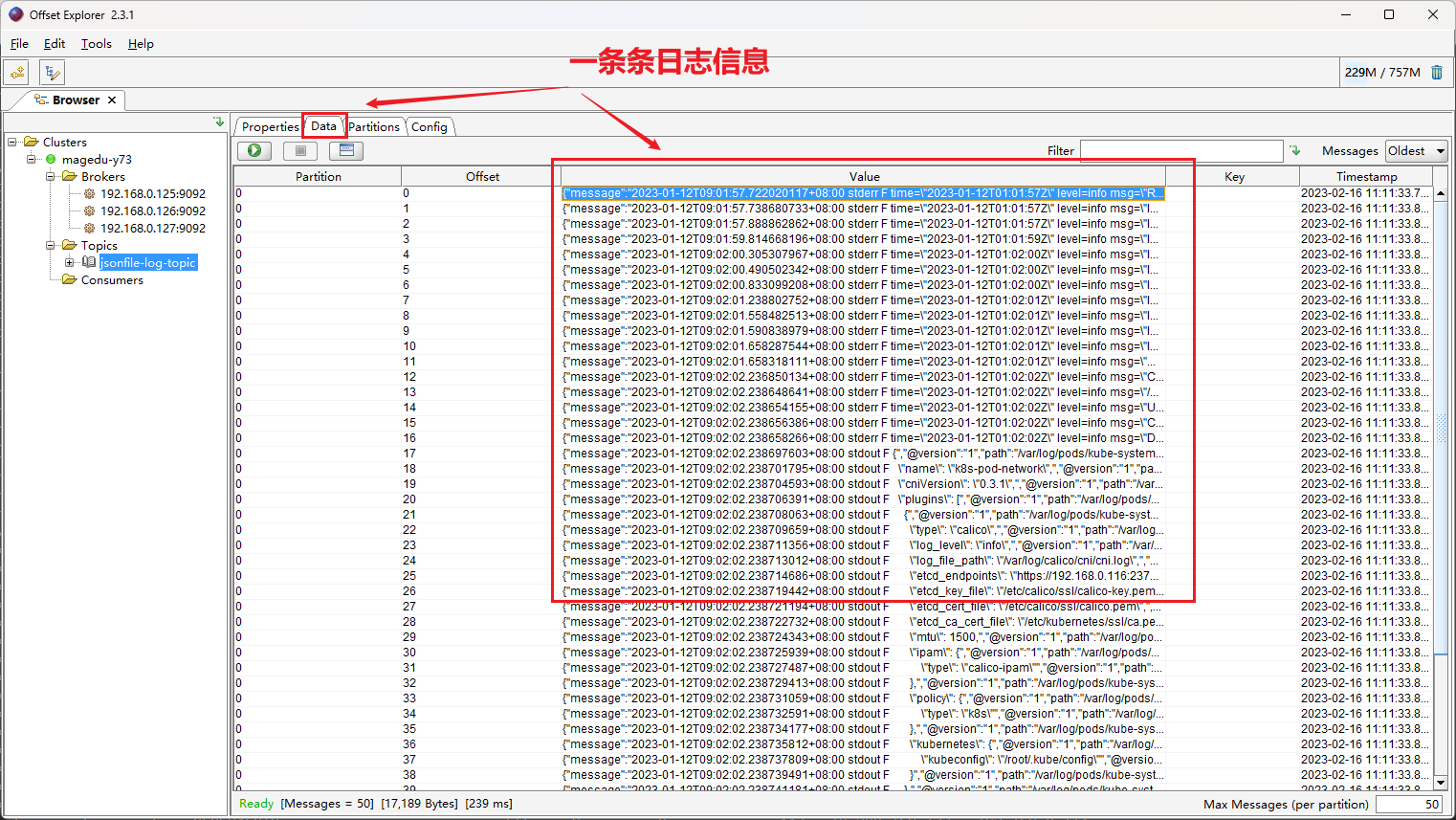
3、kafka 客户端验证
部署 logsatsh Pod 之后,在 kafka 客户端进行验证
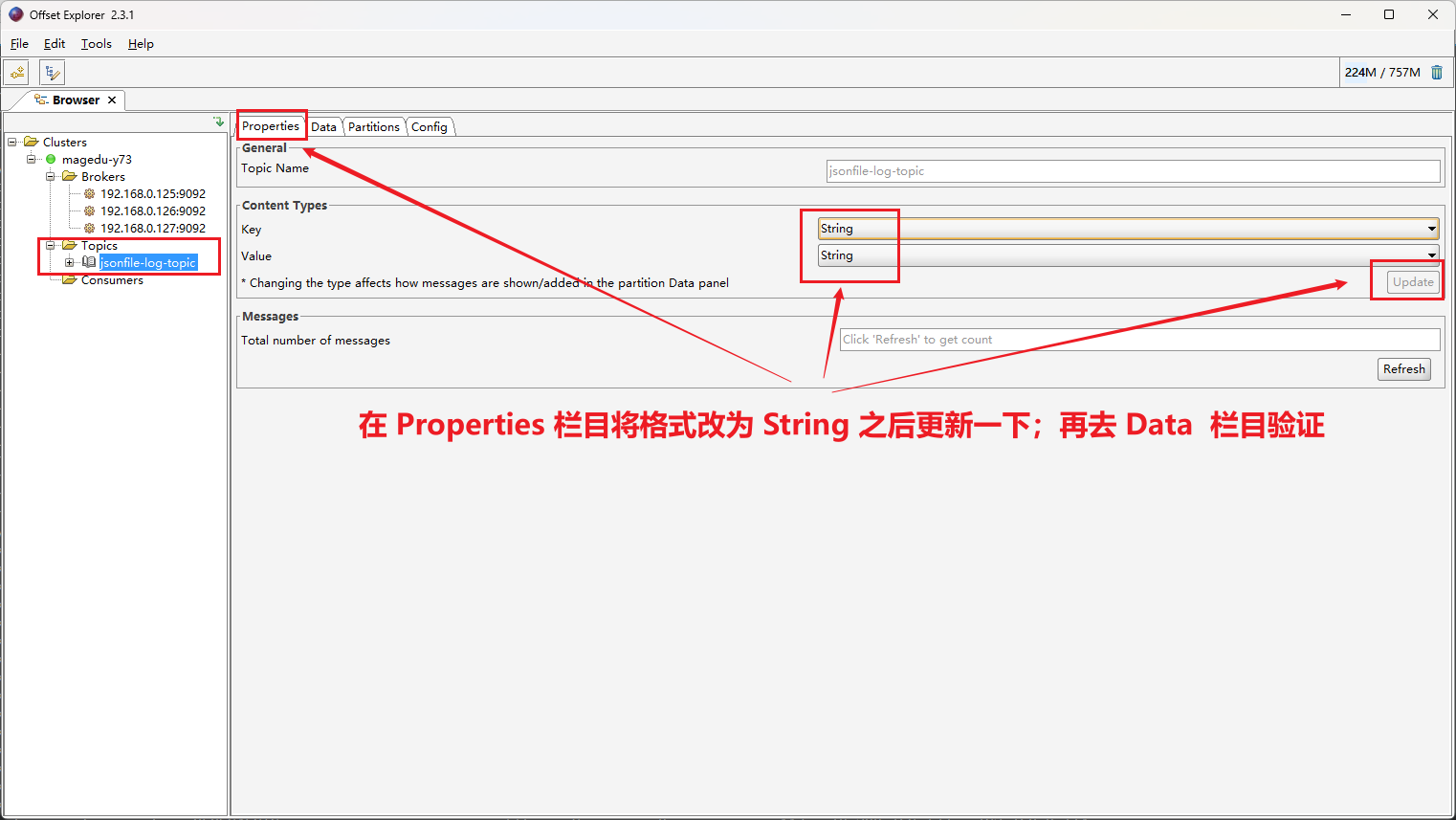
4、安装 logsatsh
那么如何将 kafka 的日志取出来传给 Elasticsearch?修改 logsatsh 配置文件,该文件定义了 logsatsh 如何消费日志到 ES 。
root@k8s-deploy:/yaml/20220821/ELK cases/1.daemonset-logstash# vim 3.logsatsh-daemonset-jsonfile-kafka-to-es.conf
input { # input 插件,来自 kafka
kafka {
bootstrap_servers => "192.168.0.125:9092,192.168.0.126:9092,192.168.0.127:9092" # kafka 地址
topics => ["jsonfile-log-topic"]
codec => "json" # 编码。由于日志本来就是json格式的,所以要用json给它解码
}
}
# app1-access-log:业务日志
# jsonfile-daemonset-syslog:系统日志
# 如果是业务日志,就把日志写进elasticsearch的这个文件jsonfile-daemonset-applog-%{+YYYY.MM.dd}
# 如果是系统日志,就把日志写进elasticsearch的这个文件jsonfile-daemonset-syslog-%{+YYYY.MM.dd}
output {
#if [fields][type] == "app1-access-log" {
if [type] == "jsonfile-daemonset-applog" {
elasticsearch {
hosts => ["192.168.0.122:9200","192.168.0.123:9200","192.168.0.124:9200"] # elasticsearch地址
index => "jsonfile-daemonset-applog-%{+YYYY.MM.dd}"
}}
if [type] == "jsonfile-daemonset-syslog" {
elasticsearch {
hosts => ["192.168.0.122:9200","192.168.0.123:9200","192.168.0.124:9200"]
index => "jsonfile-daemonset-syslog-%{+YYYY.MM.dd}"
}}
}
在一台新的服务器上安装 logsatsh
# 安装Java环境
root@logsatsh01:~# apt install openjdk-11-jdk -y
root@logsatsh01:~# java -version
openjdk version "1.8.0_352"
OpenJDK Runtime Environment (build 1.8.0_352-8u352-ga-1~20.04-b08)
OpenJDK 64-Bit Server VM (build 25.352-b08, mixed mode)
# 安装
root@logsatsh01:~# wget https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/apt/pool/main/l/logstash/logstash-7.12.1-amd64.deb
root@logsatsh01:~# dpkg -i logstash-7.12.1-amd64.deb
logsatsh 配置文件默认存放在 /etc/logstash/conf.d/ 目录,在里面新建一个以 .conf 结尾的文件,把上面的文件粘贴过来
root@logsatsh01:~# cd /etc/logstash/conf.d/
root@logsatsh01:/etc/logstash/conf.d# vim daemonset-log-to-es.conf
input { # input 插件,来自 kafka
kafka {
bootstrap_servers => "192.168.0.125:9092,192.168.0.126:9092,192.168.0.127:9092" # kafka 地址
topics => ["jsonfile-log-topic"]
codec => "json" # 编码。由于日志本来就是json格式的,所以要用json给它解码
}
}
# app1-access-log:业务日志
# jsonfile-daemonset-syslog:系统日志
# 如果是业务日志,就把日志写进elasticsearch的这个文件jsonfile-daemonset-applog-%{+YYYY.MM.dd}
# 如果是系统日志,就把日志写进elasticsearch的这个文件jsonfile-daemonset-syslog-%{+YYYY.MM.dd}
output {
#if [fields][type] == "app1-access-log" {
if [type] == "jsonfile-daemonset-applog" {
elasticsearch {
hosts => ["192.168.0.122:9200","192.168.0.123:9200","192.168.0.124:9200"] # elasticsearch地址
index => "jsonfile-daemonset-applog-%{+YYYY.MM.dd}"
}}
if [type] == "jsonfile-daemonset-syslog" {
elasticsearch {
hosts => ["192.168.0.122:9200","192.168.0.123:9200","192.168.0.124:9200"]
index => "jsonfile-daemonset-syslog-%{+YYYY.MM.dd}"
}}
}
# 重启
root@logsatsh01:/etc/logstash/conf.d# systemctl restart logstash.service
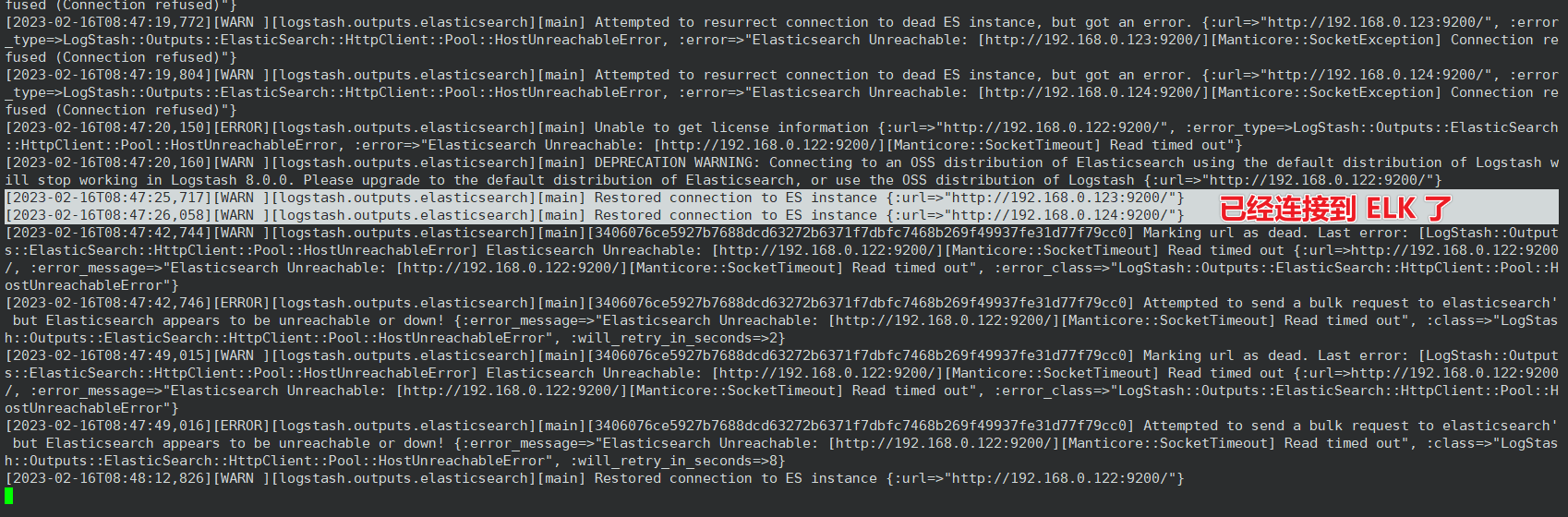
logstash 起来之后,会在 /var/log/logstash/ 目录下生成日志文件
root@logsatsh01:/etc/logstash/conf.d# tail -f /var/log/logstash/logstash-
logstash-deprecation.log logstash-plain.log logstash-slowlog-plain.log
root@logsatsh01:/etc/logstash/conf.d# tail -f /var/log/logstash/logstash-plain.log
2、进行验证
1、Elasticsearch
在 Elasticsearch 里面查看有没有生成新的索引
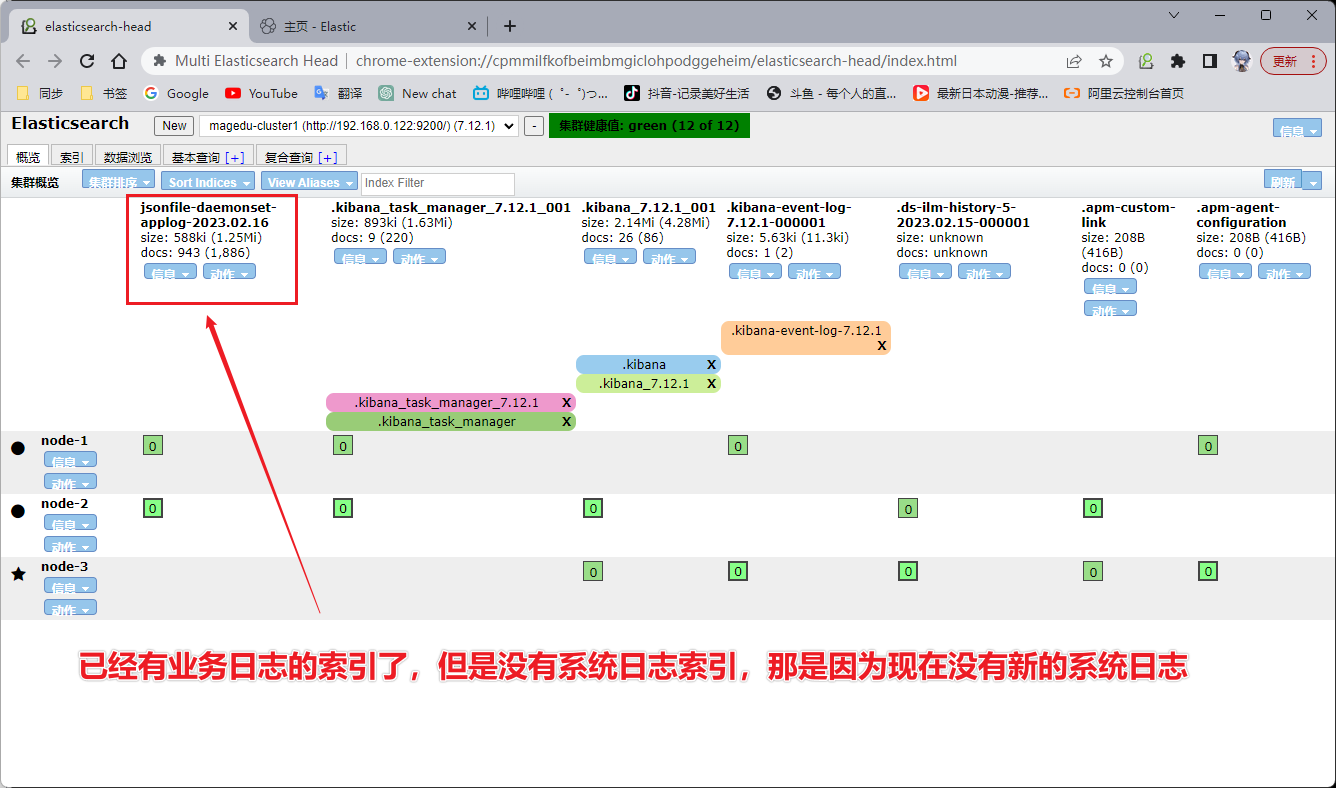
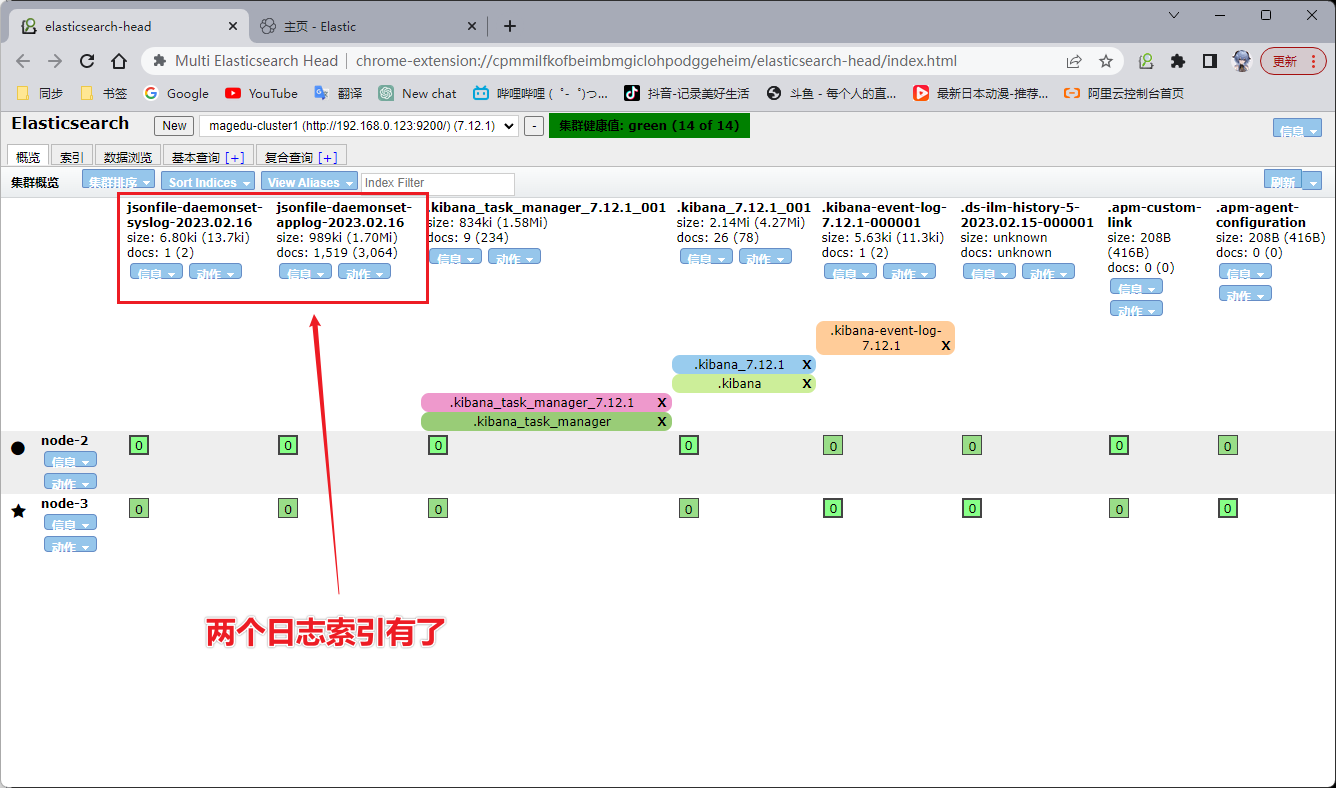
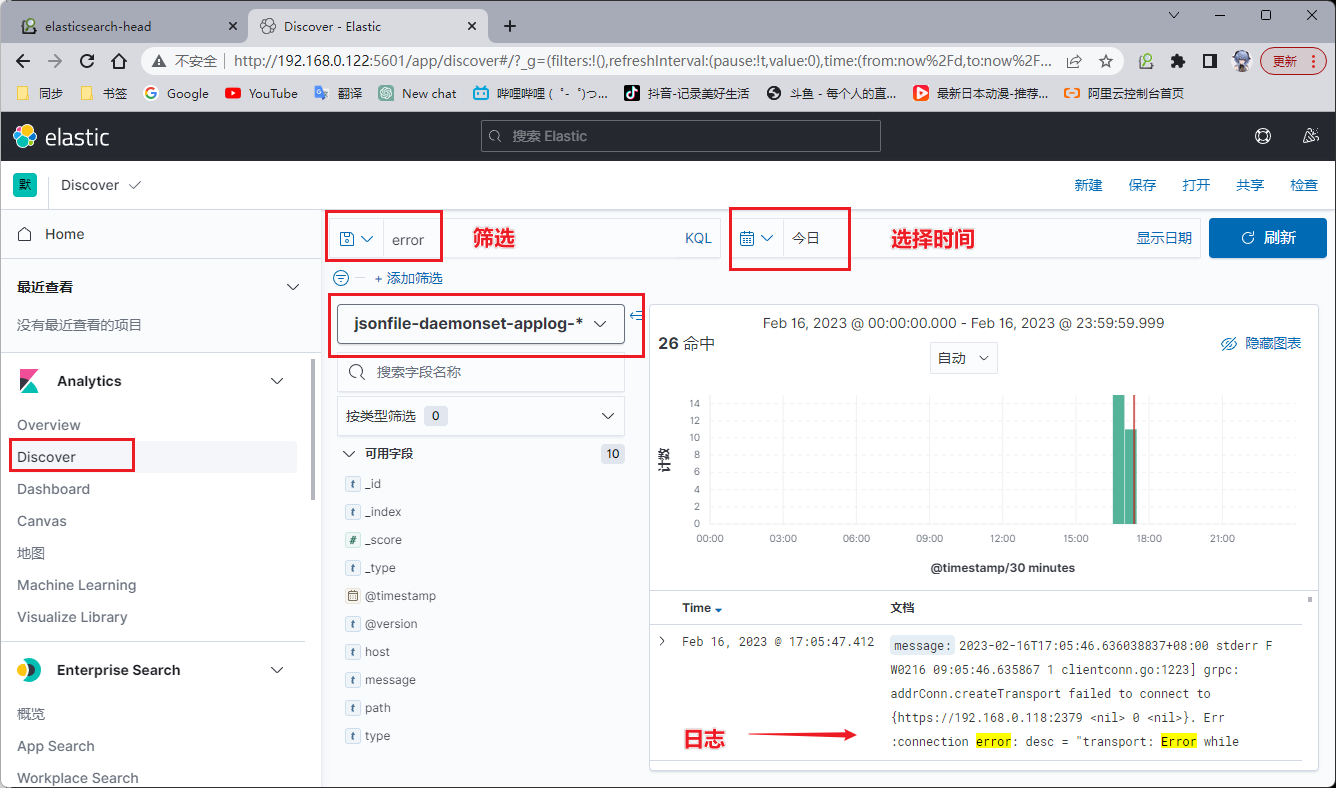
我们在任意一个节点往系统日志里写数据,然后Elasticsearch 里面就会更新出现系统日志的索引。
2、kibana
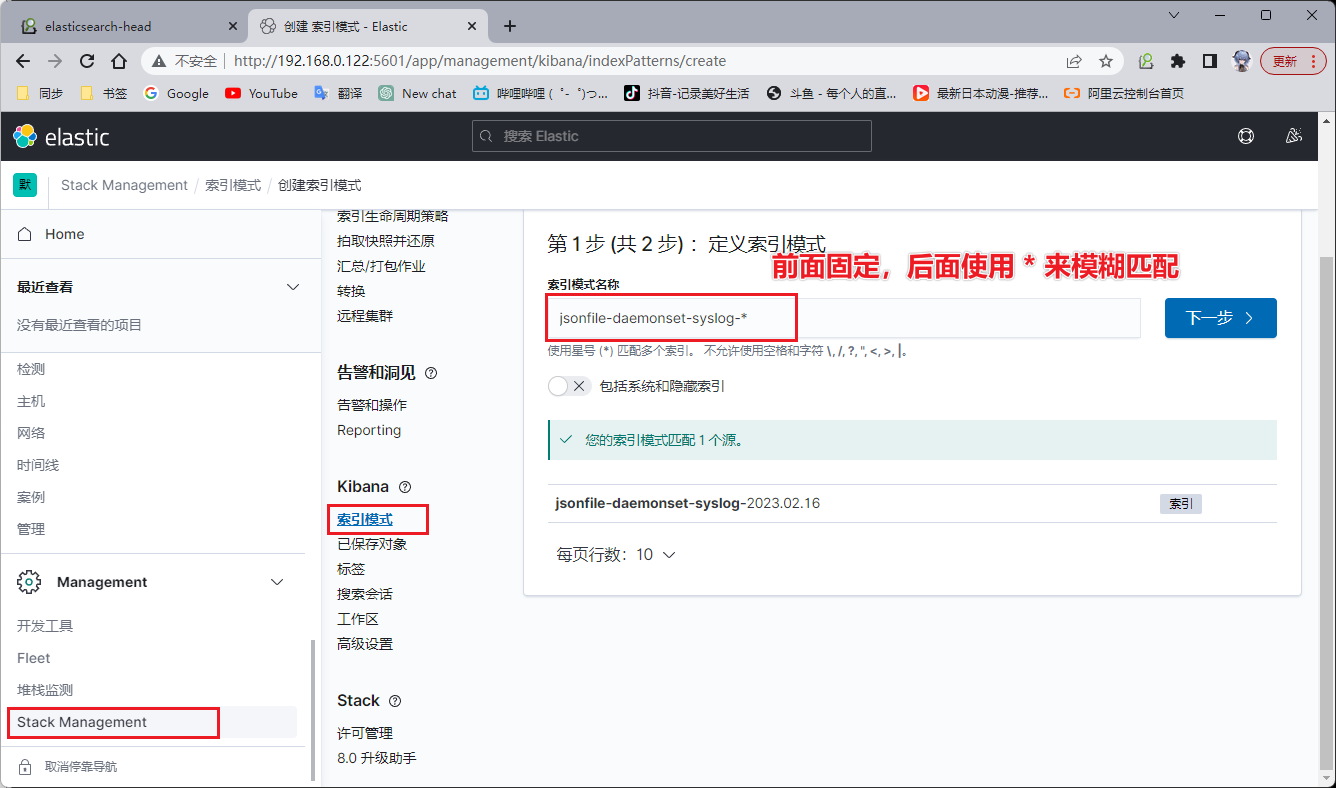
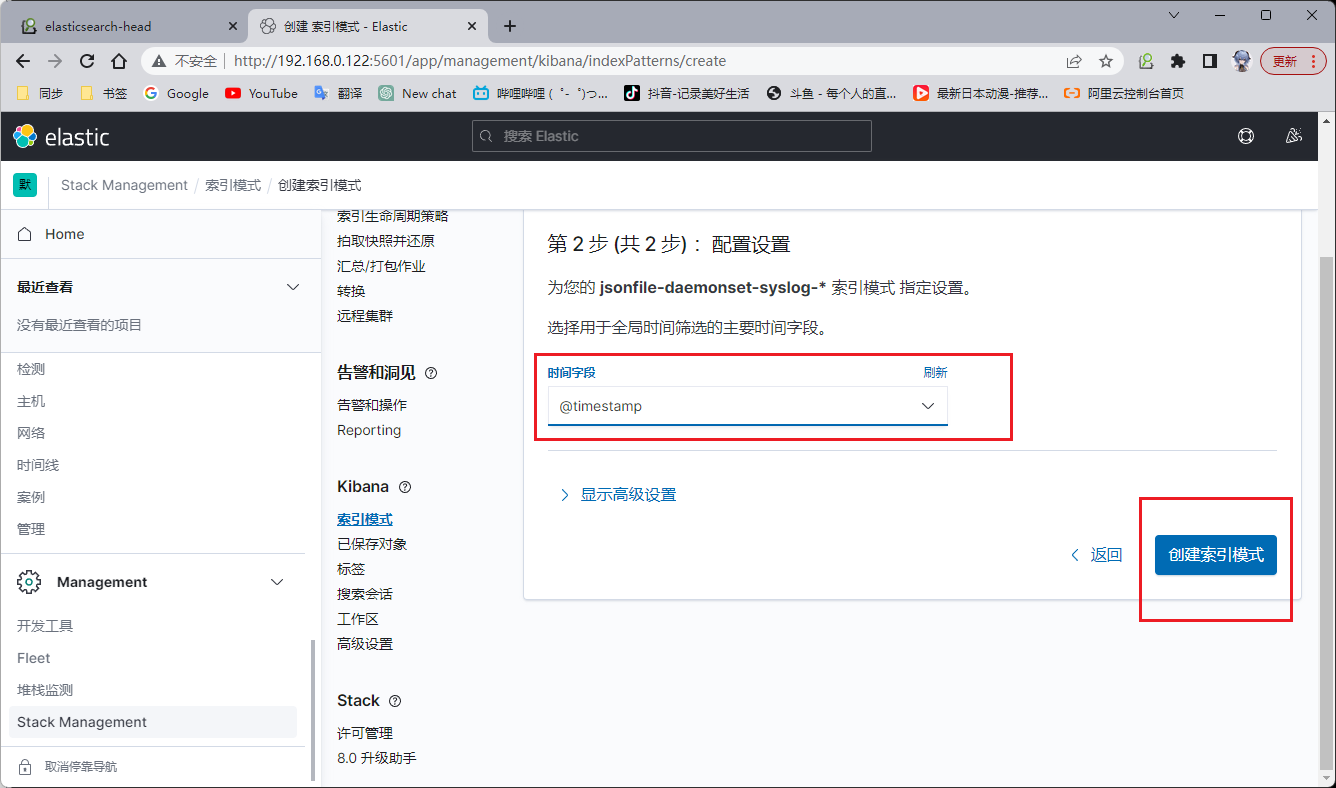
先创建索引,索引名称根据 Elasticsearch 里面的来,前面的固定,后面的年月日使用 * 进行模糊匹配。把 Elasticsearch 里面的两个索引都在 kibana 里面创建好。
6、示例二:sidecar 模式收集日志
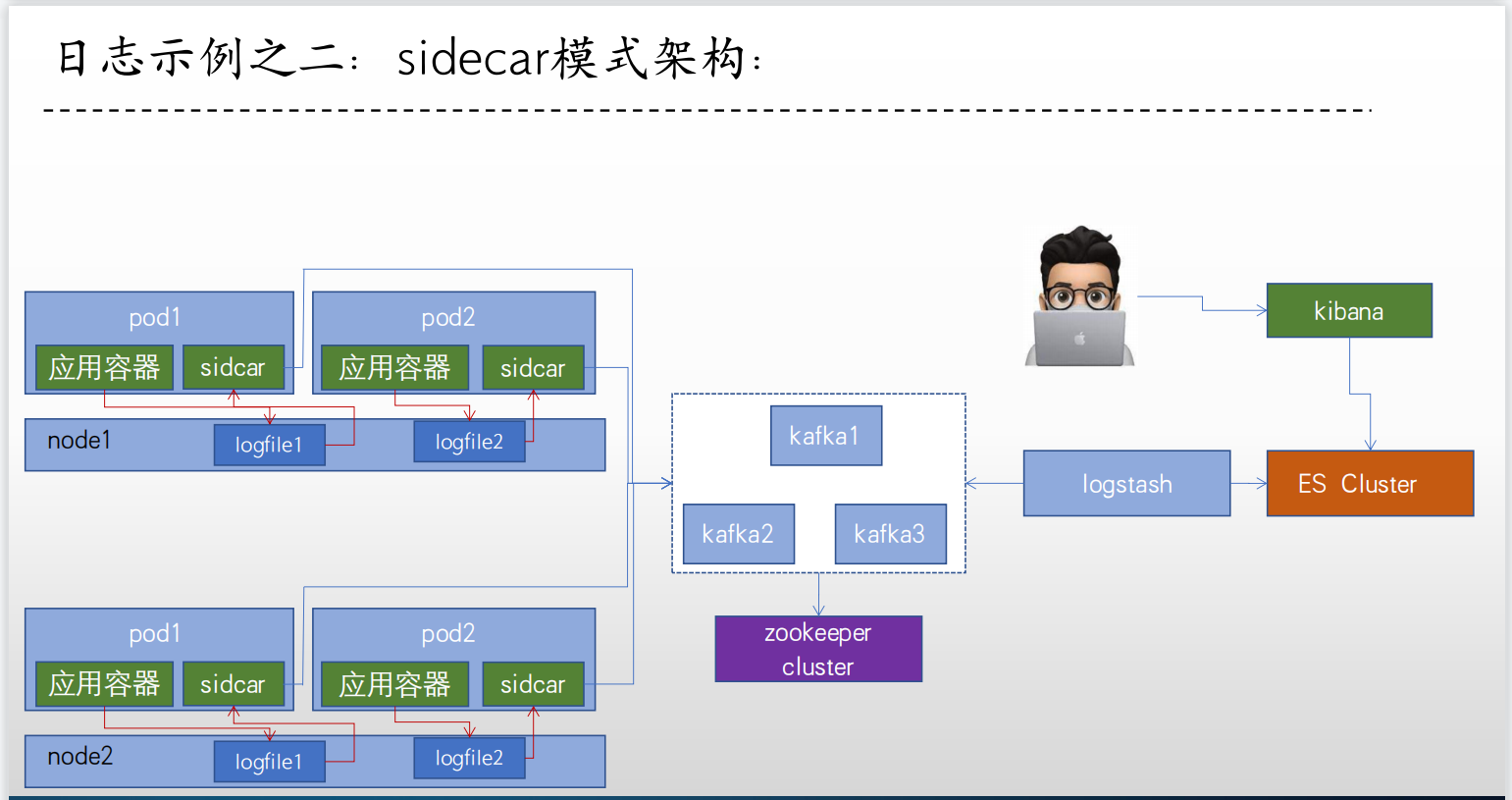
使用 sidca r容器(一个pod多容器)收集当前 pod 内一个或者多个业务容器的日志(通常基于emptyDir实现业务容器与sidcar之间的日志共享)。
1、构建 sidecar 镜像
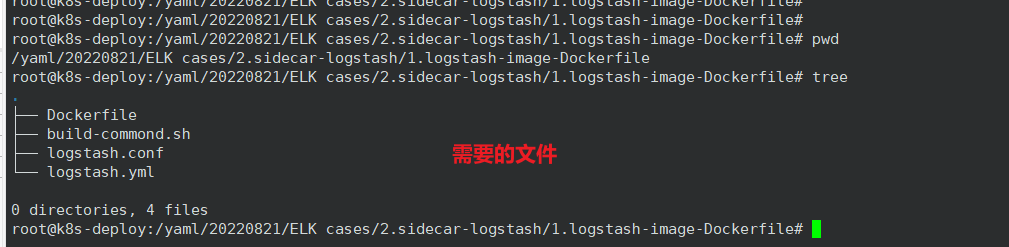
Dockerfile
root@k8s-deploy:/yaml/20220821/ELK cases/2.sidecar-logstash/1.logstash-image-Dockerfile# vim Dockerfile
FROM logstash:7.12.1
USER root
WORKDIR /usr/share/logstash
#RUN rm -rf config/logstash-sample.conf
ADD logstash.yml /usr/share/logstash/config/logstash.yml
ADD logstash.conf /usr/share/logstash/pipeline/logstash.conf
logstash.conf:用来配置日志收集选项
root@k8s-deploy:/yaml/20220821/ELK cases/2.sidecar-logstash/1.logstash-image-Dockerfile# vim logstash.conf
input {
file {
path => "/var/log/applog/catalina.out" # tomcat 启动日志,/var/log/applog/ 是 sidecar 容器挂载到本地的路径
start_position => "beginning"
type => "app1-sidecar-catalina-log"
}
file {
path => "/var/log/applog/localhost_access_log.*.txt" # tomcat 访问日志
start_position => "beginning"
type => "app1-sidecar-access-log"
}
}
output {
if [type] == "app1-sidecar-catalina-log" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384 #logstash每次向ES传输的数据量大小,单位为字节
codec => "${CODEC}"
} }
if [type] == "app1-sidecar-access-log" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384
codec => "${CODEC}"
}}
}
logstash.yml:指定监听地址
root@k8s-deploy:/yaml/20220821/ELK cases/2.sidecar-logstash/1.logstash-image-Dockerfile# vim logstash.yml
http.host: "0.0.0.0"
#xpack.monitoring.elasticsearch.hosts: [ "http://elasticsearch:9200" ]
build-commond.sh
root@k8s-deploy:/yaml/20220821/ELK cases/2.sidecar-logstash/1.logstash-image-Dockerfile# vim build-commond.sh
#!/bin/bash
docker build -t y73.harbor.com/y73/logstash:v7.12.1-sidecar .
docker push y73.harbor.com/y73/logstash:v7.12.1-sidecar
#nerdctl build -t y73.harbor.com/y73/logstash:v7.12.1-sidecar .
#nerdctl push y73.harbor.com/y73/logstash:v7.12.1-sidecar
执行构建脚本
./build-commond.sh
2、构建 tomcat 业务镜像
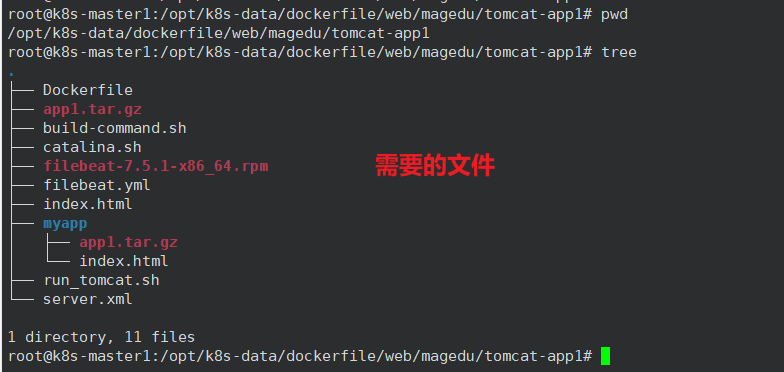
**注意:其中几个脚本文件都要添加执行权限。**其中 tomcat 的启动脚本 catalina.sh 和 主配置文件server.xml,可以通过启动一个容器来获得模板,后期自己修改。filebeat.yml 在容器内启动一个进程,用于日志收集。
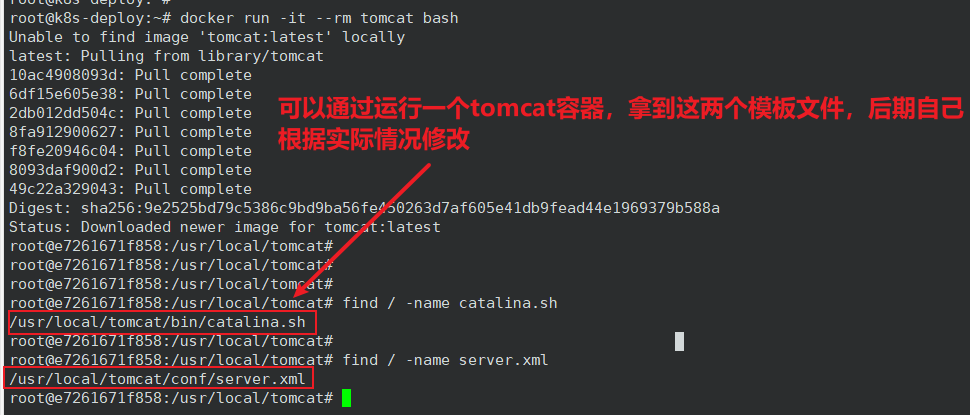
Dockerfile
#tomcat web1
FROM y73.harbor.com/y73/tomcat-base:v8.5.43
ADD catalina.sh /apps/tomcat/bin/catalina.sh
ADD server.xml /apps/tomcat/conf/server.xml
#ADD myapp/* /data/tomcat/webapps/myapp/
ADD app1.tar.gz /data/tomcat/webapps/myapp/
ADD run_tomcat.sh /apps/tomcat/bin/run_tomcat.sh
#ADD filebeat.yml /etc/filebeat/filebeat.yml
RUN chown -R nginx.nginx /data/ /apps/
#ADD filebeat-7.5.1-x86_64.rpm /tmp/
#RUN cd /tmp && yum localinstall -y filebeat-7.5.1-amd64.deb
EXPOSE 8080 8443
CMD ["/apps/tomcat/bin/run_tomcat.sh"]
run_tomcat.sh ,tomcat 启动脚本:运行一个程序在前台占着,防止容器自动退出。
#!/bin/bash
#echo "nameserver 223.6.6.6" > /etc/resolv.conf
#echo "192.168.7.248 k8s-vip.example.com" >> /etc/hosts
#/usr/share/filebeat/bin/filebeat -e -c /etc/filebeat/filebeat.yml -path.home /usr/share/filebeat -path.config /etc/filebeat -path.data /var/lib/filebeat -path.logs /var/log/filebeat &
su - nginx -c "/apps/tomcat/bin/catalina.sh start"
tail -f /etc/hosts
build-command.sh ,执行该脚本要在脚本后面 $1 位置加一个参数用作镜像的 tag 。比如 bash build-command.sh v1
#!/bin/bash
TAG=$1
#docker build -t y73.harbor.com/y73/tomcat-app1:${TAG} .
#sleep 3
#docker push y73.harbor.com/y73/tomcat-app1:${TAG}
nerdctl build -t y73.harbor.com/y73/tomcat-app1:${TAG} .
nerdctl push y73.harbor.com/y73/tomcat-app1:${TAG}
执行构建脚本
root@k8s-master1:/opt/k8s-data/dockerfile/web/magedu/tomcat-app1# bash build-command.sh v1
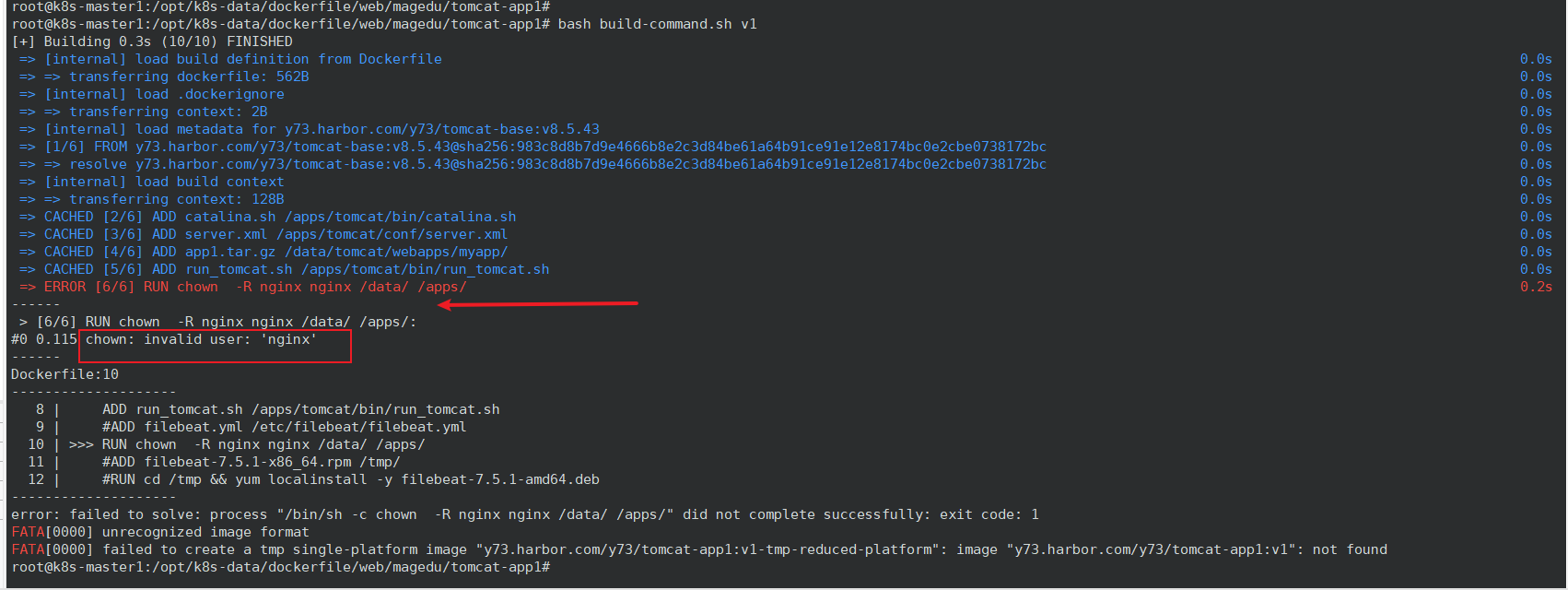
这里报错提示没有 nginx 用户。但是我前面的 centos 基础镜像已经把 nginx 用户加进去了,回去检查发现是基础镜像打错了,重新构建镜像以解决问题。或者在当前 Dockerfile 里加上 RUN useradd nginx -u 2088。
验证镜像
1、启动容器
启动一个容器看看镜像是否没问题。
root@k8s-master1:~# nerdctl run -it -p 8080:8080 y73.harbor.com/y73/tomcat-app1:v1
-bash: /apps/tomcat/bin/catalina.sh: Permission denied
# <nerdctl>
127.0.0.1 localhost localhost.localdomain
::1 localhost localhost.localdomain
10.4.0.2 9060f694b25e nginx-base-9060f
10.4.0.11 1194e7dc15cc tomcat-app1-1194e
10.4.0.12 3bf7cc69f0fa tomcat-app1-3bf7c
# </nerdctl>
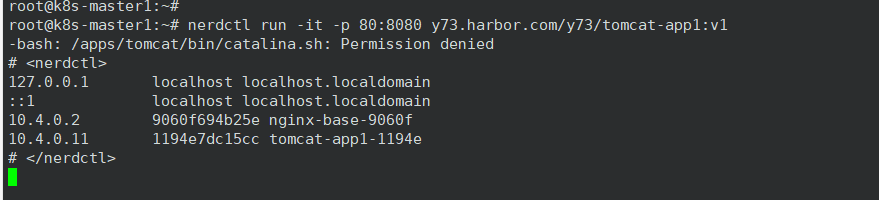
2、排错
用浏览器发现无法访问
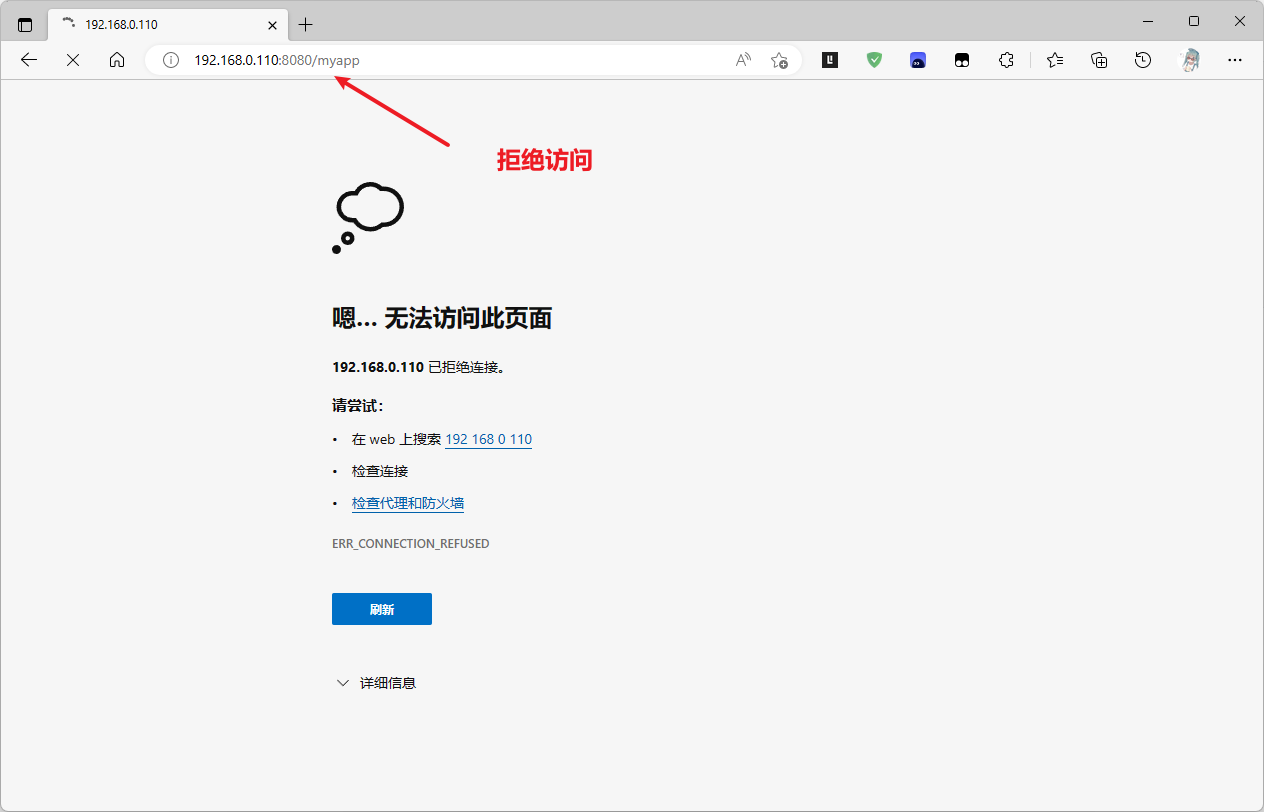
重新启动一个容器并进入查看有没有监听端口,说明 tomcat 没有启动。注意:这里要先启动容器,然后打开新的终端使用命令nerdctl exec -it tomcat-app1-09f71 bash进入容器查看端口。

tomcat 的启动和启动脚本 catalina.sh 有关,回去发现构建镜像时没给执行权限
root@k8s-master1:/opt/k8s-data/dockerfile/web/magedu/tomcat-app1# ll catalina.sh
-rw-r--r-- 1 root root 23611 Feb 1 22:14 catalina.sh
给启动脚本 catalina.sh 添加执行权限,再次构建镜像
root@k8s-master1:/opt/k8s-data/dockerfile/web/magedu/tomcat-app1# chmod a+x catalina.sh
之后启动容器就能正常访问了
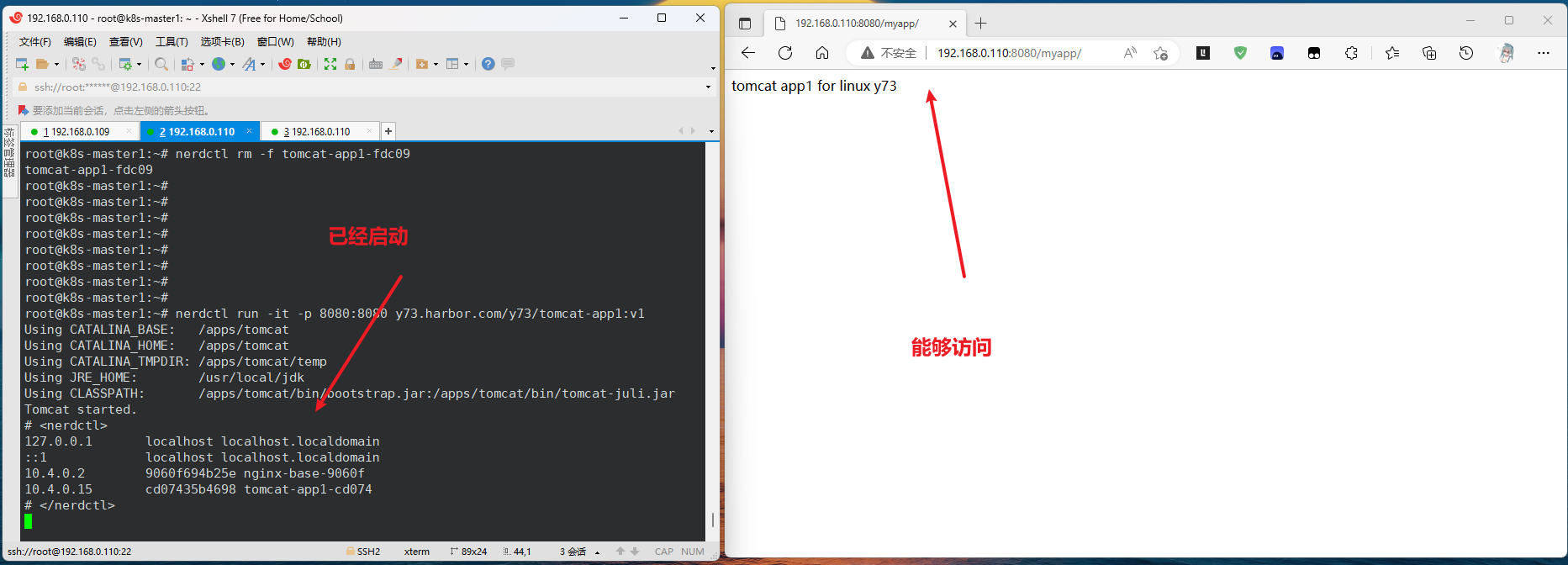
至此业务镜像已经构建成功。
3、部署 web 服务
Pod 配置清单,该 Pod 里有两个容器:tomcat 和 sidecar ,其中 tomcat 使用 emptyDir 将日志文件挂载到本地,sidecar 挂载到相同目录,这样 tomcat 往里面写日志,sidecar 就读取日志。
root@k8s-deploy:/yaml/20220821/ELK cases/2.sidecar-logstash# cat 2.tomcat-app1.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app1-deployment-label
name: magedu-tomcat-app1-deployment #当前版本的deployment 名称
namespace: magedu
spec:
replicas: 3
selector:
matchLabels:
app: magedu-tomcat-app1-selector
template:
metadata:
labels:
app: magedu-tomcat-app1-selector
spec:
containers:
- name: sidecar-container
image: y73.harbor.com/y73/logstash:v7.12.1-sidecar
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
env:
- name: "KAFKA_SERVER"
value: "192.168.0.125:9092,192.168.0.126:9092,192.168.0.127:9092" # kafka地址
- name: "TOPIC_ID"
value: "tomcat-app1-topic"
- name: "CODEC"
value: "json"
volumeMounts:
- name: applogs
mountPath: /var/log/applog
- name: magedu-tomcat-app1-container
image: y73.harbor.com/y73/tomcat-app1:v1
imagePullPolicy: IfNotPresent
#imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits:
cpu: 200m
memory: "256Mi"
requests:
cpu: 200m
memory: "256Mi"
volumeMounts:
- name: applogs
mountPath: /apps/tomcat/logs
startupProbe:
httpGet:
path: /myapp/index.html
port: 8080
initialDelaySeconds: 5 #首次检测延迟5s
failureThreshold: 3 #从成功转为失败的次数
periodSeconds: 3 #探测间隔周期
readinessProbe:
httpGet:
#path: /monitor/monitor.html
path: /myapp/index.html
port: 8080
initialDelaySeconds: 5
periodSeconds: 3
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
livenessProbe:
httpGet:
#path: /monitor/monitor.html
path: /myapp/index.html
port: 8080
initialDelaySeconds: 5
periodSeconds: 3
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
volumes:
- name: applogs # 定义通过emptyDir实现业务容器与sidecar容器的日志共享,以让sidecar收集业务容器中的日志
emptyDir: {}
创建 service ,允许从外部访问 tomcat
root@k8s-deploy:/yaml/20220821/ELK cases/2.sidecar-logstash# cat 3.tomcat-service.yaml
---
kind: Service
apiVersion: v1
metadata:
labels:
app: magedu-tomcat-app1-service-label
name: magedu-tomcat-app1-service
namespace: magedu
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
nodePort: 40080
selector:
app: magedu-tomcat-app1-selector
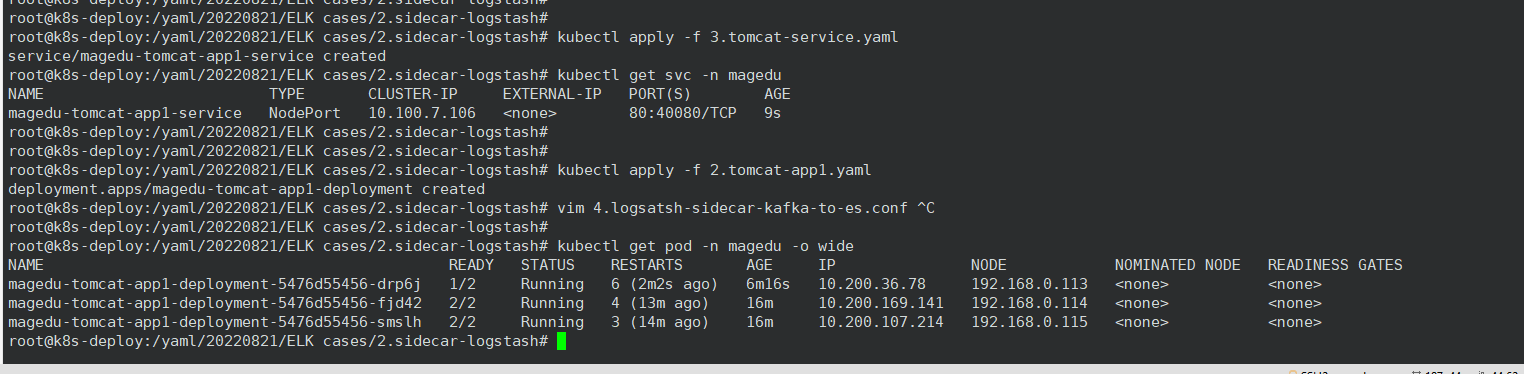
4、修改 logstash 配置文件
在前面我们已经在一台新服务器上安装了 logstash ,在其默认配置文件保存路径追加新的配置文件
root@logsatsh01:~# cd /etc/logstash/conf.d/
root@logsatsh01:/etc/logstash/conf.d# ll
total 4
drwxr-xr-x 2 root root 38 Feb 16 16:36 ./
drwxr-xr-x 3 root root 156 Feb 16 16:31 ../
-rw-r--r-- 1 root root 1102 Feb 16 16:36 daemonset-log-to-es.conf # 前文 daemonset 模式使用的配置文件
# 新增 sidecar 模式使用的配置文件
root@logsatsh01:/etc/logstash/conf.d# vim sidecar-log-to-es.conf
input {
kafka {
bootstrap_servers => "192.168.0.125:9092,192.168.0.126:9092,192.168.0.127:9092"
topics => ["tomcat-app1-topic"]
codec => "json"
}
}
# 判断 type 类型
# 如果是 app1-sidecar-access-log(访问日志)就放在 sidecar-app1-accesslog-%{+YYYY.MM.dd}
# 如果是 app1-sidecar-catalina-log(启动日志)就放在 sidecar-app1-catalinalog-%{+YYYY.MM.dd}
output {
#if [fields][type] == "app1-access-log" {
if [type] == "app1-sidecar-access-log" {
elasticsearch {
hosts => ["192.168.0.122:9200","192.168.0.123:9200","192.168.0.124:9200"] # elasticsearch 地址
index => "sidecar-app1-accesslog-%{+YYYY.MM.dd}"
}
}
#if [fields][type] == "app1-catalina-log" {
if [type] == "app1-sidecar-catalina-log" {
elasticsearch {
hosts => ["192.168.0.122:9200","192.168.0.123:9200","192.168.0.124:9200"]
index => "sidecar-app1-catalinalog-%{+YYYY.MM.dd}"
}
}
# stdout {
# codec => rubydebug
# }
}
修改配置文件后重启 logstash
root@logsatsh01:/etc/logstash/conf.d# systemctl restart logstash.service
5、进行验证
1、kafka 客户端验证
部署 web 服务之后,在 kafka 客户端进行验证
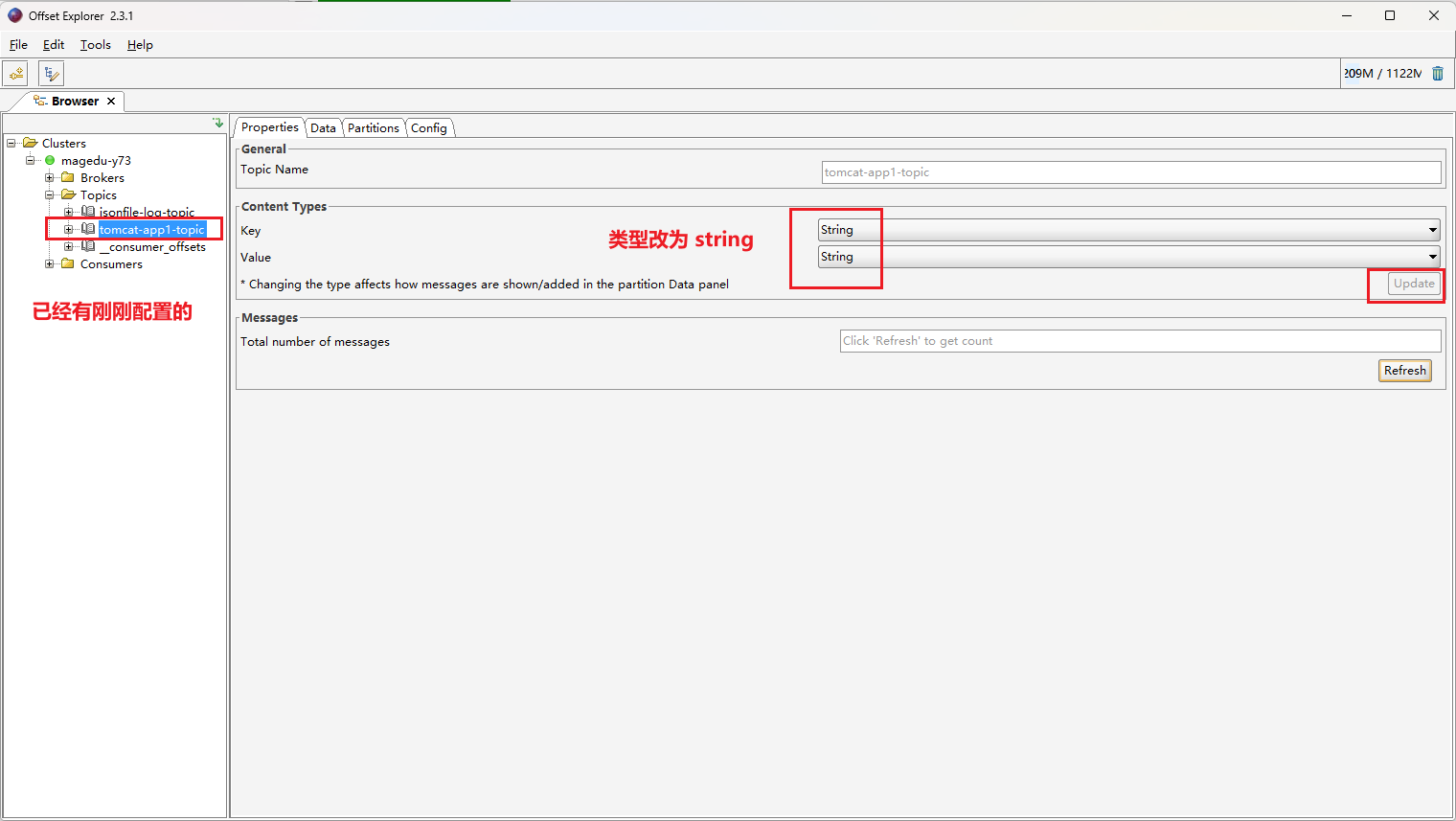
之前出现错误:kafka 客户端只要两个节点,没有125这个节点;而且 Elasticsearch 里面也没有新增的索引,重新启动125节点的 kafka 后恢复正常。

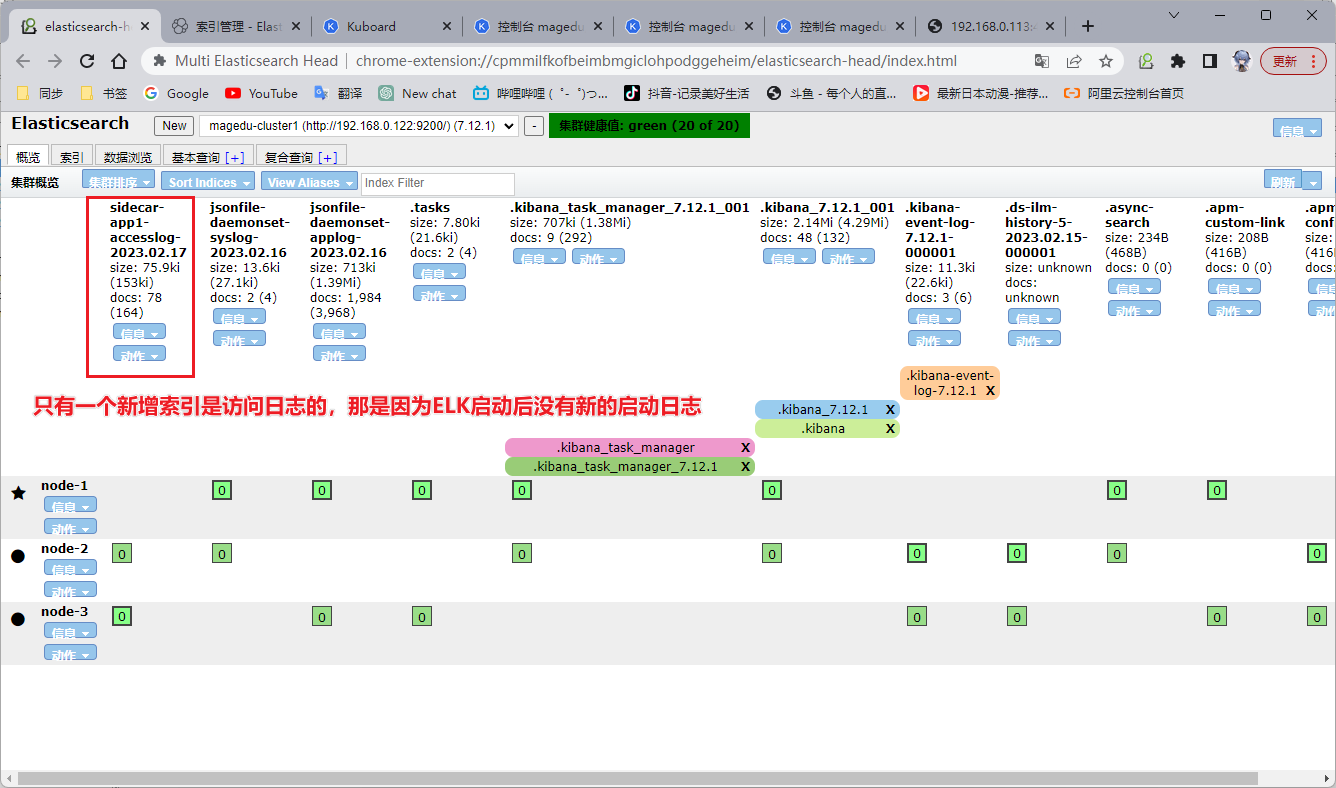
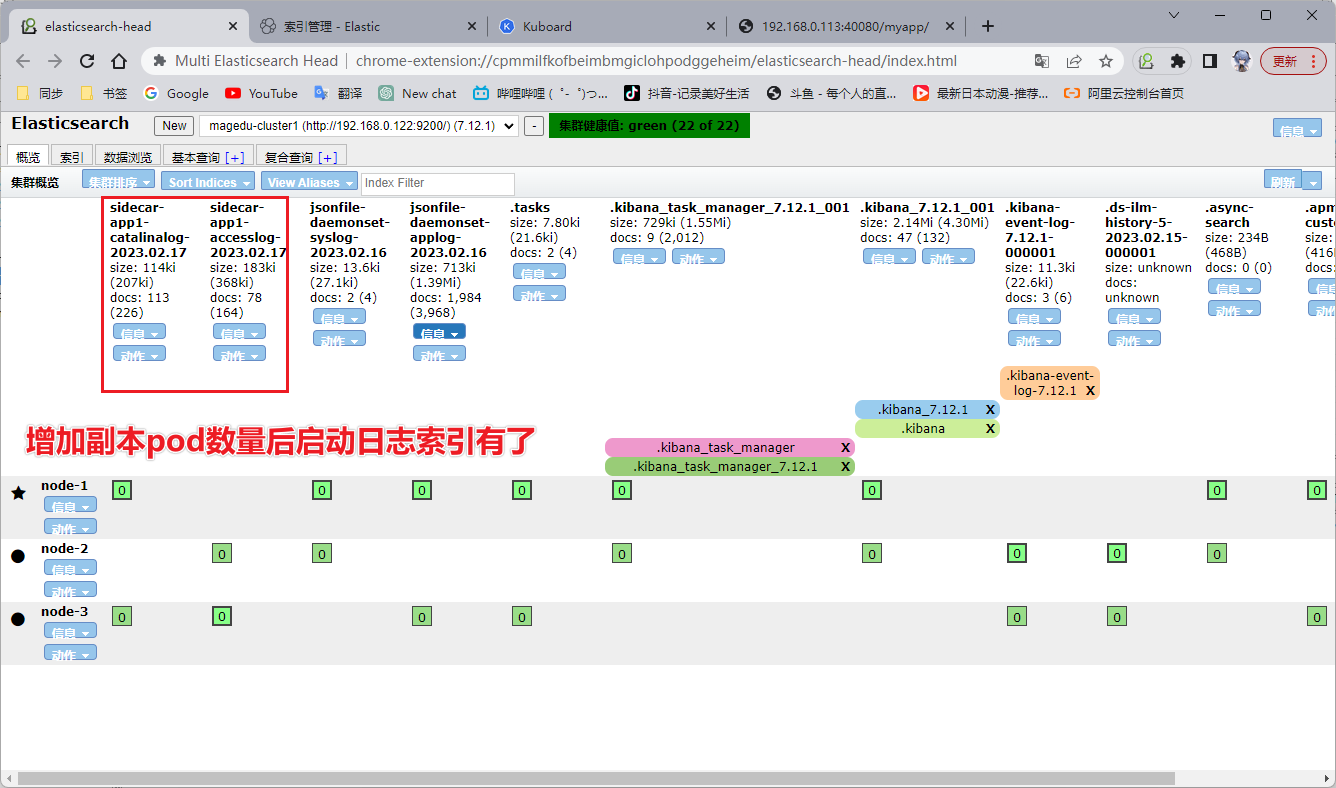
2、Elasticsearch
在 Elasticsearch 里面查看有没有生成新的索引,发现只要访问日志的索引,这个前面的情况一样:暂时没有新的启动日志产生,所以没有生成索引。可以增加副本数量或者进入 Pod 直接往启动日志里写数据
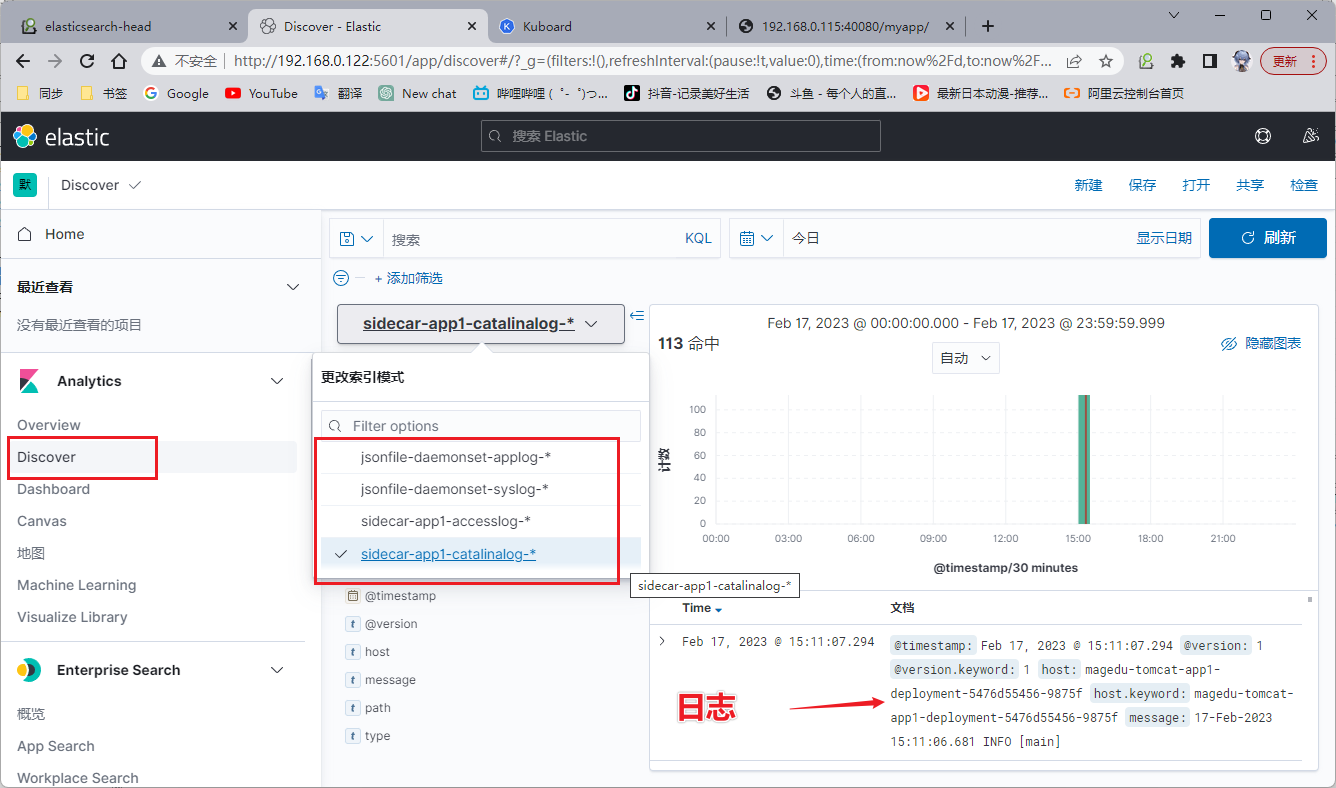
3、kibana
步骤同上面一样

















 1955
1955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









