










**
Spark streaming 整合Kafka基于(Receiver-based Approach)统计词频
**
首先,启动zookeeper

然后,启动kafka

创建topic

启动生产者

启动消费者

开发Spark streaming 整合Kafka统计词频的程序
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
'''Spark streaming 整合Kafka统计词频'''
sc = SparkContext(appName="KafkaReceiverWordCount",master="local[2]")
ssc = StreamingContext(sc,5)
kafkastream = KafkaUtils.createStream(ssc=ssc,zkQuorum="hadoop001:2181",topics={'kafka_streaming_topic':1},groupId="test")
counts = kafkastream.map(lambda x:x[1])\
.flatMap(lambda line:line.split(" "))\
.map(lambda word:(word,1))\
.reduceByKey(lambda a,b:a+b)
counts.pprint()
ssc.start()
ssc.awaitTermination()
启动pyspark

将开发好的代码粘贴到这,开始执行,消费者结果

查看spark streaming执行结果

执行成功。
## Spark Streaming整合Kafka基于Direct Approach (No Receivers)统计词频
启动zookeeper,启动生产者,消费者步骤同上,开发spark streaming程序
#!/usr/bin/python
#coding=utf-8
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
'''Spark Streaming整合Kafka基于Direct Approach (No Receivers)统计词频'''
sc = SparkContext(master="local[2]",appName="KafkaDirectWordCount")
ssc = StreamingContext(sc,10)
topics = ["kafka_streaming_topic"]
kafkaDStream = KafkaUtils.createDirectStream(ssc=ssc,\
topics=topics,\
kafkaParams={"bootstrap.servers":"hadoop001:9092"})
wordCounts = kafkaDStream.map(lambda x: x[1])\
.flatMap(lambda line: line.split(" "))\
.map(lambda word: (word,1))\
.reduceByKey(lambda a,b: a+b)
wordCounts.pprint()
ssc.start()
ssc.awaitTermination()
使用spark-submit提交程序:
./spark-submit \
--master local[2] \
--num-executors 2 \
--executor-memory 1G \
/usr/soft/script/python/KafkaDirectWordCount.py
在生产者中,输入数据进行测试
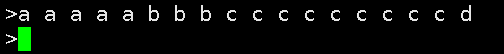
查看结果,正是我们想要的

这是spark streaming 整合kafka的两种方式,在spark1.3之后spark streaming已经支持Direct Approach (No Receivers)的java API与scala API,在spark1.4之后就支持python API。实际生产环境中,大多数情况我们使用的也是Direct Approach (No Receivers)这种方式。















 1243
1243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









