






问题:
将整理好的数据上传到服务器的过程中,我遇到了很多问题:
1.文件夹太大上传太慢;
2.压缩太慢;
3.不同形式的压缩文件解压后汉字显示不同的错误,无法一一对应。
解决:
这是我所使用的方法(仅供参考)
1.下载7-zip,它可以快速压缩较大文件夹,甚至可以将一个大文件夹分卷压缩。
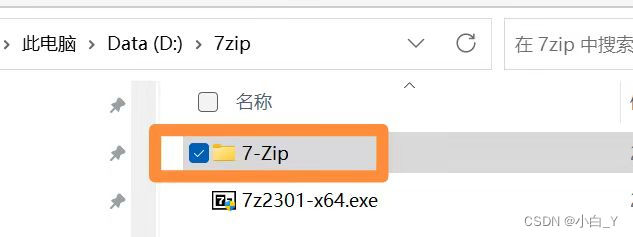
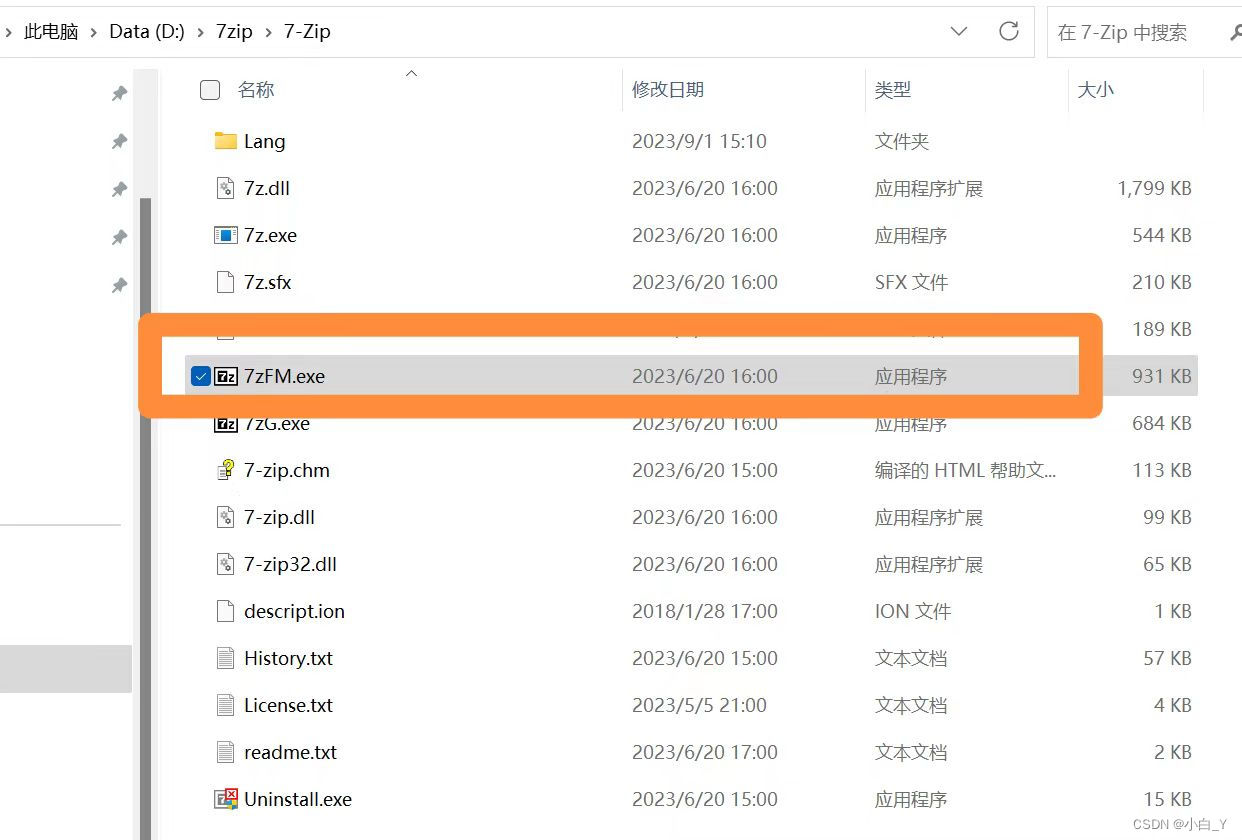
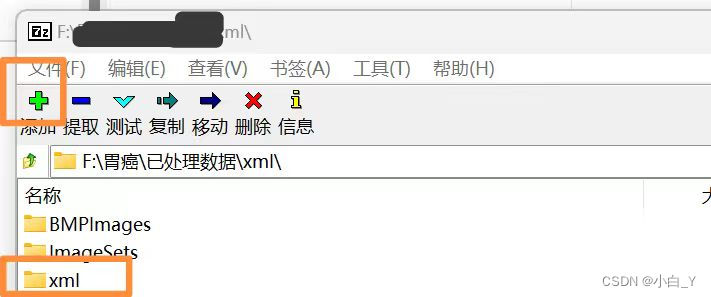
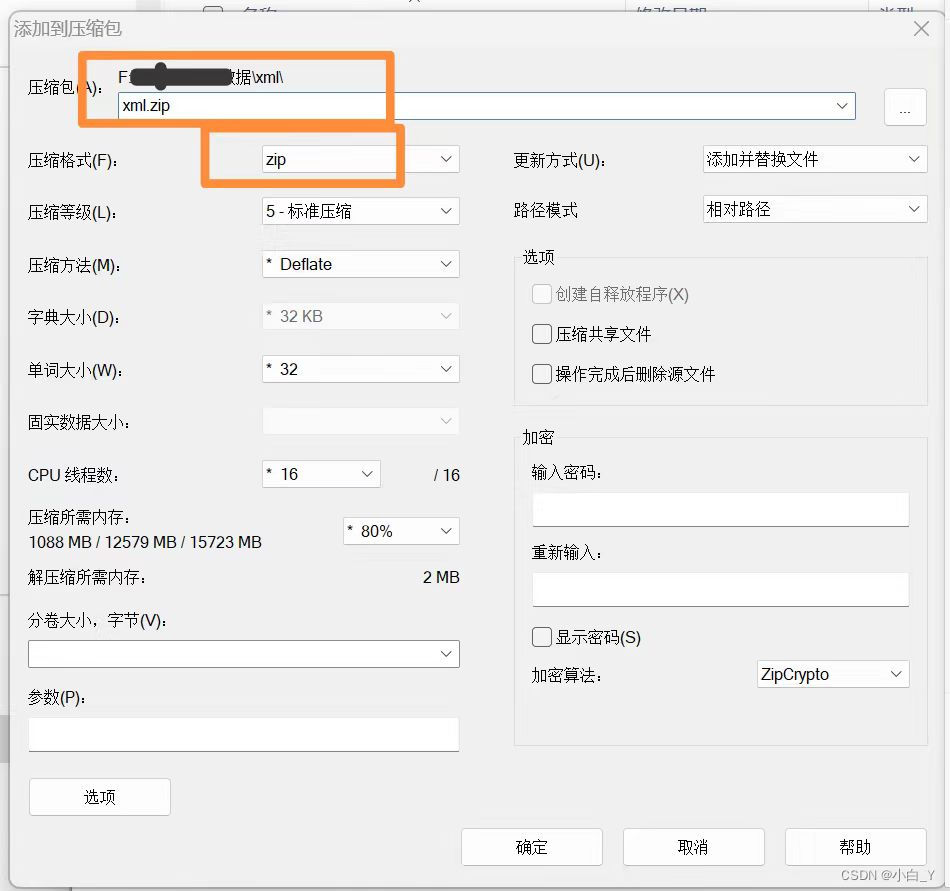
2.打开应用程序,选中要压缩的文件夹点击左上角的‘+’号,对文件夹进行压缩。
3.压缩完成后打开xftp,直接将文件夹的压缩包进行拖动,上传。
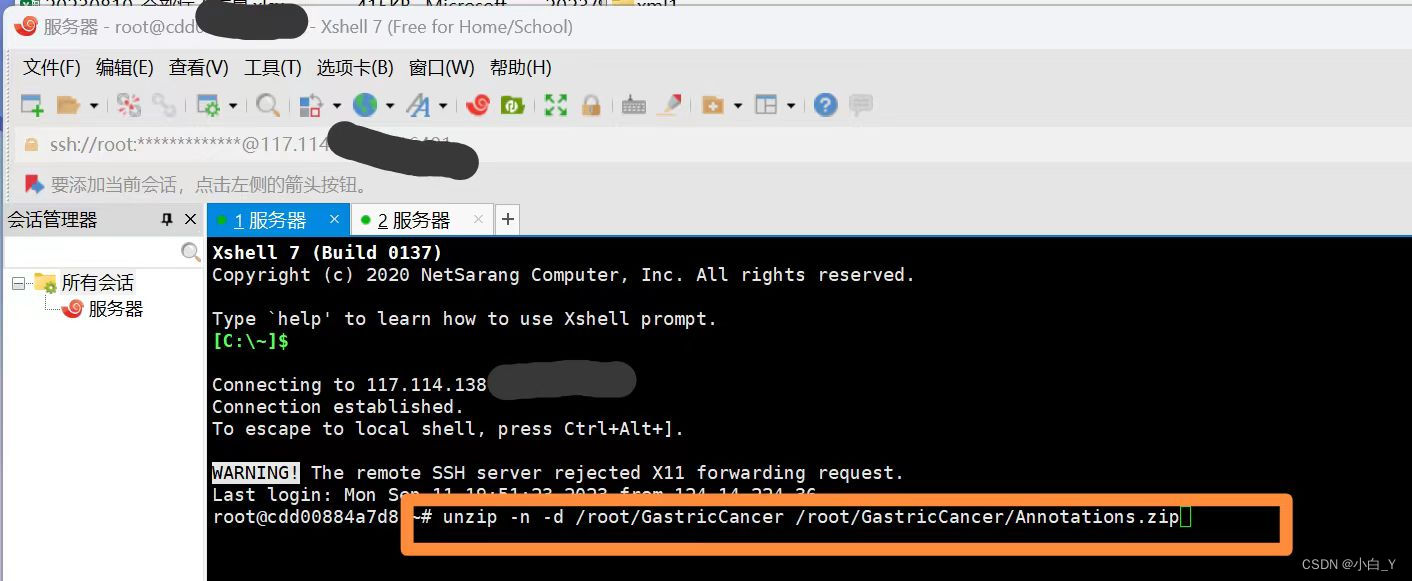
4.上传成功后,打开xshell,连接服务器,对压缩包进行解压。
解压命令:unzip -n -d 压缩包路径 压缩包路径/压缩包名称
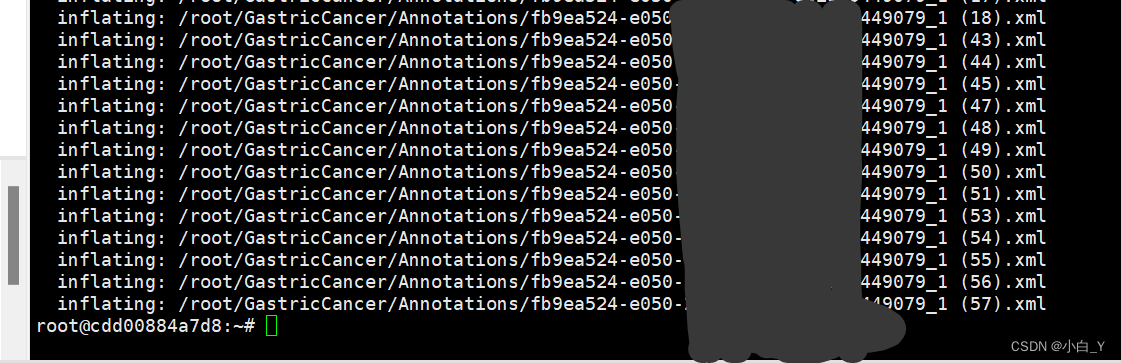
5.解压后我发现文件名中的汉字由16进制字符unicode转换,如下。

6.我用以下代码打印出所有文件名汉字的集合,并在百度中查找每个汉字的16进制字符unicode编码。
import os
import re
# 定义一个函数,用于检查字符串是否包含汉字并收集汉字到集合中
def collect_chinese(file_name, chinese_set):
chinese_pattern = re.compile(r'[\u4e00-\u9fa5]+')
matches = chinese_pattern.findall(file_name)
chinese_set.update(matches)
# 指定要搜索的目录路径
search_directory = r'F:\code_demo\测试一/'
# 创建一个集合来存储所有汉字
chinese_characters = set()
# 遍历指定目录及其子目录下的所有文件
for root, dirs, files in os.walk(search_directory):
for file_name in files:
collect_chinese(file_name, chinese_characters)
# 打印所有汉字的集合
for chinese_char in chinese_characters:
print(chinese_char)
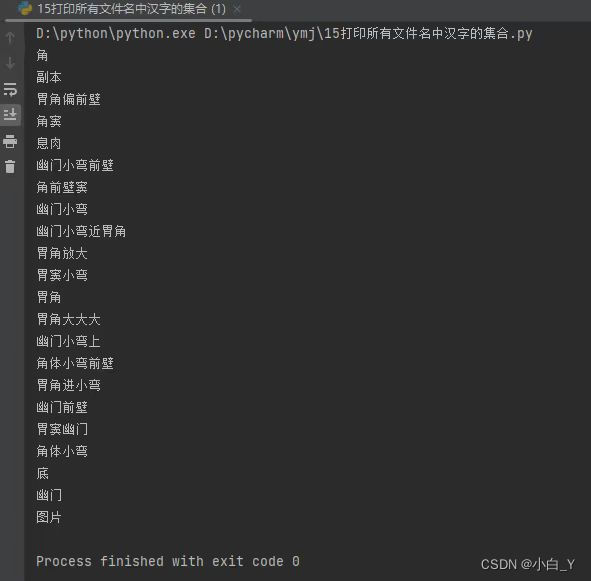

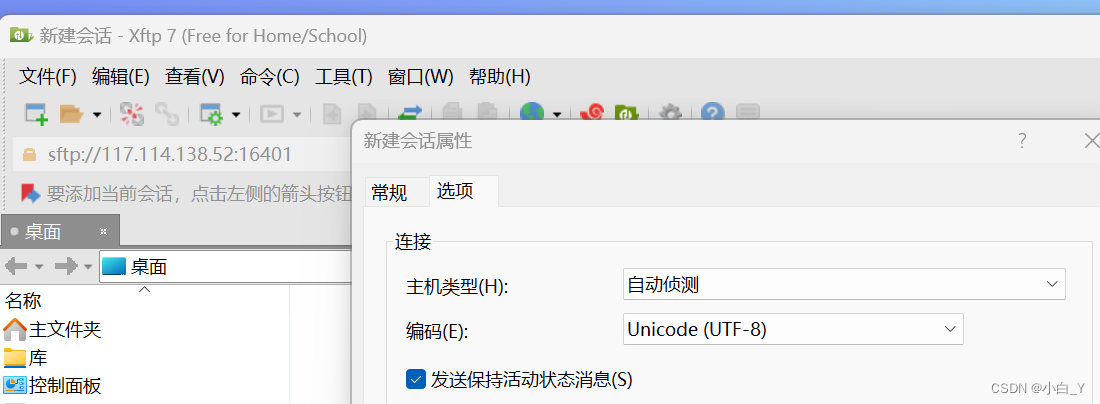
7.将文件中的所有编码替换成汉字,运行代码之后更改xftp中文件属性:xftp-文件-当前会话属性-选项-编码(改为utf-8)。(此时我们改的是服务器上的文件,所以用服务器上的jupyter运行)
import os
# 定义要替换的字符串和相应的替换值
replacement_dict = {
'#U5c0f#U5f2f': '小弯',
'#U58c1': '壁',
'#U4e0a': '上',
'#U5e7d#U95e8': '幽门',
'#U653e': '放',
'#U89d2': '角',
'#U4f53': '体',
'#U7aa6': '窦',
'#U504f': '偏',
'#U5e95': '底',
'#U80c3': '胃',
'#U56fe#U7247': '图片',
'#U540e': '后',
'#U606f#U8089': '息肉 ',
'#U8fdb': '进',
'#U8fd1': '近',
'#U526f#U672c': '副本',
'#U5927': '大',
'#U524d': '前',
}
# 定义要遍历的文件夹路径
folder_path = r'F:\code_demo\测试一/'
# 遍历文件夹中的所有文件
for root, dirs, files in os.walk(folder_path):
for file_name in files:
file_path = os.path.join(root, file_name)
new_file_name = file_name
# 遍历替换字典,将匹配的字符串替换为相应的值
for old_str, new_str in replacement_dict.items():
new_file_name = new_file_name.replace(old_str, new_str)
# 构造新的文件路径
new_file_path = os.path.join(root, new_file_name)
# 重命名文件
os.rename(file_path, new_file_path)
print(f'已重命名文件: {file_path} 为 {new_file_path}')
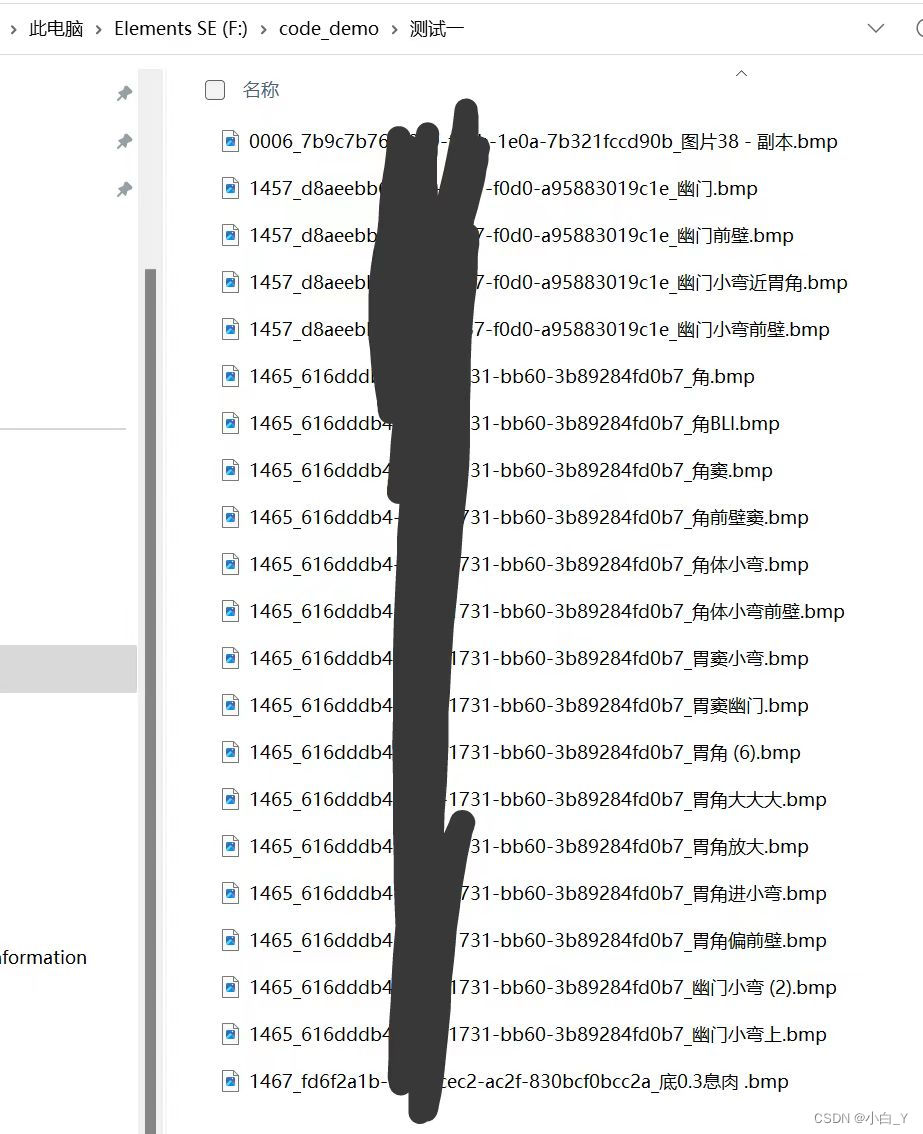
8.检验
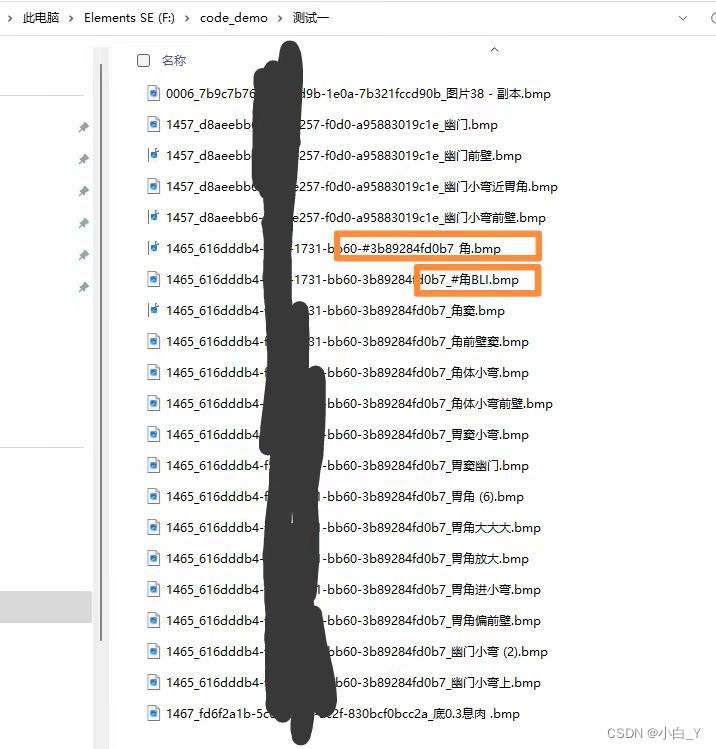
因为我解压缩后所有关于中文的字符都是“#U****”这种类型的,所以在检查所有文件是否都转换完时,这里我用“#”检查。(大家可以依情况而定)(此时我们检查的是服务器上的文件,所以用服务器上的jupyter运行)
如果查出来还有16进制字符unicode(例如:中文的括号等,可以将它变成英文的),继续往第6步中添加值进行运行。
我们手动更改俩个文件名称来测试:
import os
# 定义要遍历的根文件夹路径
root_folder = r'F:\code_demo\测试一/'
# 遍历文件夹及其子文件夹
for folder_name, _, file_names in os.walk(root_folder):
# 遍历当前文件夹中的文件
for file_name in file_names:
# 检查文件名是否包含'#'
if '#' in file_name:
# 输出包含 '#' 的文件名及其所在路径
print("文件名包含 '#' 的文件:", os.path.join(folder_name, file_name))



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









