







人们发现用同一数据集,既进行训练,又进行模型误差估计,对误差估计的很不准确,这就是所说的模型误差估计的乐观性。为了克服这个问题,提出了交叉验证。基本思想是将数据分为两部分,一部分数据用来模型的训练,称为训练集;另外一部分用于测试模型的误差,称为验证集。由于两部分数据不同,估计得到的泛化误差更接近真实的模型表现。数据量足够的情况下,可以很好的估计真实的泛化误差。但是实际中,往往只有有限的数据可用,需要对数据进行重用,从而对数据进行多次切分,得到好的估计。
k折中的k到底设定为多少,这个又是一个调参的过程,当然了,这一步很少有人会调参,一般都是用10.但是如果你的数据集特别小,我们当然希望训练集大一点,这时候就要设定大一点的k值,因为k越大,训练集在整个原始训练集的占比就越多。但是呢,k也不能太大,一则是导致训练模型个数过多,二则是k很大的情况下,各个训练集相差不多,导致高方差。要是你的数据集很大,那就把k设定的小一点咯,比如5.
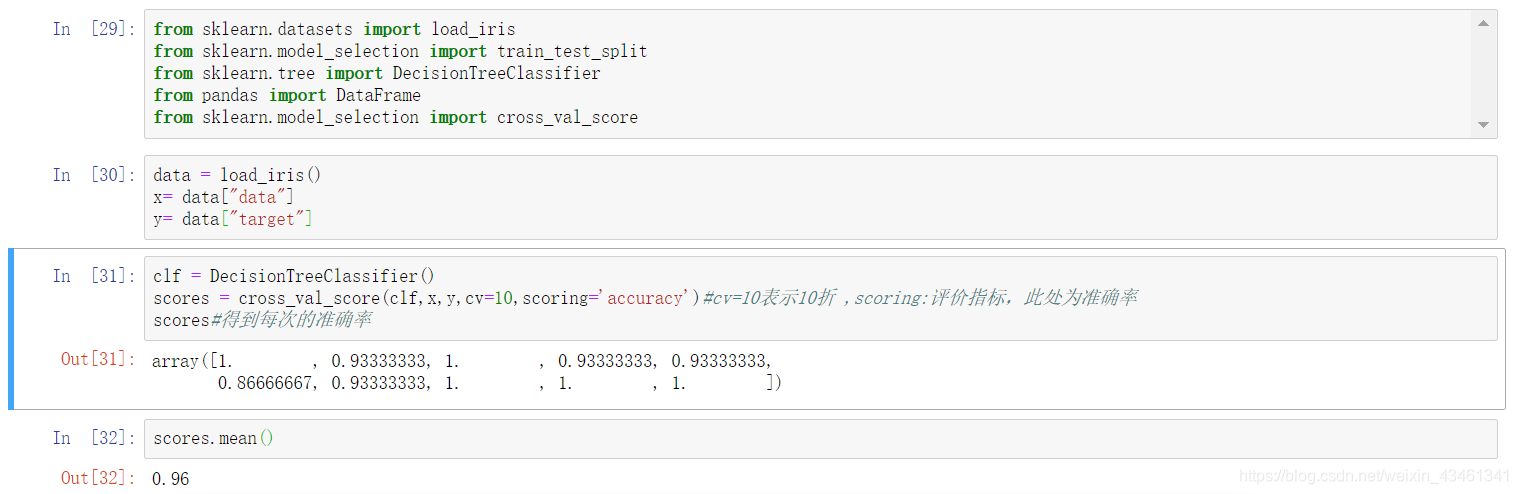
python代码实现:














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









