






链接:https://blog.csdn.net/pipisorry/article/details/52574156
多分类
1.可以把要关注的那一类作为一类,其他所有类作为另一类,转变为二分类问题。
2.宏平均(macro-average)和微平均(micro-average)
当我们在n个二分类混淆矩阵上要综合考察评价指标的时候就会用到宏平均和微平均。宏平均(macro-average)和微平均(micro-average)是衡量文本分类器的指标
简单理解,宏平均就是先算出每个混淆矩阵的P值和R值,然后取得平均P值macro-P和平均R值macro-R,再算出Fβ或F1,而微平均则是计算出混淆矩阵的平均TP、FP、TN、FN,接着进行计算P、R,进而求出Fβ或F1。其它分类指标同理,均可以通过宏平均/微平均计算得出。
示例
假设有10个样本,它们属于A、B、C三个类别。假设这10个样本的真实类别和预测的类别分别是:


需要注意的是,在多分类任务场景中,如果非要用一个综合考量的metric的话,宏平均会比微平均更好一些,因为宏平均受稀有类别影响更大。宏平均平等对待每一个类别,所以它的值主要受到稀有类别的影响,而微平均平等考虑数据集中的每一个样本,所以它的值受到常见类别的影响比较大。
3.Kappa一致性系数
交叉表(混淆矩阵)虽然比较粗糙,却是描述栅格数据随时间的变化以及变化方向的很好的方法。但是交叉表却不能从统计意义上描述变化的程度,需要一种能够测度名义变量变化的统计方法即KAPPA指数——KIA。 kappa系数是一种衡量分类精度的指标。KIA主要应用于比较分析两幅地图或图像的差异性是“偶然”因素还是“必然”因素所引起的,还经常用于检查卫星影像分类对于真实地物判断的正确性程度。KIA是能够计算整体一致性和分类一致性的指数。
KIA的计算式的一般性表示为:
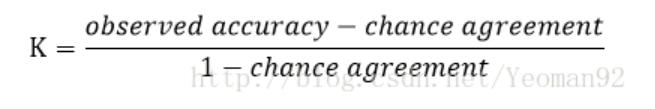

式中的p0和pc都有着明确的含义:p0被称为观测精确性或一致性单元的比例;pc被称为偶然性一致或期望的偶然一致的单元的比例。kappa计算结果为-1~1,但通常kappa是落在 0~1 间,可分为五组来表示不同级别的一致性:0.00.20极低的一致性(slight)、0.210.40一般的一致性(fair)、0.41~0.60 中等的一致性(moderate)、0.61~0.80 高度的一致性(substantial)和0.81~1几乎完全一致(almost perfect)。
kappa指数计算的一个示例:
混淆矩阵
















 9938
9938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









