







模型评估与选择:分类模型和数值预测模型
分类模型评价指标
在我们建立了分类模型以后,接下来的问题自然是我们所建立的模型是好是坏。对于分类模型,我们会自然的想到:通过结果的准确率来判断模型好坏,然而是否所有模型都能使用准确率这一指标来评价模型呢?什么情况需要引入其他指标来评价模型好坏?有哪些指标呢?
首先,不同指标的基础都是混淆矩阵。
1、混淆矩阵
对于二分类问题的混淆矩阵:混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示.混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。
| Predict | |||
| Actural | 类0 | 类1 | |
| 类0 | TN(真负例) | FP(假正例) | |
| 类1 | FN(假负例) | TP(真正例) | |
如上图,混淆矩阵就是根据已知数据所建立的模型,对样本预测的类别和真实类别的分布情况。
其中,TP为Ture Positive:真正例,就是样本本身为正例(类1)且被分类模型预测成正类(类1)的数量;
FP为False Positive:假正例,就是样本本身为负例(类0)却被分类模型错误预测成正类(类1)的数量;
TN为Ture Negative:真负例,就是样本本身为负例(类0)且被分类模型预测成负类(类0)的数量;
FN为False Negative:假负例,就是样本本身为正例(类1)却被分类模型错误预测成负类(类0)的数量。
2、模型准确率Accuracy
根据混淆矩阵,最常见的指标就是准确率(Accuracy):预测类别和真实类别一致的样本占比。 A c c u r a c y = T P + T N T P + F P + T N + F N Accuracy=\frac{TP+TN}{TP+FP+TN+FN} Accuracy=TP+FP+TN+FNTP+TN再回到我们开头所提,准确率是否可以用于评估所有模型?答案是否定的,这涉及到一种类不平衡的问题。
note.类不平衡/类偏斜
例如在商业银行信用风险检测中,如果我们通过建模得到的预测准确率是99%,我们在了解数据之前可能会觉得:哇,准确率真高。但是如果我们了解实质数据情况,不难发现,违约客户和正常客户的比例往往存在严重的不平衡,违约客户往往占比很小。
假设某数据中违约用户占比1%,此时,你还会觉得模型预测准确率很高吗?不尽然吧。在这种情况,如果我们还是使用准确率这个指标,难免会出错。因为,对于刚才信用风险违约检测的例子,就算我们把全部样本都预测为“不违约”,此时预测准确率仍然为99%。但是,此时若银行给真实会违约的客户发放贷款,而客户违约不还,这给银行带来的损失是巨大的。
此时,我们还需要引入精度Precision、召回率Recall、F1指标来评估模型性能。
2、精度Precision
我们以类1的precision为例,精度就是模型预测为正例(类1)且真实是正例(类1)的样本占所有预测为正例(类1)的样本的比重。
p
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
precision=\frac{TP}{TP+FP}
precision=TP+FPTP为什么要引入精度的概念呢?它比准确率好在哪呢?
精度用于评价模型预测效果,精度越大,说明对于我们关心的类别,模型假正例错误率越低(分母FP越小),模型预测正确的比例高(precision越大),模型性能较好。而不像准确率值考虑全部类别中预测正确的样本占比,precision研究的是我们关心的类别的预测准确率。
若上述商业银行信用风险检测的例子,我们预测样本全部为不违约,此时我们关心的类1(违约)precision值为0%,可以明显的看出模型预测完全没有效果。
| Predict | |||
| Actural | 类0 | 类1 | |
| 类0 | TN=99 | FP=0 | |
| 类1 | FN=1 | TP=0 | |
下面要说的召回率Recall是类似的概念。
3、召回率Recall
同样以类1的recall为例,召回率就是模型真实是正例(类1)且被准确预测为正例(类1)的样本占所有真实为正例(类1)的样本的比重。
r
e
c
a
l
l
=
T
P
T
P
+
F
N
recall=\frac{TP}{TP+FN}
recall=TP+FNTP同样地,为什么要引入Recall召回率的概念呢?
召回率越大,说明对于我们关心的类别,模型预测正确的比例高,模型假负例错误率越低(分母FN越小),模型性能较好。而不像准确率值考虑全部类别中预测正确的样本占比,recall研究的是我们关心的类别的预测准确率。
对于上述商业银行信用风险检测的例子,我们预测样本全部为不违约,此时我们关心的类1(违约)的recall值为0%,可以明显的看出模型预测完全没有效果。
4、Precision和Recall的trade off——F1指标
看到这,可能有小伙伴会想:对于上述问题,如果换成是对类0(不违约)的precision和recall值就会得出完全不同的结果。是的,这也正是为什么对于类不平衡的问题更需要这两个指标的原因。在类不平衡的数据集中,往往会涉及到代价敏感度的问题。什么是代价敏感度呢?
代价敏感性(cost sensitive),指的是在分类问题中,当把某一类A错误的分成了类B,会造成巨大的损失,例如在欺诈检测中,如果把欺诈用户错误的分成了优质客户,那么这会使得欺诈用户不会受到惩罚而继续欺诈。
所以,我们遇到类不平衡的问题时,需要考虑我们关心的那一类的指标值。比如,对于商业银行信用风险检测,我们关心违约(类1)的样本。在癌症患者预测中,预测错误(把癌症病人预测成非癌症患者)而使癌症病人错过最佳治疗时间,所带来的损失巨大,我们关心患癌症(类1)的样本。此时,我们计算的指标值就是所关心的那一类样本的,往往把我们关心的样本设定为类1。
下面,我们通过一个例子更好的了解precision和recall的计算公式和关联。
假如对于一个分类问题,我们得到混淆矩阵如下:(假设已将关心的类别设定为正类1)
| Predict | |||
| Actural | 类0 | 类1 | |
| 类0 | TN=160 | FP=30 | |
| 类1 | FN=20 | TP=60 | |
此时, a c c u r a c y = T P + T N T P + F P + T N + F N = 81.48 % accuracy=\frac{TP+TN}{TP+FP+TN+FN}=81.48\% accuracy=TP+FP+TN+FNTP+TN=81.48% p r e c i s i o n = T P T P + F P = 66.67 % precision=\frac{TP}{TP+FP}=66.67\% precision=TP+FPTP=66.67% r e c a l l = T P T P + F N = 75 % recall=\frac{TP}{TP+FN}=75\% recall=TP+FNTP=75% 若我们想要增大recall召回率,此时需要减少FN,即当我们全部猜为正例(类1):
| Predict | |||
| Actural | 类0 | 类1 | |
| 类0 | TN=0 | FP=190 | |
| 类1 | FN=0 | TP=80 | |
此时precision为29.63%,但是此时recall为100%,此时模型具有完美的召回率但精度却很差。相反,若我们想要增大precision精度,此时需要减少FP,即当我们匹配训练集中任何一个正例样本都指派为正例(类1)此时FP最小为0:
| Predict | |||
| Actural | 类0 | 类1 | |
| 类0 | TN=0 | FP=0 | |
| 类1 | FN=180 | TP=90 | |
此时recall为33.33%,但是此时precision为100%,此时模型具有完美的精度,但是recall却很差。
由上,我们得出,精度precision和召回率recall的值是此消彼长的。此时precision和recall的trade off(权衡)就显得尤为重要。我们可以通过牺牲precision来提高recall,也可以通过牺牲recall来提升precision。那我们能否找到一个指标,能够同时检验precision和recall的值呢?
这时,我们可能会想到最常用的求平均的方法,那么这个算数平均可行吗?
答案是否定的,因为算数平均数很容易受极端值的影响,而我们上面举的两个例子precision和recall的值相差较大,无法评估。
而调和平均值就发挥出了作用,通过求precision和recall的调和平均值,我们衍生出了FI-measure。
F
1
=
2
∗
p
r
e
c
i
s
i
o
n
∗
r
e
c
a
l
l
p
r
e
c
i
s
i
o
n
+
r
e
c
a
l
l
F_1=\frac{2*precision*recall}{precision+recall}
F1=precision+recall2∗precision∗recall
数值预测模型评价指标
上面介绍了分类模型的评价指标,下面我们介绍三种数值预测模型的性能评价指标。
令预测值为
y
i
^
\hat{y_i}
yi^,真实值为
y
i
y_i
yi。
1、均方误差MSE(Mean Squared Error)-最常用
M S E = 1 N ∑ i = 1 N ( y i ^ − y i ) 2 MSE=\frac{1}{N}\sum_{i=1}^{N}(\hat{y_i}-y_i)^2 MSE=N1i=1∑N(yi^−yi)2MSE均方误差对模型效能评估更加精确,能够在一定程度反映回归模型的不稳定型。
2、均方根误差RMSE(Root Mean Square Error)
R M S E = 1 N ∑ i = 1 N ( y i ^ − y i ) 2 RMSE=\sqrt{\frac{1}{N}\sum_{i=1}^{N}(\hat{y_i}-y_i)^2} RMSE=N1i=1∑N(yi^−yi)2
3、平均绝对误差MAE(Mean Absolute Error)
M A E = 1 N ∑ i = 1 N ∣ y i ^ − y i ∣ MAE=\frac{1}{N}\sum_{i=1}^{N}|\hat{y_i}-y_i| MAE=N1i=1∑N∣yi^−yi∣MAE平均绝对误差较少使用,因为其数学性能较差。
评估分类器性能的方法——数据分割
上文已经介绍了模型性能的评价指标,下面我们讨论如何在数据集角度评估分类器性能。对于已知的数据集要评价模型的好坏,如果用全部的数据建模,再用同样的数据检验模型,不可避免会让人怀疑模型的可靠性,因为,这样可能出现过拟合的情况,使得模型在训练集上表现较好,但是在新的数据集上的表现很差。对于这种情形,我们需要划分数据集,使得我们使用原始数据的一部分做训练集建立模型,另一部分用作测试集进行模型评估。
1、保持方法(Hold-out)
将被标记的原始数据划分为两个不相交的集合,分别称为训练集和检验集(测试集)。在训练集上归纳分类模型,在检验集上评估模型性能。
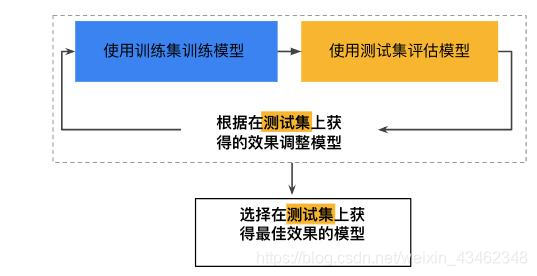
这个方法是我们接触机器学习,最先接触到的或者说在学校中最常用的方法,但是这个方法具有较多的局限:
- 用于训练的被标记样本较少,此时对于原始数据量较少的情况,训练出的模型可能较差。
- 模型可能过于依赖训练集和测试集的构成,训练集较小时模型的方差较大,容易欠拟合;训练集较大时,测试集较小,可能估计不准确。
除此之外还要避免将数据集的前一部分做训练集、后一部分做测试集,以免训练出模型自身规律,往往需要将数据集打乱再进行数据分割。
2、k-折交叉验证(cross-validation)
将原始数据(dataset)进行分为k组,每组中一部分做为训练集(train set),另一部分做为验证集(validation set or test set),再每次运行时用训练集对分类器进行训练,再利用验证集来测试训练结果,循环k轮得到k个模型(model),将其误差平均来做为评价分类器的性能指标。
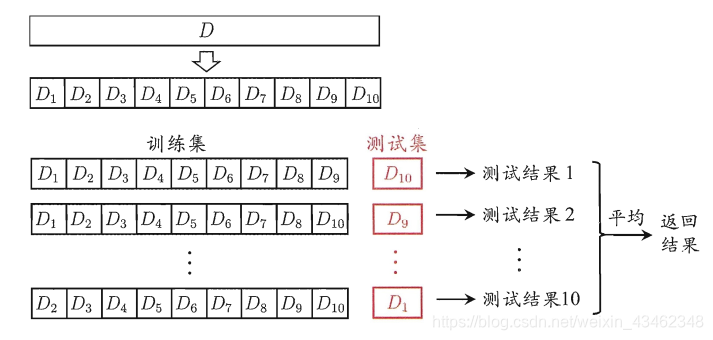
由k折交叉验证可以衍生到“留一法”,即每次测试集只保留一个样本,剩下N-1个样本做训练集,“留一法”常用于原始数据量很少的情况。
k折交叉验证的优点:
1.信息利用充分
2.每块数据集都可以使用一个算法,方便进行比较
3.最终精度为平均值,精度提升
3、自助法(bootstrap)
自助法(Bootstrap Method,Bootstrapping或自助抽样法)是一种从给定训练集中有放回的均匀抽样,也就是说,每当选中一个样本,它等可能地被再次选中并被再次添加到训练集中。
假设给定的数据集包含D个样本。该数据集有放回地抽样m次,产生m个样本的训练集。这样原数据样本中的某些样本很可能在该样本集中出现多次。没有进入该训练集的样本最终形成检验集(测试集)。 显然每个样本被选中的概率是1/m,因此未被选中的概率就是
(
1
−
1
m
)
(1-\frac{1}{m})
(1−m1),这样一个样本在训练集中没出现的概率就是m次都未被选中的概率,即
(
1
−
1
m
)
m
(1-\frac{1}{m})^m
(1−m1)m.当m
→
\rightarrow
→
∞
\infty
∞时,这一概率就将趋近于
e
−
1
=
0.368
e^{-1}=0.368
e−1=0.368,所以留在训练集中的样本大概就占原来数据集的63.2%,即为常说的0.632自助法。
数据分割总结
划分策略:
1.当数据集D的规模较大时——(通常)训练集
2
3
D
\frac{2}{3}D
32D,测试集
1
3
D
\frac{1}{3}D
31D
2.当数据集D的规模较小时——k折交叉验证法(k-fold validation)
3.当数据集D的规模非常小时——留一法(leave one out)(k-fold validation的特例:重复N次,N为样本量)
参考文献
《数据挖掘导论》
《数据挖掘概念与技术》
吴恩达机器学习课程














 482
482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









