









BufferedReader类
BufferedReader类用于从缓冲区中读取数据,所有的字节数据都将保存在缓冲区中,BufferedReader类是Reader类的实例,只能接收字符输入流的实例化对象,不理解没关系,通过一个案例就能懂~(嘿嘿)
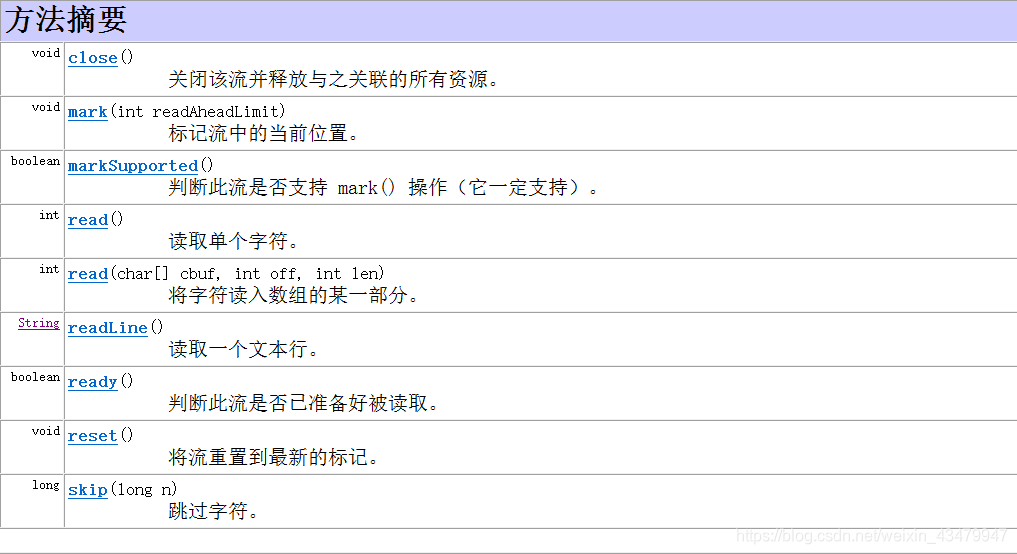
主要方法

案例演示
通过BufferedReader类实例完成无限制地接收键盘输入中文数据并将所有数据打印输出。
package chapter_twelve;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.InputStreamReader;
public class BufferedReaderDemo01 {
public static void main(String[] args) throws Exception{
BufferedReader bufferedReader = //声明BufferedReader类对象,此对象为Reader类子类
new BufferedReader(new InputStreamReader(System.in)); //实例化BufferedReader类,参数为字符输入流实例
System.out.println("请输入要读入的内容:");
String string = bufferedReader.readLine(); //接收从键盘中读取的数据
System.out.println("您输入的内容为:");
System.out.println(string); //将用户输入的数据打印出来
}
}
运行结果
请输入要读入的内容:
Hello,小高同学,别来无恙啊~
您输入的内容为:
Hello,小高同学,别来无恙啊~
总结
使用BufferedReader类通过readLine()方法可以一次性接收用户输入的全部数据或全部读取文件中的内容,也能很好地避免了中文数据拆分输入导致地乱码问题。















 6556
6556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











