







得物、百度、阿里巴巴面试题:https://java2top.cn/posts/
MySQL:
mysql中的锁:
- 按照锁的粒度分为:表级锁、行级锁
- 按照锁的区间划分:记录锁(行锁)、间隙锁、临键锁(记录锁+间隙锁)
间隙锁就是给一个范围内的间隙加锁,临键锁就是行锁+间隙锁 - mysql中的读锁和写锁就是概念上的共享锁和排他锁
sql优化
表设计的优化
- 字段设置合适类型,长短
sql语句优化
- 使用select字段名
- 尽量避免索引失效的写法
- 尽量使用union all代替union会多一个过滤,效率低
- 避免在where字句中对字段进行表达式操作
- join优化,能使用inner join就不用left或者rigint
索引失效场景
- 函数或者运算
- 联合索引范围失效
- like
- 类型不一致导致索引失效
- !=和<>导致索引失效
- or连接不同字段索引失效
- is null不走索引is not null走索引
事务里面的锁是如何释放的
共享锁的释放:
共享锁是用于读取操作的锁,它允许多个事务同时持有该锁。一旦事务完成了对共享资源的读取操作,它会释放共享锁。在大多数数据库管理系统中,共享锁会在事务结束时或在事务中释放锁的语句(例如COMMIT)执行时被释放。
排他锁的释放:
排他锁是用于写入或修改操作的锁,一次只允许一个事务持有。排他锁通常在事务结束时或在事务中执行释放锁的语句(例如COMMIT)时被释放。另外,如果一个事务在执行过程中发生了回滚(ROLLBACK),它持有的排他锁也会被释放。
锁已经释放,但是事物还没有提交
出现这种情况的原因可能是方法中事务覆盖范围大于了锁的范围,例如事务在方法级,而锁在finally中提前释放了,导致事务未完成而锁提前释放了。可以使用aop切面加锁,也可以使用编程式事务手动加锁。
mysql的锁有几种
按照粒度区分:表锁、行锁、页锁
行锁也有,记录锁、间隙锁、临键锁
还有读、写锁,共享锁和排他锁
间隙锁如何实现的
是通过在索引上对特定范围内的间隙(不存在的值的范围)进行锁定来实现的。这种锁定确保了在事务执行期间不会有新数据插入到这个范围内。
mvcc是什么
mvcc是多版本并发控制,其底层是根据隐藏字段、undo log中的版本链和readview来实现的,
隐藏字段(事务id、回滚指针、隐藏主键),
undo log主要记录每次修改后的数据会记录隐藏字段的信息,
readview是事务快照读的时候产生的数据读视图,记录并维护系统当前活跃事务的id。
mvcc是在哪个隔离级别
MVCC可用于不同的隔离级别,包括读未提交、读已提交、可重复读和串行化。不同隔离级别决定了事务能够看到的数据版本范围和行为规则。例如,可重复读隔离级别可以防止幻读问题。
mysql的索引有哪几种类型
主键索引、普通索引、唯一索引、全文索引、联合索引、前缀索引、空间索引
索引的结构,叶子节点的结构
B+树,双向链表
叶子节点在磁盘上是顺序分部的吗
是的,叶子节点在数据库索引中通常是顺序分布的。这种分布方式是为了优化查询性能,减少磁盘I/O操作的次数。
怎么查看sql是是否使用了索引
使用explain关键字查看,根据possible_keys key key_len来判断是否使用了索引已经索引的信息

type:system > const > eq_ref > ref > range > index > ALL
use index 、use where、using index condition 的区别
use index:使用索引进行查询。在这种情况下,查询的字段在索引中,因此不需要回表查询。通过索引列中的数据,可以直接查找到符合条件的结果。
use where:在第一个条件进行过滤后,同时进行了回表查询再次过滤。这是因为在查找使用索引的情况下,仍需要回表去查询所需的数据。
Using index condition:在过滤的字段在索引中的情况下,不需要回表查询,因为要过滤的数据已经在索引中,表示使用了索引下推
sql查询慢如何优化
索引、sql语句
慢查询如何查看
数据库中设置SQL慢查询
方式一:修改配置文件 在 my.ini 增加几行: 主要是慢查询的定义时间(超过2秒就是慢查询),以及慢查询log日志记录( slow_query_log)
[mysqlld]
//定义查过多少秒的查询算是慢查询,我这里定义的是2秒
long_query_time=2
#5.8、5.1等版本配置如下选项
log-slow-queries=“mysql_slow_query.log”
#5.5及以上版本配置如下选项
slow-query-log=On
slow_query_log_file=“mysql_slow_query. log”
//记录下没有使用索引的query
log-query-not-using-indexestpspb16glos dndnorte/t
方式二:通过MySQL数据库开启慢查询:
mysql>set global slow_query_log=ON
mysql>set global long_query_time = 3600;
mysql>set global log_querise_not_using_indexes=ON;
分析慢查询日志
可以通过如下命令定位低效率执行sql
show processlist;
sql 可以用 explain 分析执行计划。
对于执行计划的分析,也是面试官喜欢考察的一个点。
一条sql最多使用多少索引
一个表最多支持64个索引
mysql的索引结构画图讲一下
mysql的inoodb主要是B+树索引,它是一个多路平衡查找树
索引下推
所谓索引下推就是原本由server层处理的逻辑交给了引擎层处理
https://juejin.cn/post/7005794550862053412
最左原则是什么
主要是在联合索引上创建多个索引,索引字段必须遵循这个原则,即索引索引列必须左匹配
面试官提供了一个sql场景,要讲清楚整个sql走
上图结合索引的选择
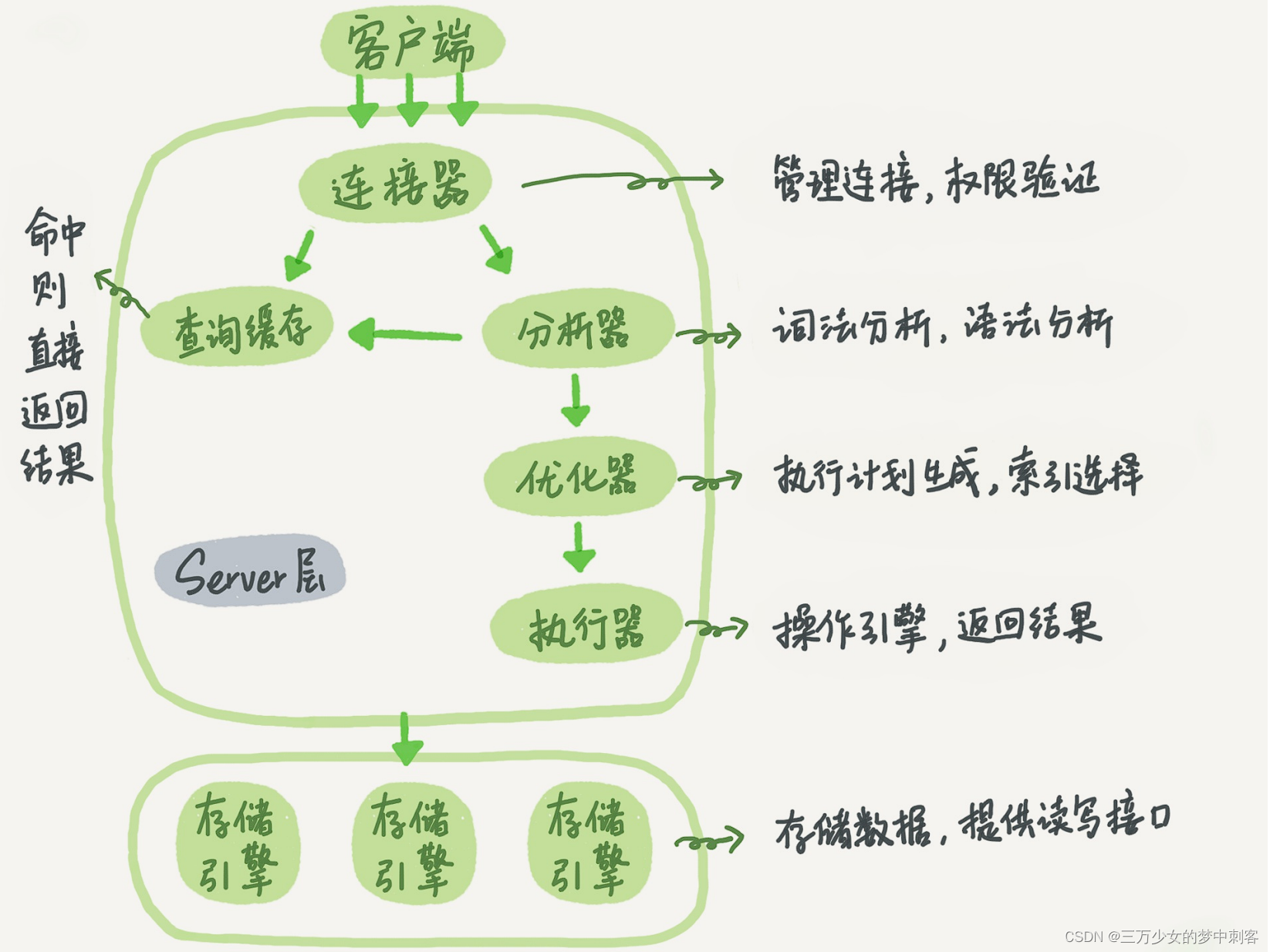
索引的执行流程
查询解析:
用户提交SQL查询语句后,MySQL首先进行查询解析。这个阶段涉及SQL语法检查、语义分析等,确保SQL语句的正确性。
查询优化:
在这个阶段,MySQL会对已解析的查询进行优化,生成一个最优的执行计划。这包括选择最适合的索引,决定表的访问顺序,以及优化连接操作等。
执行计划生成:
在优化阶段,MySQL会生成一个执行计划(Execution Plan),这个执行计划描述了执行查询所需的操作步骤和顺序。它决定了如何访问表,使用哪些索引,以及执行操作的顺序。
执行计划执行:
根据生成的执行计划,MySQL执行实际的查询操作。这包括访问表、使用索引、筛选和排序数据等。
删除一条数据,索引会变吗
会
mysql加锁,锁的是什么,怎么锁
例如表锁(锁表)、行锁(锁行)、间隙锁(锁的行之间的间隙)、临键锁(锁范围)等
死锁是什么
互斥条件:进程或线程对资源的访问是排他性的,即一次只能由一个进程或线程占用。
占有且等待:进程或线程已经占有了资源,同时又在等待其他进程或线程占有的资源。
不可抢占:资源不能被强制性地抢占,只能由占有该资源的进程或线程主动释放。
循环等待:存在一个进程或线程的资源请求链,使得每个进程或线程都在等待下一个进程或线程所持有的资源。
undo log、redo log、binglog
undo log主要记录一些数据更新后的回滚语句
redo log主要记录数据页的物理变化,主要用来恢复数据
binlog主要用户同步数据
binglog结构类型有哪些
基于语句、基于数据、混合
为什么用rc
https://blog.csdn.net/qq_39380192/article/details/119335308
1、在RR隔离级别下,存在间隙锁,导致出现死锁的几率比RC大的多;
2、在RR隔离级别下,条件列未命中索引会锁表!而在RC隔离级别下,只锁行;
3、在RC隔离级别下,半一致性读(semi-consistent)特性增加了update操作的并发性;
rc和rr区别
同上
mvcc和临建锁
mvcc见前文,临键锁是指行锁和间隙锁的组合
为什么数据库字段不要存太大的
首先就是占用空间,影响查询效率,当一个字段存储太大的话会可能会占用多个页从而导致读取这个字段要多次io操作
Redis:
redis中的分布式锁
- setnx
- redisson
juc里面的类用过哪些
主要有五类
- 线程池相关的,四个线程池
- 线程安全的集合,ConcurrentHashMap,CopyOnWriteArrayList,CopyOnWriteArraySet等
- 原子类,
- 线程间通讯工具类,Semaphore(信号量,限制线程的数量)、Exchanger(交换线程间数据)、CountDownLatch(线程等待直到计数器减为0时开始工作)、CyclicBarrier(循环的屏障,和前一个类似,但是可以重复利用)
- 锁,ReentrantLock
分布式锁怎么实现
- redis的setnx实现
- mysql的唯一索引
redission的看门狗机制
主要用于在锁快过期时用于给锁续约,大约到锁时长的三分之一时间。
分布式锁过期情况如何解决
同上
分布式锁的使用
-
选择合适的分布式锁实现:
选择适合你应用场景的分布式锁实现,常见的有基于数据库、ZooKeeper、Redis等实现的分布式锁。 -
获取锁:
在需要加锁的代码块中,尝试获取分布式锁。不同的分布式锁实现可能有不同的获取锁方式,比如在Redis中可以使用SETNX命令或Redlock算法。 -
执行业务逻辑:
一旦成功获取锁,执行业务逻辑,对共享资源进行访问、修改等操作。 -
释放锁:
无论业务逻辑执行成功或失败,都需要释放锁,确保锁不会被长时间占用。释放锁的方式由具体的分布式锁实现决定。
redis如何扩容
大key如何解决
使用unlink异步删除
不使用mq如何实现消息重试
redis为什么快
基于内存、单线程、IO多路复用
缓存击穿怎么办
缓存击穿是指原先key存在然后过期后直接到数据库
1、使用布隆过滤器
2、设置热点数据永不过期
3、使用多级缓存
redis数据结构有哪些
string、hash、list、set、zset加上另外三种高级数据结构HyperLogLog、GEO、bitmap
sortset底层结构
zset底层的存储结构包括ziplist或skiplist,在同时满足以下两个条件的时候使用ziplist,其他时候使用skiplist,两个条件如下:
- 有序集合保存的元素数量小于128个
- 有序集合保存的所有元素的长度小于64字节
JAVA:
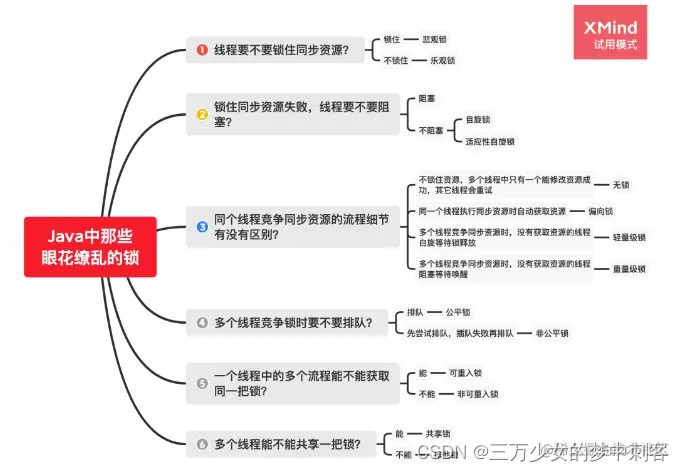
用过哪些锁
按照概念来说:
- 乐观锁和悲观锁
线程要不要锁住同步资源? - 独占锁和共享锁
锁住同步资源后,线程要不要阻塞? - 互斥锁和读写锁
同个线程竞争同步资源的流程细节有没有区别? - 公平锁和非公平锁
多个线程竞争锁时要不要排队?
四种线程池
newSingleThreadExecutor 返回单个线程的线程池,再提交的话就进到任务队列
newFixedThreadPool 返回指定数量的线程池,线程池中的线程数量不变,再提交进入任务队列
newCachedThreadPool 返回一个可根据实际情况生成线程的线程池,初始为0,如果一段时间内没有任务提交,默认60s,就会销毁线程
newScheduledThreadPool 返回一个延迟执行或定时执行的线程池
java中的锁:
- 可重入锁
ReentrantLock和synchronized都是可重入锁 - 自旋锁
循环利用CAS获取锁,而不是阻塞,避免线程的上下文切换 - 锁的升级(无锁、偏向锁、轻量级锁、重量级锁)
主要是synchronized在java6之后做的优化,
无锁就是没有线程竞争,
偏向锁就是只有一个线程持有锁,jvm会记录该线程的线程id,下次该线程就不需要竞争这个锁直接进入临界区,
轻量级锁就是存在锁的竞争,线程会尝试使用CAS获取锁,这里也涉及到自旋锁,如果CAS获取不到锁,会进入自旋状态,如果自旋不成功就会转化为重量级锁
重量级锁就是基于操作系统底层提供的互斥机制。 - 锁优化(锁粗化、锁消除)
锁粗化就是将锁的范围变大,锁消除就是将锁范围变小甚至消除。
有了解过ags吗
aqs是抽象队列同步器,其主要维护了一个state锁的状态和一个可阻塞的队列(CLH),这个队列是由双向链表实现的,每个节点保存了以线程的引用和一些其他信息,通过自旋和CAS来操作保证节点插入和移除的原子性
aqs采用的是什么设计模式
模板设计模式
java的引用类型有哪些,介绍一下
强引用:对象在有强引用下不会被GC回收,如果需要回收需要将对象赋值为null
软引用:当jvm内存不够的时候会被GC回收
弱引用:无论内存是否足够,只要JVM开始进行垃圾回收,软引用关联的对象就会被回收
虚引用:随时都有可能被回收
threadlocal是什么?有什么问题
为每个线程都分配了一个独立的副本,用于保存当前线程的数据,其底层维护了一个ThreadlocalMap,其key是当前线程,value就是传入的值
因为threadlocalMap中的key是弱引用,而value是强引用,可能导致内存泄漏,在使用时务必使用remove方法清楚
spring的事务传播
- 默认是若不存在事务就新建一个事务存在就加入(REQUIRED)
- 如果当前存在事务就挂起事务,不存在就新开一个事务(REQUIRES_NEW)
- 如果当前存在事务就嵌套运行,不存在就和第一个一样(NESTED)
- 如果当前存在事务就加入事务,不存在就抛出异常(MANDATORY)
- 如果当前存在事务就加入,不存在就以非事务运行(SUPPORTS)
- 以非事务方式运行,如果当前存在事务,则把当前事务挂起(NOT_SUPPORTED)
- 以非事务方式运行,存在就抛出异常(NEVER)
spring的beanfactory和factorybean对象区别
beanfactory是spring中的一个接口,主要是管理和查找bean,不负责bean的创建
factorybean也是一个接口,允许用户自定义bean的创建逻辑,它的实现类可以用于创建bean
怎么把jvm方法区内存撑爆
方法区:主要存储类信息、常量池等。要使方法区溢出,可以创建大量的类或字符串常量。
堆:用于存储对象实例。可以通过创建大量对象或者不释放对象来使堆溢出。
栈:用于方法调用和局部变量。要使栈溢出,可以创建递归深度很大的方法。
gc的日志主要关注哪些内容
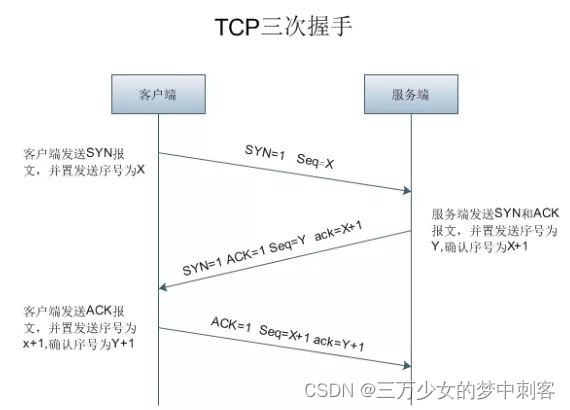
tcp三次连接画一下
dubbo服务调用过程
服务提供者注册:服务提供者将自身的服务注册到注册中心。
服务消费者订阅:服务消费者从注册中心订阅所需服务的提供者列表。
负载均衡:消费者根据负载均衡策略选择一个提供者。
远程调用:消费者通过网络远程调用选定的提供者。
数据传输:调用参数、返回结果等数据在消费者和提供者之间传输。
执行服务逻辑:提供者执行具体的服务逻辑。
返回结果:提供者将执行结果返回给消费者。
spring的生命周期
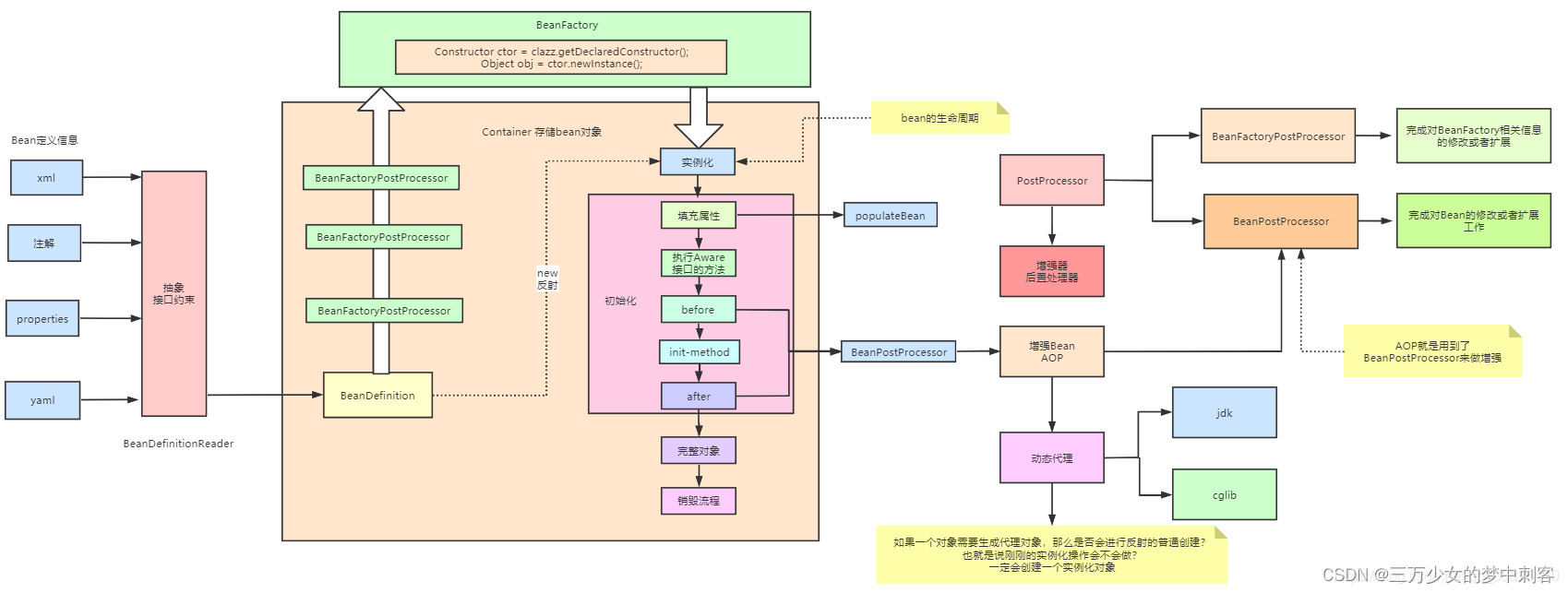
- xml文件或者注解通过BeanDefinition获取到bean的定义信息
- 调用构造函数实例化bean
- bean的依赖注入
- 处理Aware接口(BeanNameAware、BeanFactoryAware、ApplicationContextAware)
- Bean的后置处理器BeanPostProcessor-前置
- 初始化方法(InitializingBean、init-method)
- Bean的后置处理器BeanPostProcessor-后置
- 销毁bean
用过spring哪些扩展点

- 在BeanDefinition后有一个BeanFactoryPostProcessor后置处理器
- 在Bean初始化前后也有BeanPostProcessor后置处理器
- 在处理Aware接口时也有几个扩展点,BeanNameAware、BeanFactoryAware、ApplicationContextAware
- 在bean创建完成后、所有属于注入完成后有个InitializingBean扩展点
- DisposableBean在bean销毁的扩展点
- ApplicationListener是在spring容器初始化时的一个扩展点
两种代理方式
- jdk动态代理:
它基于接口生成代理对象。要使用JDK动态代理,需要满足以下条件:
被代理的类必须实现一个或多个接口。
使用java.lang.reflect.Proxy类和java.lang.reflect.InvocationHandler接口来创建代理对象。 - cglib代理:是基于字节码生成的代理机制,它可以代理没有实现接口的类。CGLIB通过继承被代理类来创建代理对象,重写被代理类的方法,并在方法中添加额外的逻辑。
ReentrantLock和synchronized区别
用法不同:synchronized 可以用来修饰普通方法、静态方法和代码块,而 ReentrantLock 只能用于代码块。
获取锁和释放锁的机制不同:synchronized 是自动加锁和释放锁的,而 ReentrantLock 需要手动加锁和释放锁。
锁类型不同:synchronized 是非公平锁,而 ReentrantLock 默认为非公平锁,也可以手动指定为公平锁。
响应中断不同:ReentrantLock 可以响应中断,解决死锁的问题,而 synchronized 不能响应中断。
底层实现不同:synchronized 是 JVM 层面通过监视器实现的,而 ReentrantLock 是基于 AQS 实现的。
lock锁的底层实现
aqs+cas+公平锁或者非公平锁
线程池执行流程
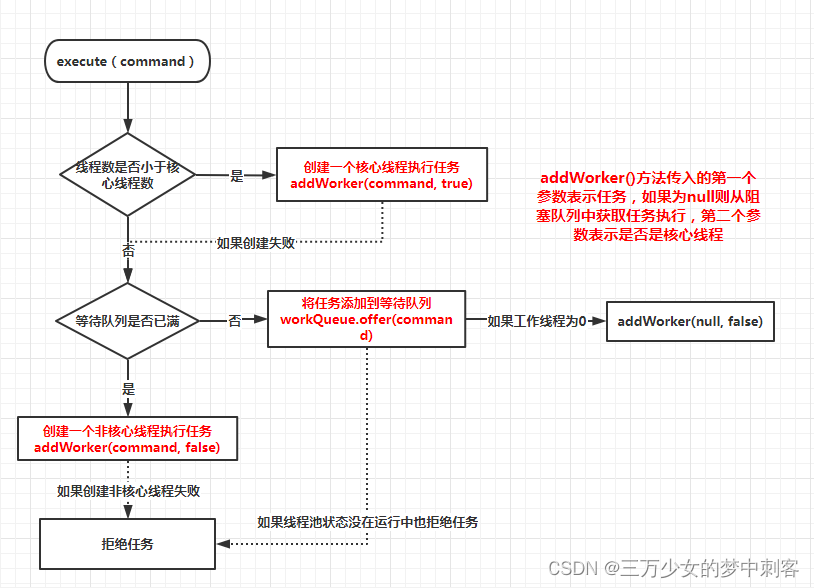
https://zhuanlan.zhihu.com/p/201427009
设计模式
参考地址:https://refactoringguru.cn/design-patterns
MQ:
rocketmg失败重试怎么做的
捕获异常: 在发送消息的代码块中,捕获可能的异常,如MQClientException或RemotingException。
设置重试次数和间隔: 在捕获异常后,可以设置一个重试次数的阈值和重试间隔,以确保不会无限制地重试。
重试逻辑: 在捕获异常后,判断是否达到重试次数阈值,若未达到则进行重试。重试时,可以重新构造消息并发送。
日志记录: 在每次重试时,记录相应的日志,包括重试次数、消息内容等信息。
消费者组的作用是什么?
-
并行处理:
允许多个消费者以组的形式同时订阅同一个主题(topic),并行处理消息。这样可以提高消息处理的吞吐量和效率。 -
负载均衡:
Kafka通过分配不同分区(partition)给消费者组的不同消费者来实现负载均衡。每个分区只能被同一消费者组内的一个消费者消费,但一个消费者组可以消费多个分区,以确保负载均衡。 -
消费者扩展和缩减:
允许动态地增加或减少消费者,而不会影响整体消息处理。新的消费者加入时,它们会重新分配分区以保持负载均衡。 -
提供高可用性和容错性:
消费者组在Kafka集群中提供高可用性。如果一个消费者下线,其分区会被重新分配给其他活跃的消费者,确保消息的消费不受影响。
消息堆积问题解决
最简单的就是增加消费者处理(增加分区的同时增加消费者实例)
在无法优化消费者端代码情况下,可以先将堆积的消息导入到新的队列中,避免阻塞业务
kafka中实现高性能的设计
消息分区:存储不受单台服务器的限制,数据量大的时候可以分段存储
顺序读写:磁盘顺序读写文件
页缓存:使用页内存缓存中间数据,最后在刷盘
零拷贝:从页内存中直接将消息发送到网卡
消息压缩:减少磁盘IO和网络IO
消息分批发送:将消息打包分批发送,减少网络IO
其他:
实现幂等有哪些方法
-
唯一标识符(Unique Identifier):
为每个请求生成唯一的标识符(例如,UUID),并在服务端记录已处理的标识符。在接收到请求时,首先检查标识符是否已经被处理过,如果是,则直接返回之前的结果,如果不是,则处理请求并记录标识符。 -
幂等接口设计:
在设计API时,应该考虑将幂等性作为设计原则。合理的API设计应该允许相同的请求重复执行而不产生副作用。 -
版本控制:
使用版本控制机制来确保请求的幂等性。每个请求可以携带一个版本号或时间戳,服务端根据版本号来判断是否处理请求。 -
乐观锁:
在数据库操作中,可以使用乐观锁机制,将版本号或时间戳与数据关联。在更新数据时,只有当版本号匹配时才执行更新操作,否则拒绝请求。 -
使用幂等HTTP方法:
HTTP协议中的GET、PUT、DELETE等方法是幂等的,因此在设计RESTful API时,应该根据幂等性要求选择合适的HTTP方法。 -
幂等性标志:
在请求中包含一个幂等性标志或标识,服务端根据该标识来判断是否处理请求。 -
幂等性响应:
服务端可以在响应中包含一个标识,表示该响应是一个已处理请求的结果,客户端在接收到响应后可以根据该标识来识别重复的响应。
如何避免恶意请求?网关黑白名单
分布式最终一致性,软状态
最终一致性:
最终一致性是一种弱一致性模型,它允许分布式系统中的副本在一段时间内可能是不一致的,但最终会达到一致的状态。在最终一致性模型下,系统保证在没有新的更新时,最终所有副本都会达到一致的状态。这种模型允许系统在更新过程中保持高可用性和性能。
软状态:
软状态是指在分布式系统中,节点之间的状态可能会随时间变化而改变,而这些状态变化是暂时的,可以随时被重置或修复。软状态的特点是,即使在面对网络分区、节点故障或延迟等情况下,系统仍然能够正常工作,状态可以通过一定的机制进行修复。
多线程状态、时间片轮训
就绪、阻塞、运行、等待、销毁
时间片轮询是一种多任务调度算法,常用于操作系统对多线程或多进程的调度。每个线程或进程被分配一个时间片,在该时间片内执行,时间片结束后,系统切换到下一个线程或进程继续执行。这样可以实现多任务并发执行,提高系统的响应速度和资源利用率。
分布式锁的可重入如何实现
需要在分布式环境下考虑线程身份的唯一标识。通常,分布式锁会将线程的唯一标识与锁绑定,以确保同一个线程可以多次获取锁。这可以通过将线程标识信息放入锁的值中实现,或者在分布式锁的数据结构中维护线程标识信息。
oom如何处理
参考文章:https://blog.csdn.net/o9109003234/article/details/121917786
jmap -heap [PID] 查看jvm内存分配情况
jmap -histo:live [PID] | more 在 JVM 运行时查看最耗费资源的对象
方案存在局限性,因为它只能排查对象占用内存过高问题
因此使用dump文件分析:
jmap -dump:file=./jvmdump.hprof(dump文件名) [PID] 导出dump文件
利用JvisualVM或者jconsole工具分析dump文件
cup飙高如何定位
参考文章:https://www.cnblogs.com/dennyzhangdd/p/11585971.html
-
执行“top”命令:查看所有进程占系统CPU的排序。极大可能排第一个的就是咱们的java进程(COMMAND列)。PID那一列就是进程号。
-
执行“top -Hp 进程号”命令:查看java进程下的所有线程占CPU的情况。
-
执行“printf "%x\n 10"命令 :后续查看线程堆栈信息展示的都是十六进制,为了找到咱们的线程堆栈信息,咱们需要把线程号转成16进制。例如,printf "%x\n 10-》打印:a,那么在jstack中线程号就是0xa.
-
执行 “jstack 进程号 | grep 线程ID” 查找某进程下-》线程ID(jstack堆栈信息中的nid)=0xa的线程状态。如果““VM Thread” os_prio=0 tid=0x00007f871806e000 nid=0xa runnable”,第一个双引号圈起来的就是线程名,如果是“VM Thread”这就是虚拟机GC回收线程了
-
执行“jstat -gcutil 进程号 统计间隔毫秒 统计次数(缺省代表一致统计)”,查看某进程GC持续变化情况,如果发现返回中FGC很大且一直增大-》确认Full GC! 也可以使用“jmap -heap 进程ID”查看一下进程的堆内从是不是要溢出了,特别是老年代内从使用情况一般是达到阈值(具体看垃圾回收器和启动时配置的阈值)就会进程Full GC。
-
执行“jmap -dump:format=b,file=filename 进程ID”,导出某进程下内存heap输出到文件中。
本地缓存使用场景
保存不怎么更新的数据,避免网络延迟
多个服务如何刷新本地缓存
当一个本地缓存更新后可以通过消息队列的发布订阅模式更新其他服务的本地缓存
es索引创建
RESTFul API 中使用put /your_index_name方式和代码中使用CreateIndexRequest
es如何存数据
RESTFul API 中使用PUT /your_index_nam/_doc/{文档id}
代码中使用bulk批量导入
mysql删除的数据,es怎么弄
使用mq同步

















 45万+
45万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











