







该篇学习笔记来自于《你也能看得懂的python算法书》
贪心算法遵循某种既定原则,不断地采取当前条件下最优的选择来构造每一个子步骤,直到获得问题的最终求解。即在求解时,总是做出当前看来最好的选择。也就是说,不从整体最优上加以考虑,做出的仅仅是局部最优解。
利用贪心算法解题,需要解决以下两个问题。
一是该问题是否适合用贪心算法求解,即所求问题是否具有贪心选择性质。所谓贪心选择性质,是指应用同一规则,将原问题变为一个相似但规模更小的子问题,后面的每一步看似都是最佳的选择。这种选择依赖于已做出的选择,但不依赖于未做出的选择。从全局来看,运用贪心策略解决的问题在程序的运行过程中无回溯过程。
二是该问题是否有局部最优解,从而通过选择一个贪心标准,可以得到问题的最优解。
利用贪心算法解题的思路一般为:
- 建立对问题精确描述的数学模型,包括定义最优解的结构模型。
- 将问题分成一系列子问题,同时定义子问题的最优结构模型。
- 利用贪心算法原则可以确定每个子问题的
局部最优解,并根据最优解模型,用子问题的局部最优解堆叠出全局最优解。
一、硬币找零问题
问题描述:小明要去超市买棒棒糖,现在市面上有6种不同的面值的硬币,各硬币的面值分别为5分、1角、2角、5角、1元、2元,对于给定的各种面值的硬币个数和付款金额,找到使用硬币个数最少的交易方案。(为了使每次选择最大面值的贪心策略可以获得全局最优解,规定2元面值的硬币出现的次数为n)
par=[0.05,0.1,0.2,0.5,1.0,2.0]#存储每种硬币的面值,从小到大
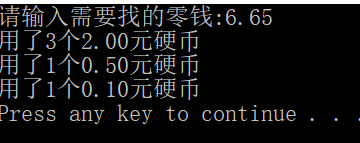
sum=float(input("请输入需要找的零钱:"))#如6.65
#从面值最大大元素开始遍历
i=len(par)-1
while i>=0:
if sum>par[i]:
n1=int(sum//par[i])
change=par[i]*n1
sum=float("%0.6f"%(sum-change))
print("用了%d个%1.2f元硬币" %(n1,par[i]))
i-=1
"%m.nf"
1 m:总宽度,包括小数点
2 n:小数部分位数
3 m>n+1, 也可以小于, 但编译结果会按实际数据输出
4 如果m过大, 会在左边补空格
执行结果如下:
二、活动安排问题
问题描述:最近,小明学校有讲座、演出、电影放映、辩论赛、考试和会议等一系列活动需要在阶梯教室举行,具体活动信息如表所示,怎样安排才能使尽可能多的各种活动得以开展呢?
| 活动 | 讲座 | 会议 | 演出 | 电影 | 辩论赛 | 考试 |
|---|---|---|---|---|---|---|
| 开始时间(s) | 1 | 3 | 0 | 5 | 3 | 7 |
| 结束时间(s) | 3 | 4 | 4 | 7 | 6 | 6 |
#冒泡排序,对结束时间进行排序,同时得到相应开始时间的list
def bubble_sort(s,f):
for i in range(len(f)):
for j in range(len(f)-1-i):
if f[j]>f[j+1]:
f[j],f[j+1]=f[j+1],f[j]
s[j],s[j+1]=s[j+1],s[j]
return s,f
def greedy_activity(s,f,n):
a=[True for i in range(n)]
j=0
for i in range(1,n):
if s[i]>=f[j]:#将该活动的起始时间与上一个活动的结束时间比较
a[i]=True
j=i
else:
a[i]=False
return a
n=int(input())#输入活动数量和活动开始、结束时间,数量和时间之间用回车分离,时间之间用空格隔开
arr=input().split()
s=[]
f=[]
for ar in arr:
ar=ar[1:-1]#将字符串的第一个元素和最后一个元素赋给ar
start=int(ar.split(',')[0])#以','为分隔符,分割一次,并取序列为0的项
end=int(ar.split(',')[1])
s.append(start)
f.append(end)
s,f=bubble_sort(s,f)
G=greedy_activity(s,f,n)
res=[]
for i in range(len(G)):
if G[i]:
res.append('({},{})'.format(s[i],f[i]))#字符串格式化,使变量以(a,b)格式输出
print(' '.join(res))#以''分隔符连接字符串
输入活动数量和活动开始、结束的时间,执行结果如下:
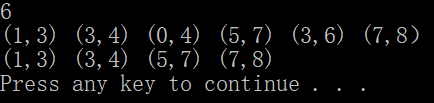
三、哈夫曼编码
问题描述:现在有一个包含5个字符的字符表{A,B,C,D,E},各个字符出现的频率统计如下表所示。
| 字符 | A | B | C | D | E |
|---|---|---|---|---|---|
| 出现概率 | 0.35 | 0.1 | 0.2 | 0.2 | 0.15 |
需要构造一种有效率的编码类型,使用该编码表达以上字符表内容时可以产生平均长度最短的位串。
#树节点定义
class Node:
def __init__(self,freq):#初始化实例的值,不要返回值
self.left=None
self.right=None
self.freq=freq
self.parent=None
#判断左子树
def isLeft(self):
return self.parent.left==self
def createNodes(frequencies):#创建叶子节点
return [Node(freq) for freq in frequencies]
def createHuffman(nodes):#创建Huffman树
queue=nodes[:]
while len(queue)>1:
queue.sort(key=lambda item:item.freq)
node_left=queue.pop(0)
node_right=queue.pop(0)
node_parent=Node(node_left.freq+node_right.freq)
node_parent.left=node_left
node_parent.right=node_right
node_left.parent=node_parent
node_right.parent=node_parent
queue.append(node_parent)
queue[0].parent=None
return queue[0]
def HuffmanEncording(nodes,root):#Huffman编码
codes=['']*len(nodes)#字符串初始化
for i in range(len(nodes)):
node_temp=nodes[i]
while node_temp!=root:
if node_temp.isLeft():
codes[i]='0'+codes[i]
else:
codes[i]='1'+codes[i]
node_temp=node_temp.parent
return codes
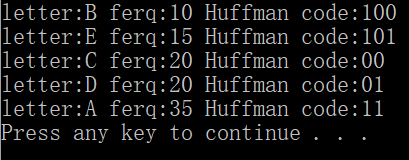
letters_freqs=[('B',10),('E',15),('C',20),('D',20),('A',35)]
nodes=createNodes([item[1] for item in letters_freqs])
root=createHuffman(nodes)
codes=HuffmanEncording(nodes,root)
for item in zip(letters_freqs,codes):#将两个数组合在一起,创建二维数组
print('letter:%s ferq:%-2d Huffman code:%s'%(item[0][0],item[0][1],item[1]))
执行结果如下:















 1811
1811











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









