







python中文短文本的预处理及聚类分析(NLP)
对于中文短文本而言,其有着单个文本词量少,文本多等特点,并且在不同的领域中中文短文本有着不同的特点。本文以已获取的微博语料出发,使用DBSCAN密度聚类,并对其进行简单可视化。
#说明:
1-本文所有程序都已实现跑通,可直接复制调试,输入的文档为文本文档.txt,编码格式为utf-8(可以在另存为之中修改编码格式,默认为ANSI),注意每一行为一个短文本样本即可。
2-本文以python3.7为语言环境,使用到的jieba,sklearn等扩展包需要提前安装好。
1 原始文本的预处理
1.1 去除文本噪音
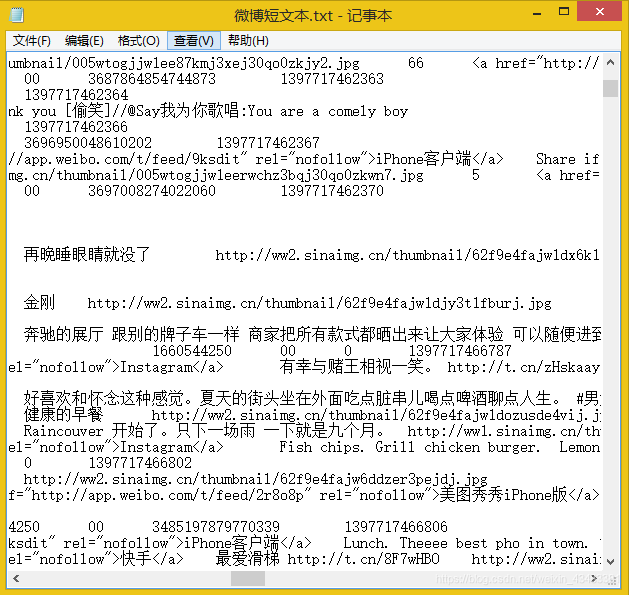
对于原始文本,总会有很多东西是我们不需要的,比如标点、网址来源、表情转换符([西瓜]、[大笑])等,如下图所示。
因此我们首先读取记事本中的内容,并按照每行的格式保存到python列表list中,代码如下所示:
import codecs
corpus = []
file = codecs.open("微博短文本.txt","r","utf-8")
for line in file.readlines():
corpus.append(line.strip())
接着,我们就可以对于储存到列表corpus中的每个预料字符串进行去噪了,在这里使用的是re库中的sub函数,为了方便阅读和修改,所以以罗列的方式展现,代码如下所示:
stripcorpus = corpus.copy()
for i in range(len(corpus)):
stripcorpus[i] = re.sub("@([\s\S]*?):","",corpus[i]) # 去除@ ...:
stripcorpus[i] = re.sub("\[([\S\s]*?)\]","",stripcorpus[i]) # [...]:
stripcorpus[i] = re.sub("@([\s\S]*?)","",stripcorpus[i]) # 去除@...
stripcorpus[i] = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+","",stripcorpus[i]) # 去除标点及特殊符号
stripcorpus[i] = re.sub("[^\u4e00-\u9fa5]","",stripcorpus[i]) # 去除所有非汉字内容(英文数字)
stripcorpus[i] = re.sub("客户端","",stripcorpus[i])
stripcorpus[i] = re.sub("回复","",stripcorpus[i])
1.2 jieba分词
接着,我们在只剩下汉语的stripcorpus列表中,将字符串长度小于5的去除,并使用jieba进行分词,代码如下所示:
import jieba.posseg as pseg
onlycorpus = []
for string in stripcorpus:
if(string == ''):
continue
else:
if(len(string)<5):
continue
else:
onlycorpus.append(string)
cutcorpusiter = onlycorpus.copy()
cutcorpus = onlycorpus.copy()
cixingofword = [] # 储存分词后的词语对应的词性
wordtocixing = [] # 储存分词后的词语
for i in range(len(onlycorpus)):
cutcorpusiter[i] = pseg.cut(onlycorpus[i])
cutcorpus[i] = ""
for every in cutcorpusiter[i]:
cutcorpus[i] = (cutcorpus[i] + " " + str(every.word)).strip()
cixingofword.append(every.flag)
wordtocixing.append(every.word)
# 自己造一个{“词语”:“词性”}的字典,方便后续使用词性
word2flagdict = {wordtocixing[i]:cixingofword[i] for i in range(len(wordtocixing))}
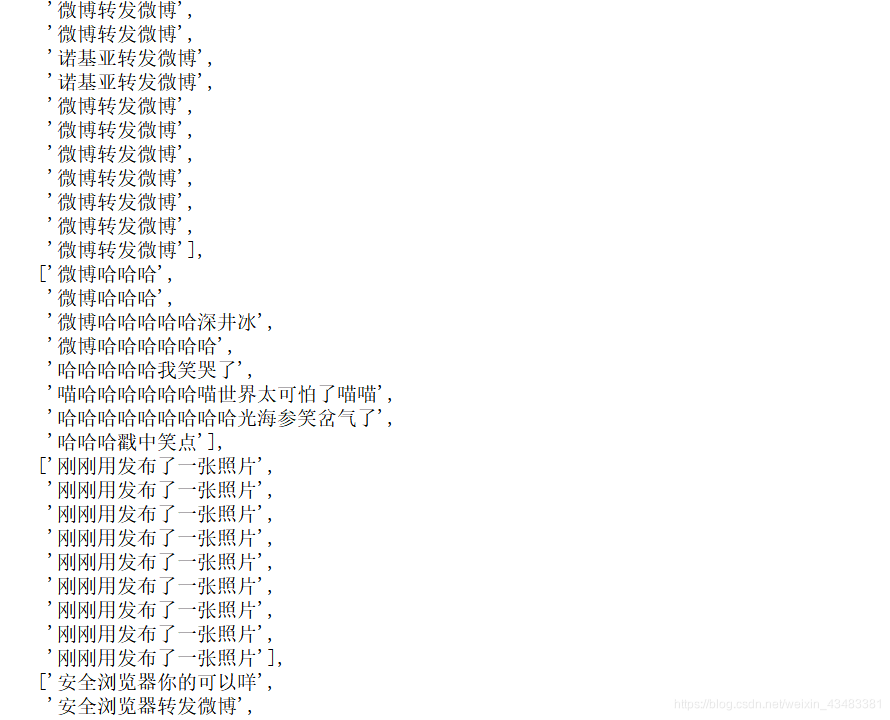
到此,我们完成了对于原始语料的基本处理,最终得到的处理后的语料列表和词性字典如下图所示。


可以看到上面的cutcorpus语料库中,有一些词语是我们不需要的(如“我”,“了”等),因为后续在进行特征提取时会按照词性进行权重赋值,所以在这里并没有按照专用词和停用词词典进行筛选。
2 短文本特征提取
说到短文本的特征提取,最著名也是目前用的最多普适性最强的就是TF-IDF的词频特征提取了,当然对于不同类型的短文本TF-IDF方法有着不一样的缺点,因此在短文本特征提取这一块有着很多各式各样的小论文,改参数,改进公式,就可以写一篇小论文了,但是这些论文中真正具有普适性的较少。
在这里,我们首先使用标准的python sklearn库中的TfidfTransformer和CountVectorizer来获取每个短文本的特征向量,从而组成整个样本特征X,代码如下所示:
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
transformer = TfidfTransformer()#该类会统计每个词语的tf-idf权值
#第一个fit_transform是计算tf-idf 第二个fit_transform是将文本转为词频矩阵
tfidf = transformer.fit_transform(vectorizer.fit_transform(cutcorpus))
#获取词袋模型中的所有词语
word = vectorizer.get_feature_names()
#将tf-idf矩阵抽取出来,元素w[i][j]表示j词在i类文本中的tf-idf权重
weight = tfidf.toarray()
其中weight就是特征矩阵X,word是X中每一维度特征对应的词。weight的大小在这里是(20097205),word的大小(72051)。其实到这里,已经可以用weight去聚类了,但是要知道在短文本中TF-IDF方法本质是提取词语的形状,和词语出现的顺序是无关的,所以从特征提取的角度而言是缺失了部分特征。
所以在这里,我们将word中每个词语的词性,通过自定义的方式赋给它们不同的权重,并乘到weight上的每一行样本中,进而改变它们的特征矩阵。这样做的目的其实是想让特征矩阵的区分能力增强一点,代码如下所示:
wordflagweight = [1 for i in range(len(word))] #这个是词性系数,需要调整系数来看效果
for i in range(len(word)):
if(word2flagdict[word[i]]=="n"): # 这里只是举个例子,名词重要一点,我们就给它1.1
wordflagweight[i] = 1.2
elif(word2flagdict[word[i]]=="vn"):
wordflagweight[i] = 1.1
elif(word2flagdict[word[i]]=="m"): # 只是举个例子,这种量词什么的直接去掉,省了一步停用词词典去除
wordflagweight[i] = 0
else: # 权重数值还要根据实际情况确定,更多类型还请自己添加
continue
import numpy as np
wordflagweight = np.array(wordflagweight)
newweight = weight.copy()
for i in range(len(weight)):
for j in range(len(word)):
newweight[i][j] = weight[i][j]*wordflagweight[j]
3 DBSCAN聚类分析
为什么使用DNSCAN聚类不使用其他聚类方法呢?其实其他聚类方法也可以,只不过这个聚类算法口碑比较好,它也有它自己的优缺点,具体可以Google一下。
其实有了特征之后,聚类是一件很简单的事情(除了调参以外)。或者换句话说聚类很简单,聚出能用的类就很难了,这需要一定的耐心和方法,话不多说,代码如下:
from sklearn.cluster import DBSCAN
DBS_clf = DBSCAN(eps=1, min_samples=6)
DBS_clf.fit(newweight)
没错,就是sklearn三步走:调包、实例化、训练。值得注意的是,DBSCAN有两个主要的参数需要调整,一个是eps(我们可以将它理解为聚类那个圈的半径),一个是min_samples(最少多少个样本可以称之为一类)。关于聚类效果的可视化,我是先将多维数据通过PCA压缩到聚类种类那么多维的数据,再通过TSNE压缩到2维来描点作图,这样效果好点,代码如下所示:
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
from sklearn.cluster import DBSCAN
def DBS_Visualization(epsnumber,min_samplesnumber,X_weight):
DBS_clf = DBSCAN(eps=epsnumber,min_samples=min_samplesnumber)
DBS_clf.fit(X_weight)
labels_ = DBS_clf.labels_
X_reduction = PCA(n_components=(max(labels_)+1)).fit_transform(X_weight) #这个weight是不需要改变的
X_reduction = TSNE(2).fit_transform(X_reduction) #每次压缩的结果都是不一样的,因为n_components在变
signal = 0
noise = 0
xyclfweight = [[[],[]] for k in range(max(labels_)+2)]
for i in range(len(labels_)):
if(labels_[i]==-1):
noise += 1
xyclfweight[-1][0].append(X_reduction[i][0])
xyclfweight[-1][1].append(X_reduction[i][1])
else:
for j in range(max(labels_)+1):
if(labels_[i]==j):
signal += 1
xyclfweight[j][0].append(X_reduction[i][0])
xyclfweight[j][1].append(X_reduction[i][1])
colors = ['red','blue','green','yellow','black','magenta'] * 3
for i in range(len(xyclfweight)-1):
plt.plot(xyclfweight[i][0],xyclfweight[i][1],color=colors[i])
plt.plot(xyclfweight[-1][0],xyclfweight[-1][1],color='#FFB6C1')
# 自适应坐标轴
plt.axis([min(X_reduction[:,0]),max(X_reduction[:,0]),min(X_reduction[:,1]),max(X_reduction[:,1])])
plt.xlabel("x1")
plt.ylabel("x2")
plt.show()
print("分类数量(含噪声-1,粉色)= "+str(max(labels_)+2)," " + "信噪比 = "+str(signal/noise)) #包括噪声一共有多少类
print("eps = "+str(epsnumber)+" ", "min_sample = "+str(min_samplesnumber))
上面是一个简单的绘制效果的函数,下面调用一下这个函数,我们随意取一对参数值eps = 0.95,min_samples = 6,使用我们的新特征newweight进行训练,代码和得到的结果如下所示:
DBS_Visualization(0.95,6,newweight)
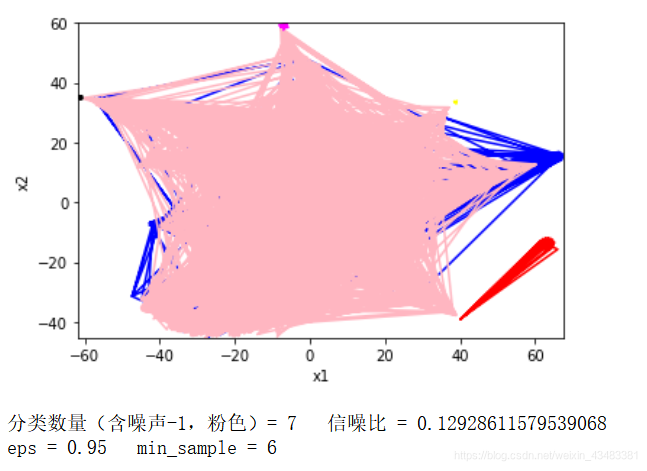
是的,这个参数聚类的效果并不好,所以还需要不断地尝试与调整参数。总的来说聚类效果主要有三个原因决定:一是文本特征的提取,二是聚类方法和参数的选择,三是语料本身的特点。本文只是做了一个初步的聚类,对于区别比较明显的大量文本数据还比较好使,但是对于不明显特征的短文本效果还有待提升,还望读者们留言批评指正。














 2216
2216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









