






说在前面
-
纯小白一个,边学边做,记录学习过程,不专业之处请见谅或能指出感激不尽。
本章与参考教程差异:
-
主要是精简步骤和补充代码,看了参考视频好几遍才操作完成。
-
本章只对纯文本进行了调用,视频中还讲解了网络图片推理,本地图片推理等等。
如果具备以下条件,就可以达成标题的目标了:
-
需具备的环境,不确定的可以先通关:从零开始,基于Autodl云服务器,通过网页与Qwen2.5-vl-7b-instruct对话-CSDN博客
-
基础镜像:PyTorch/2.3.0/3.12(ubuntu22.04)/12.1 #在创建服务器时选择
-
基础模型:Qwen2.5-VL-7B-Instruct # 通过 魔搭社区 下载后上传至服务器指定目录
-
基础项目:Qwen2-VL # 通过https://github.com/QwenLM/Qwen2-VL 下载后上传至服务器指定目录(需要科学上网,服务器不可以,建议先下载到本地再上传)
-
其他Python 包
-
pip install transformers #Hugging Face Transformers 库,用于加载和使用各种预训练的 Transformer 模型
pip install 'accelerate>=0.26.0' #Hugging Face 提供的accelerate工具,用于在多 GPU 或分布式设置下更高效地训练你的模型,并提供很多开箱即用的优化和加速功能。
pip install qwen-vl-utils[decord] #用于视觉-语言任务的工具库,支持视频数据的处理和转换同时安装了 Decord 扩展,ecord 是一个高效的视频解码库。-
AutoDL的服务器费用:5元以内。
-
半天时间
————————————————
目录
安装包与配置环境
通过无卡模式登录AutoDL服务器,在终端执行如下命令:
pip install transformers==4.49.0 # 不带版本编号安装的应该是4.51.3(可以使用 pip show transformers 命令查看),需要升级到 4.49.0
pip install requests # 用于简化 HTTP 请求的发送和接收
pip install vllm #一个开源的大语言模型(LLM)推理与部署框架,旨在通过优化内存管理和计算效率,显著提升模型推理的吞吐量和资源利用率。
pip install --upgrade numpy mkl-service #numpy:这是一个用于科学计算的 Python 库,提供了高效的数组运算功能,是许多机器学习和数据科学工具的基础。mkl-service:这是一个与 Intel Math Kernel Library (MKL) 相关的工具包,它提供了与 MKL 的接口,MKL 是一个高度优化的数学库,用于加速数值计算(例如线性代数、傅里叶变换等)。mkl-service 主要用于帮助 numpy 在计算时使用 Intel MKL 来提高性能。
export MKL_SERVICE_FORCE_INTEL=1 #设置一个环境变量,强制让 mkl-service 使用 Intel MKL(Math Kernel Library)作为计算加速库,作用:一强制使用 Intel MKL,二绕过可能的兼容性问题。启动vllm(单卡)
通过无卡模式登录AutoDL服务器,在终端执行如下命令:
cd /root/autodl-tmp/Qwen #进入模型文件夹所在位置
vllm serve Qwen2.5-VL-7B-Instruct --dtype auto --port 6006 --limit_mm_per_prompt image=4 --max_model_len 8784 --gpu_memory_utilization 0.8
#Qwen2.5-VL-7B-Instruct:模型文件夹名称
#dtype:数据类型,一般直接auto就可以了,低版本的显卡可能需要自己设置,如2080要设置为half
#port:端口号
#limit_mm_per_prompt image=4,默认是1,这样每次请求可以输入多张图片
#max_model_len:每次全球最大的token长度,爆显存了就改小
#gpu_memory_utilization:GPU最大利用率,爆显存了就改小,我现在一般设置为0.7-0.8建立隧道连接
如下图所示,获取实际的 远程主机的用户名和地址和 指定端口号 并将其替换下面的命令
ssh -CNg -L 8000:127.0.0.1:6006 #远程主机的用户名和地址# -p #指定端口号# #该命令通过 SSH 建立一个隧道连接,将本地 8000 端口的请求转发到远程服务器的 6006 端口,例:ssh -CNg -L 8000:127.0.0.1:6006 root@connect.westx.seetacloud.com -p 53340。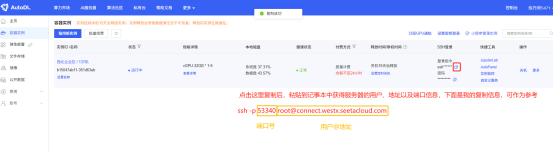
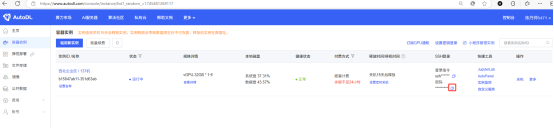
如下图所示,在自己电脑的命令行窗口中执行ssh命令

如下图所示,复制密码
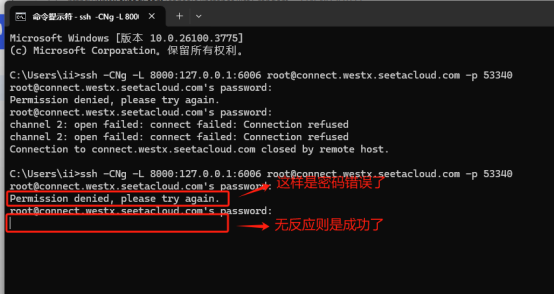
如下图所示,填入密码,无任何反应则为成功
本地调用
纯文本调用
参考的python代码如下
import requests
import json
from PIL import Image
import base64
# 1.url
url = 'http://127.0.0.1:8000/v1/chat/completions' # 你的IP
# 2.data
data = {"model": "Qwen2.5-VL-7B-Instruct",
"messages": [{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."}, # 系统命令,一般不要改
{"role": "user",
"content": "什么是大语言模型"}], # 用户命令,一般改这里
"temperature": 0.7,"top_p": 0.8,"repetition_penalty": 1.05,"max_tokens": 1024}
# 3.将字典转换为 JSON 字符串
json_payload = json.dumps(data)
# 4.发送 POST 请求
headers = {'Content-Type': 'application/json'}
response = requests.post(url, data=json_payload, headers=headers)
# 5.打印响应内容
print(response.json().get("choices", [])[0].get("message", []).get("content", [])) # 命令行启动,用这个打印
# print(response.json())调用结果如下图所示:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









