






说在前面
-
纯小白一个,边学边做,记录学习过程,不专业之处请见谅或能指出感激不尽。
-
这篇是我自己的尝试,咱们学习这个肯定不限于部署一个官方模型,于是乎我就想通过vllm把训练过的模型发布出去,没想到还成功了,只是通过命令执行的方式发布后仅支持语言模型了
-
这篇的操作就没有4.1的详细了只写了关键步骤。
如果具备以下条件,就可以达成标题的目标了:
-
AutoDL的服务器费用:5元以内。
-
半天时间(其实蛮简单的,只是找bug花了些时间)
————————————————
启动vllm(单卡,带lora权重)
直接指定lora模型路径先试一下能否启动
vllm serve Qwen2.5-VL-7B-Instruct --dtype auto --port 6006 --limit_mm_per_prompt image=4 --max_model_len 8784 --gpu_memory_utilization 0.8 --enable-lora --lora-modules lora1=/root/autodl-tmp/Qwen/Qwen2.5-VL/output/Qwen2_5-VL-7B/checkpoint-183这里直接执行会报错:ValueError: Call to add_lora method failed: LoRA rank 64 is greater than max_lora_rank 16.
意思是: 我执行的这个LoRA 配置使用一个 rank 为 64 的适配器,但系统中配置的最大 LoRA rank 限制为 16。
修改lora_rank重新训练
于是我修改了tran.py这个训练脚本,如下图所示
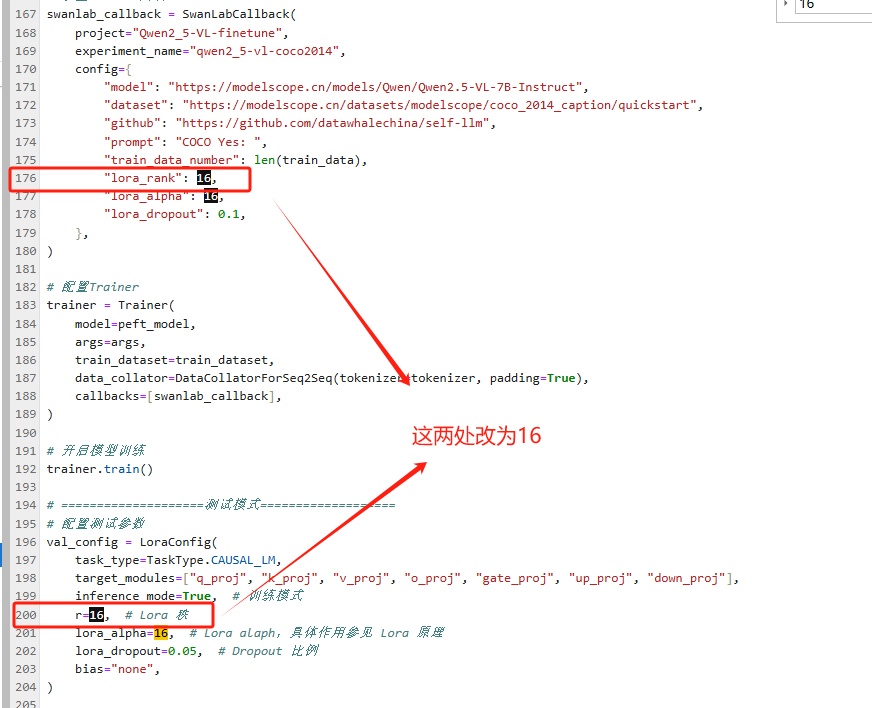
如下图所示,执行训练脚本
python tran.py 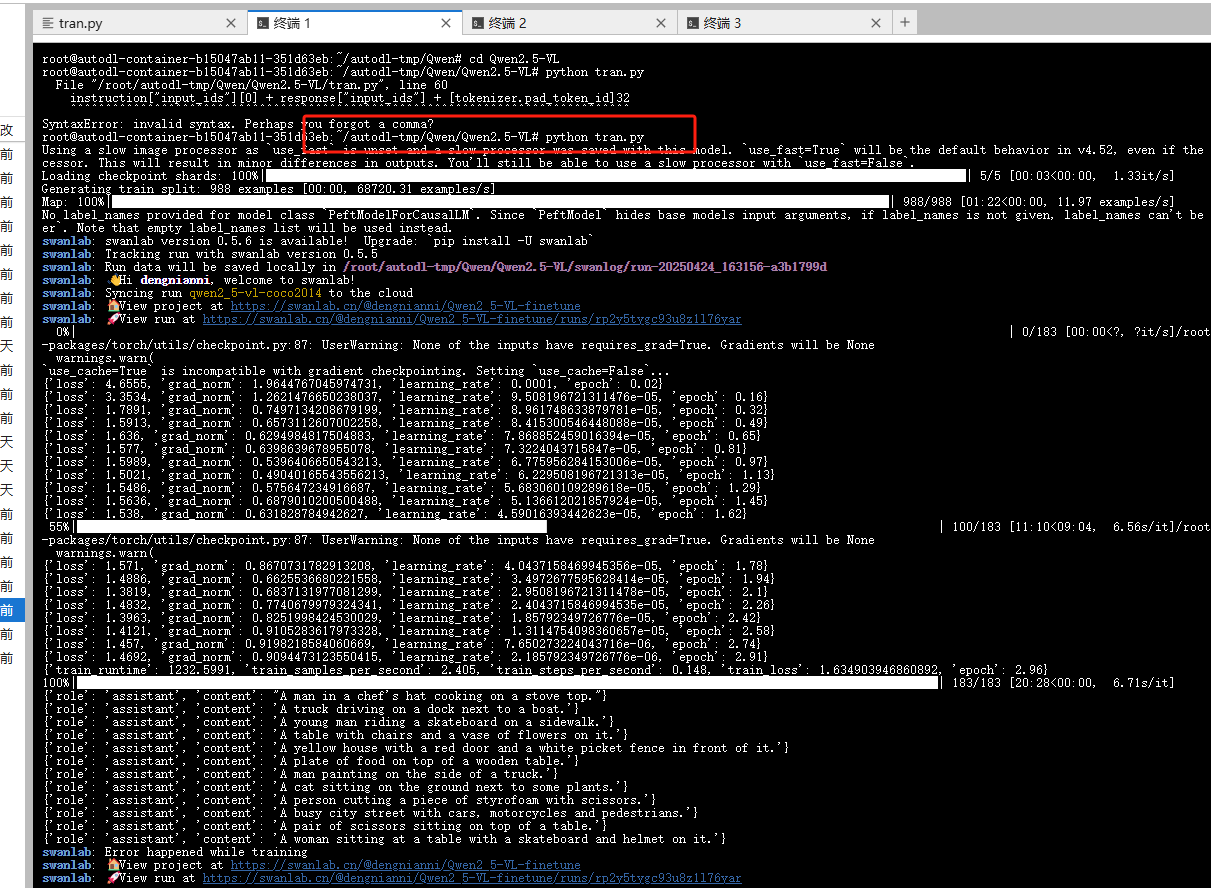
再次启动vllm(单卡,带lora权重)
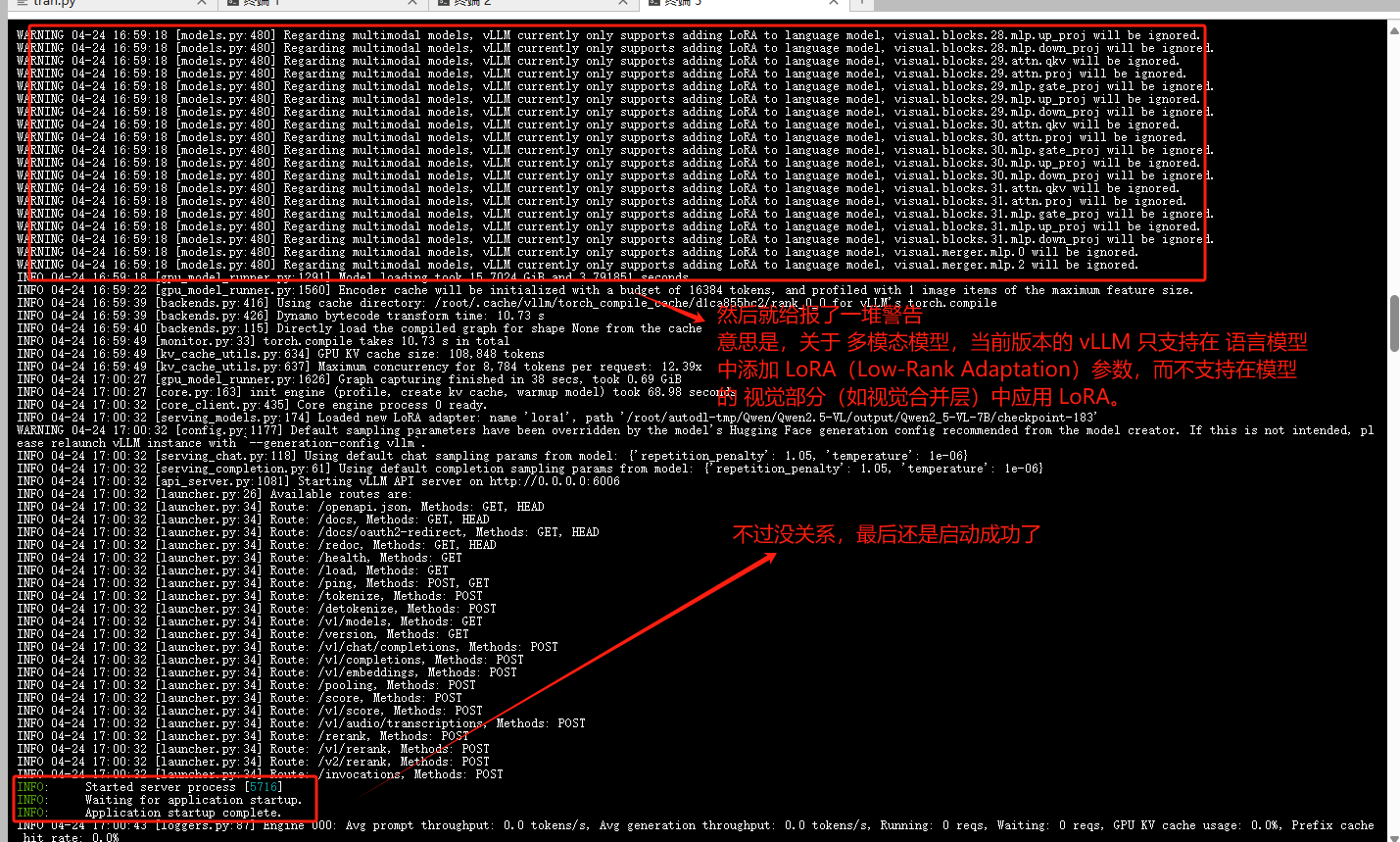
再次执行vllm启动命令
vllm serve Qwen2.5-VL-7B-Instruct --dtype auto --port 6006 --limit_mm_per_prompt image=4 --max_model_len 8784 --gpu_memory_utilization 0.8 --enable-lora --lora-modules lora1=/root/autodl-tmp/Qwen/Qwen2.5-VL/output/Qwen2_5-VL-7B/checkpoint-183如下图所示,一堆警告,不过最后还是执行成功了。
建立隧道连接
参考如下命令,获取实际的 远程主机的用户名和地址和 指定端口号 ,在自己电脑上的命令行界面执行
ssh -CNg -L 8000:127.0.0.1:6006 #远程主机的用户名和地址# -p #指定端口号# #该命令通过 SSH 建立一个隧道连接,将本地 8000 端口的请求转发到远程服务器的 6006 端口,例:ssh -CNg -L 8000:127本地调用lora模型
调用下试试,还是可以调用成功的,只不过lora模型调用的结果看起来更简洁。
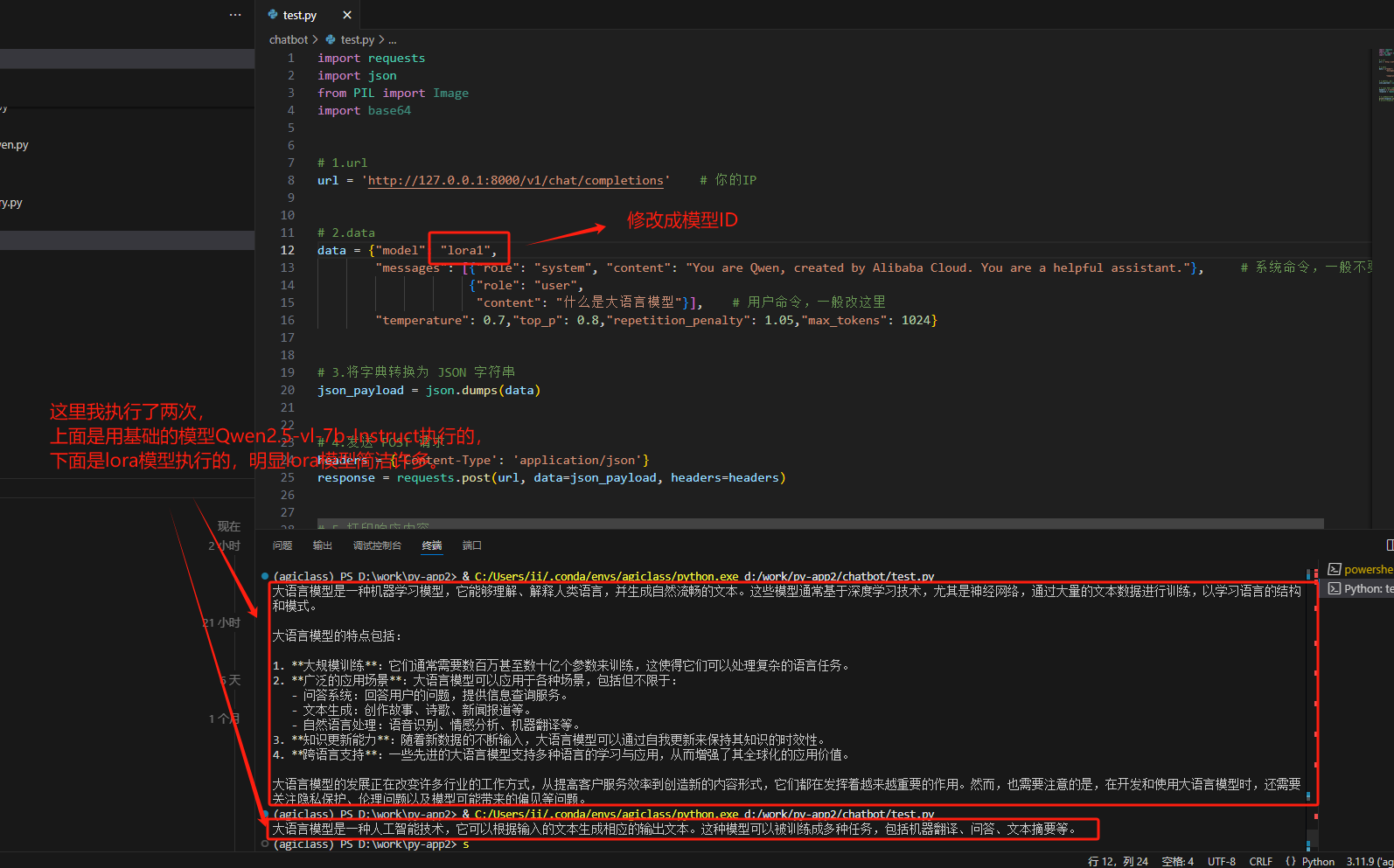

















 4657
4657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









