







python——自动化报告word(1)
本文基于python的docx模块的文本替换功能,自动引用excel数据填入word,实现报告自动化。
前言
需要提前安装docx模块。
# 在终端中输入
pip install python-docx
# 或者在jupyter notebook中输入
!pip install python-docx
提示:以下是本篇文章正文内容,下面案例仅供参考学习
一、思路
1.读取word模板;
2.读取预先统计整理好的字典数据;
3.根据指定文本内容(键)和黄色高亮文本格式,替换相应的内容;
4.输出word报告。
二、准备文件
1.模板
word模板为docx格式,约定两个相邻索引分隔符为“#”,用于指明需要替换的文字部分(含表格内容)。图中模板高亮文本部分为索引,为文字替换的定位依据,除实质替换内容相同时,一般索引不能雷同。

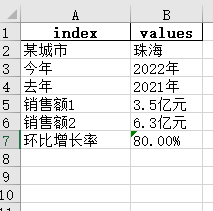
2.字典
创建excel文件,含有用于替换内容的字典数据。
三、源码
1.加载模块
需要安装python3.9或以上版本,docx、pandas、numpy、tkinter均需提前装好。
import docx, pandas as pd, numpy as np, tkinter as tk, os
from tkinter.filedialog import askopenfilename
from docx.enum.text import WD_COLOR_INDEX
2.定义替换函数
特别注意docx的run切割原则上是按照文本格式来切割的,但实际存在过度切割的问题,即相同格式相邻的文本内容被切成两个run。两个while循环,是为了解决这一问题。
# 定义文本替换函数
def doc_dic_replace(doc, dic):
# 段落文本替换
for p in doc.paragraphs:
# 原本run文本块的切割按样式切割,但实际存在过度切割的问题
i = 0
while i < len(p.runs):
j = 1
# 定位黄色高亮的run文本块
if p.runs[i].font.highlight_color == WD_COLOR_INDEX.YELLOW:
# 检查后面的run文本块是否为高亮
while j < len(p.runs):
# 不是高亮时,说明run切割完整
if p.runs[i+j].font.highlight_color != WD_COLOR_INDEX.YELLOW:
break
else: # 高亮时
# 约定‘#’作为两个相邻索引的分隔符
# 含有‘#’时
if p.runs[i+j].text.find('#') >= 0:
# 定位‘#’的位置
k = p.runs[i+j].text.find('#')
# ‘#’前的内容附加到runs[i]
p.runs[i].add_text(p.runs[i+j].text[:k])
# ‘#’后的内容替换原runs[i+j]
p.runs[i+j].text = p.runs[i+j].text[k+1:]
break
else: # 不含有‘#’时
# 高亮的内容附加到runs[i]
p.runs[i].add_text(p.runs[i+j].text)
# 清除后面高亮的内容
p.runs[i+j].text = ''
j += 1
# 解决run文本块过度切割问题后
if p.runs[i].text in dic.keys():
# 实施替换
p.runs[i].text = dic[p.runs[i].text]
# 取消替换内容的高亮
p.runs[i].font.highlight_color = None
i +=j
# 表格文本替换
for t in doc.tables:
for row in t.rows:
for cell in row.cells:
# 各单元格重复“段落文本替换”步骤
doc_dic_replace(cell, dic)
3.加载文件和输出结果
if __name__ == '__main__':
# 选择数据表
root = tk.Tk()
fp = askopenfilename(title = '请选择数据表:', filetypes= (('excel文件', '*.xlsx'),) )
root.mainloop()
# 载入数据表
da1 = pd.read_excel(fp)
# 转换为字典
dic_1 = {a['index']:a['values'] for a in da1.to_dict(orient='index').values()}
# 设置数据表父路径为工作路径(即设置好输出结果的默认文件位置)
os.chdir(os.path.dirname(fp))
# 选择模板
root = tk.Tk()
fp = askopenfilename(title = '请选择模板:', filetypes= (('word文件', '*.docx'),) )
root.mainloop()
# 载入模板
dx1 = docx.Document(fp)
# 实施替换
doc_dic_replace(dx1, dic_1)
# 输出报告
dx1.save('word2.docx')
四、实例
模板:

输出:

总结
本文主要讲解了利用python的文本替换实现自动化报告,主要优势体现为:
1.结合循环语句可以批量生成报告;
2.内容与文本格式分离,即内容在excel中维护,文本格式在word中维护。















 909
909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









