







MapReduce—平均工资
MapReduce—平均工资
我这里是使用集群去处理这个日志数据,数据在我的github上,默认使用maven去管理所有的jar包
1. 需求分析
按照所给数据文件去统计每个部门的人数,最高工资,最低工资和平均工资
需求统计的日志数据如下:
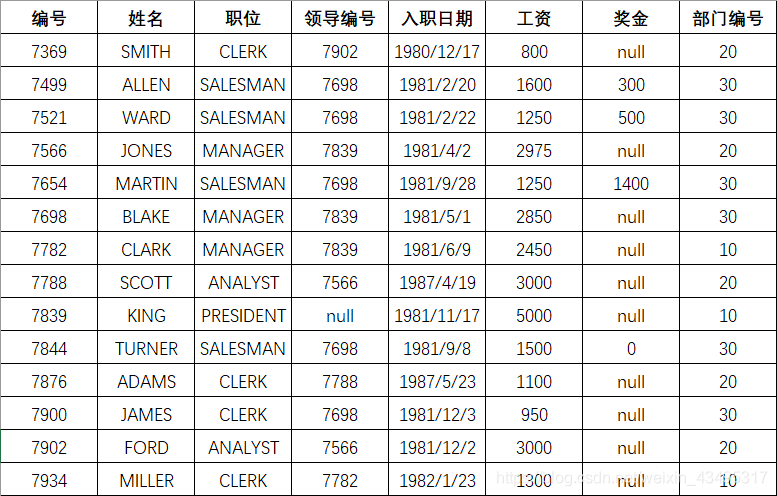
需要将每个部门的人数,工资进行统计。比如10号部门有3个人,最高工资是5000元,最低工资是1300元,平均工资是2916.666666666667元。则以如下形式进行显示:
10 3 5000 1300 2916.666666666667
2. 解答思路
1.因为要统计部门的人数以及工资,那么在最后的reduce阶段,进行汇总时,可以设置一个计数器,在进行汇总时,就可以计算出部门人数,所以,我们只需要日志数据中的两列,分别是部门编号和工资,将部门编号作为key,工资作为value
2.在reduce输出阶段,因为要输出人数,最高工资,最低工资和平均工资,一共四列,所以需要将计算出的结果拼接成一个Text进行输出
3.在处理过程中我使用Partitioner将数据分开通过不同的reduce去处理
4.如果需要本地运行,记得注释掉avgsal文件中的23/24/25行,并将47行和50行的文件路径修改为自己所使用的文件路径
5.因为在数据扭转的过程中,<K2, V2>和<K3, V3>的数据类型发生了变化,所以要在avgsal中设置map端所输出的数据类型,也就是要指定<K2, V2>的数据类型
mapper端代码
package com.yangqi.avgsal;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author xiaoer
* @date 2019/11/12 12:44
*/
public class MyMapper extends Mapper<LongWritable, Text, IntWritable, DoubleWritable> {
IntWritable num = new IntWritable();
DoubleWritable result = new DoubleWritable();
/**
* 针对每一行的数据,都会执行一次下面的map方法
*
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split(",");
String str1 = split[split.length - 1];
String str2 = split[split.length - 3];
num.set(Integer.parseInt(str1));
result.set(Double.parseDouble(str2));
context.write(num, result);
}
}
reduce端代码
package com.yangqi.avgsal;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author xiaoer
* @date 2019/11/12 12:47
*/
public class MyReducer extends Reducer<IntWritable, DoubleWritable, IntWritable, Text> {
Text result = new Text();
@Override
protected void reduce(IntWritable key, Iterable<DoubleWritable> values, Context context) throws IOException, InterruptedException {
// 记录部门的人数
int num = 0;
// 记录部门的工资和
double sum = 0;
// 记录最大工资
double max = Double.MIN_VALUE;
// 记录最小工资
double min = Double.MAX_VALUE;
for (DoubleWritable value : values) {
num++;
sum += value.get();
if (max < value.get()) {
max = value.get();
}
if (min > value.get()) {
min = value.get();
}
}
// 将结果进行拼接,拼接成Text进行输出
String str = "\t" + num + "" + "\t" + max + "" + "\t" + min + "\t" + (sum / num);
result.set(str);
// 以<K3, V3>形式进行写出
context.write(key, result);
}
}
partitioner端代码
package com.yangqi.avgsal;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* @author xiaoer
* @date 2019/11/13 11:54
*/
public class MyPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value, int numPartitions) {
int emp = Integer.parseInt(key.toString());
if (emp == 10 || emp == 30) {
return 0;
} else
return 1;
}
}
avgsal
package com.yangqi.avgsal;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author xiaoer
* @date 2019/11/12 12:50
*/
public class AvgSal {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 获取配置对象:读取四个默认配置文件
Configuration conf = new Configuration();
System.setProperty("HADOOP_USER_NAME", "hadoop");
conf.set("mapreduce.app-submission.cross-platform", "true");
conf.set("mapred.jar", "AvgSal/target/AvgSal-1.0-SNAPSHOT.jar");
FileSystem fs = FileSystem.get(conf);
// 创建Job实例对象
Job job = Job.getInstance(conf, "avgsal");
// 用于指定驱动类型
job.setJarByClass(AvgSal.class);
// 用于指定Map阶段的类型
job.setMapperClass(MyMapper.class);
// 用于指定Reduce阶段的类型
job.setReducerClass(MyReducer.class);
job.setNumReduceTasks(2);
// 设置Partition的类型
job.setPartitionerClass(MyPartitioner.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(DoubleWritable.class);
// 设置K3的输出类型
job.setOutputKeyClass(IntWritable.class);
// 设置V3的输出类型
job.setOutputValueClass(Text.class);
// 设置要统计的文件的路径
FileInputFormat.addInputPath(job, new Path("/emp"));
// FileInputFormat.addInputPath(job, new Path(args[0]));
// 设置文件的输出路径
Path path = new Path("/output");
// Path path = new Path(args[1]);
if (fs.exists(path)) {
fs.delete(path, true);
}
FileOutputFormat.setOutputPath(job, path);
// 等到作业执行,并退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}


















 4677
4677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











