







一、redis概述
REmote DIctionary Server(Redis)是一个基于key-value键值对的持久化数据库存储系统。redis和大名鼎鼎的Memcached缓存服务软件很像,但是redis支持的数据存储类型比memcached更丰富,包括strings(字符串),lists(列表),sets(集合)和sorted sets(有序集合)等。
这些数据类型支持push/pop,add/remove及取交集,并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached缓存服务一样,为了保证效率,数据都是缓存在内存中提供服务。和memcached不同的是,redis持久化缓存服务还会周期性的把更新的数据写入到磁盘以及把修改的操作记录追加到文件里记录下来,比memcached更有优势的是,redis还支持master-slave(主从)同步,这点很类似关系型数据库MySQL主从复制功能。
Redis是一个开源的使用C语言编写(3万多行代码),支持网络,可基于内存亦可持久化的日志型,Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。
Redis软件的出现,再一定程度上弥补了memcached这类key-value内存缓存服务的不足,在部分场合可以对关系数据库起到很好的补充作用。redis提供了Python,Ruby,Erlang,PHP客户端,
1.redis特点
key-value键值类型存储 支持数据可靠存储及落地 单进程单线程高性能服务器 crash safe & recovery slow
单机qps可以达到10W 适合小数据量高速读写访问
1.1Redis优点缺点
优点:
与memcached不同,Redis可以持久化存储数据 性能很高:Redis能支持超过10W每秒的读写频率。
丰富的数据类型:Redis支持二进制的Strings,Lists,Hashes,Sets及sorted Sets等数据类型操作
原子:Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行
丰富的特性:Redis还支持publish/subscribe(发布/订阅),通知,key过期等等特性。 redis支持异机主从复制。
缺点:
系统运行有毛刺 不同命令延迟差别极大 内存管理开销大(设置低于物理内存3/5) buffer io造成系统OOM(内存溢出)
1.2redis的数据类型
作为Key-value型存储系统数据库,Redis提供了键(Key)和值(value)映射关系。但是,除了常规的数值或字符串,Redis的键值还可以是以下形式之一,下面为最为常用的数据类型:
String 字符串
Hash 哈希表
List 列表
Set 集合
Sorted set 有序集合
(1)字符串(字符串)
它是redis的最基本的数据类型,一个键对应一个值,需要注意是一个键值最大存储512MB。

(2)hash(哈希)
redis hash是一个键值对的集合,是一个string类型的field和value的映射表,适合用于存储对象

(3)表(列表)
是redis的简单的字符串列表,它按插入顺序排序

(4)组(集合)
是字符串类型的无序集合,也不可重复

(5)zset(sorted set有序集合)
是string类型的有序集合,也不可重复
有序集合中的每个元素都需要指定一个分数,根据分数对元素进行升序排序,如果多个元素有相同的分数,则以字典序进行升序排序,sorted set因此非常适合实现排名

介绍一下 redis的数据类型每种数据类型的使用场景
(一)String
这个其实没啥好说的,最常规的set/get操作,value可以是String也可以是数字。一般做一些复杂的计数功能的缓存。
(二)hash
这里value存放的是结构化的对象,比较方便的就是操作其中的某个字段。博主在做单点登录的时候,就是用这种数据结构存储用户信息,以cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。
(三)list
使用List的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以利用lrange命令,做基于redis的分页功能,性能极佳,用户体验好。
(四)set
因为set堆放的是一堆不重复值的集合。所以可以做全局去重的功能。为什么不用JVM自带的Set进行去重?因为我们的系统一般都是集群部署,使用JVM自带的Set,比较麻烦,难道为了一个做一个全局去重,再起一个公共服务,太麻烦了。
另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。
(五)sorted set
sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。另外,参照另一篇《分布式之延时任务方案解析》,该文指出了sorted set可以用来做延时任务。最后一个应用就是可以做范围查找。
1.3Redis持久化
通常,Redis将数据存储于内存中,或被配置为使用虚拟内存。通过两种方式可以实现数据持久化:使用快照(snapshot)的方式,将内存中的数据不断写入磁盘,或使用类似MySQL的binlog日志(aof但并不用于主从同步)方式,记录每次更新的日志。前者性能较高,但是可能会引起一定程度的数据丢失;后者相反。
快照(快照)
1,将存储在内存的数据以快照的方式写入二进制文件中,如默认dump.rdb中 2,保存900 1
#900秒内如果超过1个Key被修改,则启动快照保存 3,保存300 10
#300秒内如果超过10个Key被修改,则启动快照保存 4,保存60 10000
#60秒内如果超过10000个重点被修改,则启动快照保存
仅附加文件(AOF)
1,使用AOF持久时,服务会将每个收到的写命令通过写函数追加到文件中(appendonly.aof) 2,AOF持久化存储方式参数说明
appendonly yes#开启AOF持久化存储方式 appendfsync always #收到写命令后就立即写入磁盘,效率最差,效果最好 appendfsync everysec #每秒写入磁盘一次,效率与效果居中 appendfsync no #完全依赖操作系统,效率最佳,效果没法保证
1.4redis的最佳应用场景
Redis最佳试用场景是全部数据in-memory
Redis更多场景是作为Memcached的替代品来使用。
数据比较重要,对数据一致性有一定要求的业务。
当需要除key/value之外的更多数据类型支持时,使用Redis更合适。
需要提供主从同步以及负载均衡分布式应用场景(redis主从同步)
1.5redis的应用场景有哪些
1,会话缓存(最常用)
2,消息队列,
比如支付3,活动排行榜或计数
4,发布,订阅消息(消息通知)
5,商品列表,评论列表等
1.6redis的服务相关的命令

slect#选择数据库(数据库编号0-15)
退出#退出连接
信息#获得服务的信息与统计
monitor#实时监控
config get#获得服务配置
flushdb#删除当前选择的数据库中的key
flushall#删除所有数据库中的键
二、redis的发布与订阅
redis的发布与订阅(发布/订阅)是它的一种消息通信模式,一方发送信息,一方接收信息。
下图是三个客户端同时订阅同一个频道
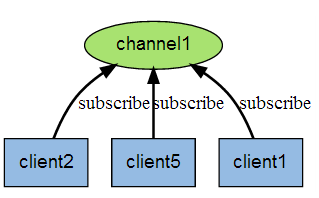
下图是有新信息发送给频道1时,就会将消息发送给订阅它的三个客户端

redis的过期策略以及内存淘汰机制
分析:这个问题其实相当重要,到底redis有没用到家,这个问题就可以看出来。比如你redis只能存5G数据,可是你写了10G,那会删5G的数据。怎么删的,这个问题思考过么?还有,你的数据已经设置了过期时间,但是时间到了,内存占用率还是比较高,有思考过原因么?
回答:
redis采用的是定期删除+惰性删除策略。
为什么不用定时删除策略?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略.
定期删除+惰性删除是如何工作的呢?
定期删除,redis默认每个100ms检查,是否有过期的key,有过期key则删除。需要说明的是,redis不是每个100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。
采用定期删除+惰性删除就没其他问题了么?
不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机制。
在redis.conf中有一行配置
maxmemory-policy allkeys-lru
该配置就是配内存淘汰策略的(什么,你没配过?好好反省一下自己)
1)noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。应该没人用吧。
2)allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。推荐使用。
3)allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。应该也没人用吧,你不删最少使用Key,去随机删。
4)volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。这种情况一般是把redis既当缓存,又做持久化存储的时候才用。不推荐
5)volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。依然不推荐
6)volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。不推荐
ps:如果没有设置 expire 的key, 不满足先决条件(prerequisites); 那么 volatile-lru, volatile-random 和 volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致。
redis和数据库双写一致性问题
分析:一致性问题是分布式常见问题,还可以再分为最终一致性和强一致性。数据库和缓存双写,就必然会存在不一致的问题。答这个问题,先明白一个前提。就是如果对数据有强一致性要求,不能放缓存。我们所做的一切,只能保证最终一致性。另外,我们所做的方案其实从根本上来说,只能说降低不一致发生的概率,无法完全避免。因此,有强一致性要求的数据,不能放缓存。
回答:首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
如何应对缓存穿透和缓存雪崩问题
分析:这两个问题,说句实在话,一般中小型传统软件企业,很难碰到这个问题。如果有大并发的项目,流量有几百万左右。这两个问题一定要深刻考虑。
回答:如下所示
缓存穿透:即黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库上,从而数据库连接异常。
解决方案:
(一)利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试
(二)采用异步更新策略,无论key是否取到值,都直接返回。value值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。
(三)提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的key。迅速判断出,请求所携带的Key是否合法有效。如果不合法,则直接返回。
缓存雪崩,即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常。
解决方案:
(一)给缓存的失效时间,加上一个随机值,避免集体失效。
(二)使用互斥锁,但是该方案吞吐量明显下降了。
(三)双缓存。我们有两个缓存,缓存A和缓存B。缓存A的失效时间为20分钟,缓存B不设失效时间。自己做缓存预热操作。然后细分以下几个小点
I 从缓存A读数据库,有则直接返回
II A没有数据,直接从B读数据,直接返回,并且异步启动一个更新线程。
III 更新线程同时更新缓存A和缓存B。
如何解决redis的并发竞争key问题
分析:这个问题大致就是,同时有多个子系统去set一个key。这个时候要注意什么呢?大家思考过么。需要说明一下,博主提前百度了一下,发现答案基本都是推荐用redis事务机制。博主不推荐使用redis的事务机制。因为我们的生产环境,基本都是redis集群环境,做了数据分片操作。你一个事务中有涉及到多个key操作的时候,这多个key不一定都存储在同一个redis-server上。因此,redis的事务机制,十分鸡肋。
回答:如下所示
(1)如果对这个key操作,不要求顺序
这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做set操作即可,比较简单。
(2)如果对这个key操作,要求顺序
假设有一个key1,系统A需要将key1设置为valueA,系统B需要将key1设置为valueB,系统C需要将key1设置为valueC.
期望按照key1的value值按照 valueA–>valueB–>valueC的顺序变化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。假设时间戳如下
系统A key 1 {valueA 3:00}
系统B key 1 {valueB 3:05}
系统C key 1 {valueC 3:10}
那么,假设这会系统B先抢到锁,将key1设置为{valueB 3:05}。接下来系统A抢到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做set操作了。以此类推。
其他方法,比如利用队列,将set方法变成串行访问也可以。总之,灵活变通。
redis中支持事务吗?【了解即可】
支持,使用multi开启事务,使用exec提交事务。
redis如何实现高可用【主从复制、哨兵机制】
实现redis高可用机制的一些方法:
保证redis高可用机制需要redis主从复制、redis持久化机制、哨兵机制、keepalived等的支持。
主从复制的作用:数据备份、读写分离、分布式集群、实现高可用、宕机容错机制等。
redis主从复制原理
首先主从复制需要分为两个角色:master(主) 和 slave(从) ,注意:redis里面只支持一个主,不像Mysql、Nginx主从复制可以多主多从。
1、redis的复制功能是支持多个数据库之间的数据同步。一类是主数据库(master)一类是从数据库(slave),主数据库可以进行读写操作,当发生写操作的时候自动将数据同步到从数据库,而从数据库一般是只读的,并接收主数据库同步过来的数据,一个主数据库可以有多个从数据库,而一个从数据库只能有一个主数据库。
2、通过redis的复制功能可以很好的实现数据库的读写分离,提高服务器的负载能力。主数据库主要进行写操作,而从数据库负责读操作。
主从复制全量同步的过程:见下图

Redis主从复制可以根据是否是全量分为全量同步和增量同步
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。
全量同步过程:
1:当一个从数据库启动时,会向主数据库发送sync命令,
2:主数据库接收到sync命令后会开始在后台保存快照(执行rdb操作),并用缓存区记录后续的所有写操作
3:当主服务器快照保存完成后,redis会将快照文件发送给从数据库。
4:从数据库收到快照文件后,会丢弃所有旧数据,载入收到的快照。
5: 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令。
6: 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令。
增量同步的过程:
Redis增量复制是指slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
Redis主从复制全量与增量同步的选择:
主从服务器刚刚连接的时候,会先进行全量同步;全同步结束后,再进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
redis主从复制如何配置呢?
修改从服务器redis/conf中的redis.conf文件
修改IP地址和端口号为主服务器的IP和端口
slaveof 10.211.55.9 6379
masterauth 123456--- 如果主redis服务器配置了密码,则需要配置
只需要配置从服务器的redis.conf即可,主服务器无需配置。验证是否成功可以通过1、先登录主服务器redis-cli客户端,输入info。若role显示master、slave0能正常显示从服务器的ip,则表示主从服务配置成功,主从复制配置成功了,也同时实现了读写分离,不信?你看看试试看你的从服务器还能不能写入操作了?答案是:不能。从服务器只有读操作!
Redis哨兵机制
哨兵机制需要主从复制的支持。
Redis的哨兵(sentinel) 系统用于管理多个 Redis 服务器,该系统执行以下三个任务:
· 监控(Monitoring): 哨兵(sentinel) 会不断地检查你的Master和Slave是否运作正常。
· 提醒(Notification):当被监控的某个Redis出现问题时, 哨兵(sentinel) 可以通过 API 向管理员或者其他应用程序发送通知。
· 自动故障迁移(Automatic failover):当一个Master不能正常工作时,哨兵(sentinel) 会开始一次自动故障迁移操作,它会将失效Master的其中一个Slave升级为新的Master, 并让失效Master的其他Slave改为复制新的Master; 当客户端试图连接失效的Master时,集群也会向客户端返回新Master的地址,使得集群可以使用Master代替失效Master。
哨兵(sentinel) 是一个分布式系统,你可以在一个架构中运行多个哨兵(sentinel) 进程,这些进程使用流言协议(gossipprotocols)来接收关于Master是否下线的信息,并使用投票协议(agreement protocols)来决定是否执行自动故障迁移,以及选择哪个Slave作为新的Master.
每个哨兵(sentinel) 会向其它哨兵(sentinel)、master、slave定时发送消息,以确认对方是否”活”着,如果发现对方在指定时间(可配置)内未回应,则暂时认为对方已挂(所谓的”主观认为宕机” Subjective Down,简称sdown).
若“哨兵群”中的多数sentinel,都报告某一master没响应,系统才认为该master"彻底死亡"(即:客观上的真正down机,Objective Down,简称odown),通过一定的vote算法,从剩下的slave节点中,选一台提升为master,然后自动修改相关配置.
虽然哨兵(sentinel) 释出为一个单独的可执行文件 redis-sentinel ,但实际上它只是一个运行在特殊模式下的 Redis 服务器,你可以在启动一个普通 Redis 服务器时通过给定 --sentinel 选项来启动哨兵(sentinel).
哨兵(sentinel) 的一些设计思路和zookeeper非常类似
单个哨兵(sentinel)

哨兵模式如何配置?
注意:哨兵机制是redis自带的功能,不需要接入第三方实现
实现步骤: 哨兵机制端口号默认为26379
配置之前注意防火墙是否关闭
1.修改sentinel.conf配置文件(该文件存在于redis安装包根目录下)
注意:初次配置,不需要打开#sentinel monitor mymaster注释,因为后几行有默认当台服务器为主服务器
原配置:sentinel monitor mymaster 127.0.0.1 6379 2 通过这句来修改为:
sentinel monitor mymaster 10.211.55.3 6379 1 #主服务器名称 IP 端口号 选举次数(redis集群服务器不多时可以配置成1)
2.修改下一行:sentinel auth-pass mymaster 123456 # 第一个参数mymaster为主节点名称,123456为主服务器密码。
- 修改心跳检测 5000毫秒【默认为30秒】
sentinel down-after-milliseconds mymaster 5000
4.sentinel parallel-syncs mymaster 2 — 指定了在执行故障转移时,最多可以有多少个从Redis实例在同步新的主实例,在从Redis实例较多的情况下这个数字越小,同步的时间越长,完成故障转移所需的时间就越长
- 启动哨兵模式【cd到redis安装根目录下启动,因为需要运行redis-server】
./redis-server sentinel.conf --sentinel &
启动后如果打印+ monitor master 主节点名 ip 和 +slave slave ip则表示启动成功
6.可以通过模拟——主服务器进入redis-cli,输入shutdown,观察哨兵所在服务器日志打印。原从服务器本不能写操作,后由于哨兵自动故障迁移把某一个slave服务器升级为master服务器,则该升级后的服务器又可以进行写操作。
光靠redis主从复制和哨兵机制不足以实现redis高可用。为什么呢?
因为若某一节点宕机后,不会实现自动重启。最稳健实现高可用的做法 :
redis主从复制+哨兵机制(监控、提醒、自动故障迁移)+keepalived(自动重启),若重启多次仍不成功,可以通过邮件短信等方式通知。
学习整理,来源自网络
原文链接:https://blog.csdn.net/itcats_cn/article/details/82428716
原文链接:https://blog.csdn.net/itcats_cn/article/details/82391719
原文链接:https://blog.csdn.net/wq962464/article/details/90578484















 119
119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









