







bert句子向量表示相似度效果不好
BERT根据下游任务fine-tuning后,使用CLS和全部序列的效果并不差。但如果没有fine-tuning,直接用BERT预训练的向量,CLS和全部序列的效果都很差
之所以效果这么差,是因为CLS向量在预训练任务中,参与的loss是NSP,优化的目标是下一句话。
Bert中最常用的句向量方式是采用cls标记位或者平均所有位置的输出值,注意,在采用平均的方式的时候,我们需要先做一个mask的操作,计算均值时,除以mask的和。但bert的句子向量效果不理想。
为什么呢?
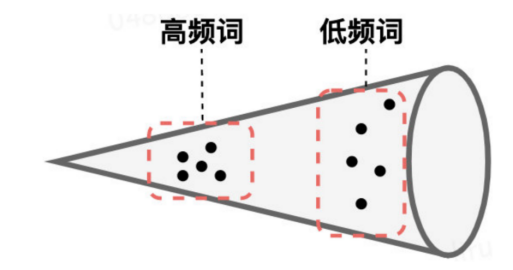
原因1:词频率影响词向量的空间分布。bert词向量表示与原点的L2距离的均值。高频的词更接近原点。
原因2:低频次分布偏向稀疏。度量词向量空间中与K近邻单词的 L2 距离的均值。我们可以看到高频词分布更集中,而低频词分布则偏向稀疏。然而稀疏性的分布会导致表示空间中存在很多“洞”,这些洞会破坏向量空间的“凸性”。考虑到BERT句子向量的产生保留了凸性,因而直接使用其句子embeddings会存在问题。
SBERT
BERT导出的句向量(不经过Fine-tune,对所有词向量求平均)质量较低,甚至比不上Glove的结果,因而难以反映出两个句子的语义相似
BERT对所有的句子都倾向于编码到一个较小的空间区域内,这使得大多数的句子
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3601
3601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











