









1.libmysql相关API介绍
MYSQL *mysql_init(MYSQL *mysql)
函数功能:分配或初始化MYSQL对象,若mysql是NULL,将分配,初始化,并返回新对象。否则,直接初始化,并返回。
MYSQL *mysql_real_connect(MYSQL *mysql, const char *host,
const char *user,
const char *passwd,
const char *db,
unsigned int port,
const char *unix_socket,
unsigned long client_flag)
函数功能:与MYSQL数据库建立连接。
参数说明:mysql是MYSQL 结构的地址。
host必须是主机名或IP地址
用户登陆数据库的密码
db:数据库名称
port:连接时,服务器TCP/IP的端口号
unix_socket:套接字
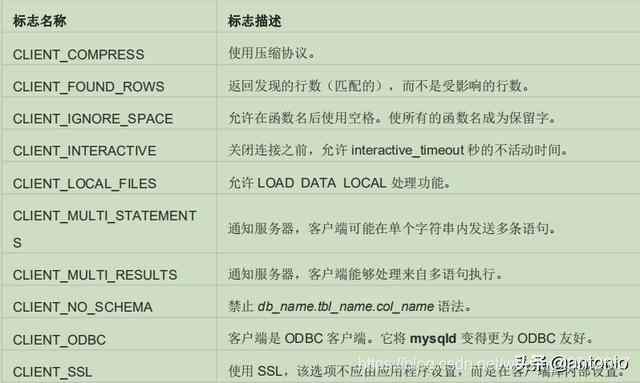
client_flag:特定功能标志位,以下是一些特殊功能说明
int mysql_query(MYSQL *mysql, const char *stmt_str)
功能:与指定的连接标识符关联的服务器中的当前活动数据库发送一条查询。
参数:
mysql: mysql_init 函数返回的指针。
stmt_str: 查询语句。
MYSQL_RES *mysql_use_result(MYSQL *mysql)
功能:成功检索数据的每个查询。优点:直接从服务器读取结果,而不会将其保存在临时表或本地缓冲区内,与 mysql_store_result()相比,速度更快,而且使用的内存也更少。
参数:
mysql: mysql_init 函数返回的指针。
MYSQL_RES *mysql_store_result(MYSQL *mysql)
功能:mysql_store_result()将查询的全部结果读取到客户端,分配 1 个 MYSQL_RES 结构,并将结果置于该结构中。
参数:
mysql: mysql_init 函数返回的指针。
MYSQL_ROW mysql_fetch_row(MYSQL_RES *result)
功能:
检索一个结果集合的下一行。
参数:
result: 返回一个结构为MYSQL_ROW的下一行结果, 如果没有要检索的行或发生错误,则返回 NULL。
void mysql_free_result(MYSQL_RES *result)
释放由 mysql_store_result(), mysql_use_result(), mysql_list_dbs()等为结果集分配的内存。
参数
result: 结果集
void mysql_close(MYSQL *mysql);
功能:
关闭以前打开的连接。mysql_close()还会释放 mysql 指向的连接处理程序。
参数:
mysql: mysql_init 函数返回的指针。
数据结构原型:
MYSQL :在执行任何数据库操作前,都要创建一个MYSQL结构。
MYSQL_RES :执行查询语句返回的结果,如SELECT, SHOW, DESCRIBE, EXPLAIN
MYSQL_ROW :调用 mysql_fetch_row()可从 MYSQL_RES 中返回一个MYSQL_ROW 结构。
MYSQL_FIELD:表示一个 field 信息的元数据。
MYSQL_FIELD_OFFSET: field 在 row 中的索引值,从 0 开始。
//MYSQL 句柄
typedef struct st_mysql {
NET net; //通讯参数,网络相关
gptr connector_fd; //加密套接字协议层
//主机名, 数据库用户名,密码,Unix 套接字,版本,主机信息
char *host,*user,*passwd,*unix_socket,*server_version,*host_info,*info,*db;
unsigned int port,client_flag,server_capabilities;
unsigned int protocol_version;
unsigned int field_count; //字段个数
unsigned int server_status; //数据库状态
unsigned long thread_id; //数据库服务器中的连接 ID
my_ulonglong affected_rows;
my_ulonglong insert_id; //下一条记录的 ID
my_ulonglong extra_info;
unsigned long packet_length;
enum mysql_status status;
MYSQL_FIELD *fields; //字段列表
MEM_ROOT field_alloc;
my_bool free_me; //是否关闭
my_bool reconnect; //是否自动连接
struct st_mysql_options options;
char scramble_buff[9];
struct charset_info_st *charset;
unsigned int server_language; //数据库语言
} MYSQL;
typedef struct st_mysql_res
{
my_ulonglong row_count; // 结果集的行数
unsigned int field_count, current_field;// 结果集的列数,当前列
MYSQL_FIELD *fields; // 结果集的列信息
MYSQL_DATA *data; // 结果集的数据
MYSQL_ROWS *data_cursor; // 结果集的光标
MEM_ROOT field_alloc; // 内存结构
MYSQL_ROW row; // 非缓冲的时候用到
MYSQL_ROW current_row; // mysql_store_result 时会用到,当前行
unsigned long *lengths; // 每列的长度
MYSQL *handle; // mysql_use_result 会用。
my_bool eof; // 是否为行为
} MYSQL_RES; //查询结果集
typedef char **MYSQL_ROW; // 以字符串数组的形式返回数据
typedef unsigned int MYSQL_FIELD_OFFSET; // 当前字段的偏移量量
typedef struct st_mysql_rows
{
struct st_mysql_rows *next; // 下一条记录
MYSQL_ROW data; // 当前行的数据
unsigned long length; // 数据的长度
} MYSQL_ROWS; //mysql 的数据的链表节点。可见 mysql 的结果集是链表结构
typedef struct st_mysql_data
{
my_ulonglong rows;
unsigned int fields;
MYSQL_ROWS *data;
MEM_ROOT alloc;
} MYSQL_DATA; // 数据集的结构
typedef struct st_mysql_field
{
char *name; //列名称
char *table; //如果列是字段,列表
char *def; //默认值(由 mysql_list_fields 设置)
enum enum_field_types type; //类型的字段。Se mysql_com。h 的类型
unsigned int length; //列的宽度
unsigned int max_length; //选择集的最大宽度
unsigned int flags; //div 标记集
unsigned int decimals; //字段中的小数位数
} MYSQL_FIELD; //列信息的结构
typedef struct st_used_mem //结构为 once_alloc
{
struct st_used_mem *next; //下一个块使用
unsigned int left; //记忆留在块
unsigned int size; //块的大小
} USED_MEM; //内存结构
typedef struct st_mem_root
{
USED_MEM *free;
USED_MEM *used;
USED_MEM *pre_alloc;
unsigned int min_malloc;
unsigned int block_size;
void (*error_handler)(void);
} MEM_ROOT; //内存结构
2.sql 基础操作
创建数据库
CREATE DATABASE 数据库名 DEFAULT CHARACTER SET utf8;
CREATE SCHEMA 数据库名 DEFAULT CHARACTER SET utf8;
创建表
DROP TABLE IF EXISTS learn;
CREATE TABLE learn(
id INT,
course VARCHAR(32),
chapters TINYINT,
activity VARCHAR(32),
PRIMARY KEY(id)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
修改数据
UPDATE learn SET chapters = 5 WHERE id = 1;
删除数据
DELETE FROM learn WHERE id = 3;
查询数据
SELECT * FROM learn;
修改字段名
ALTER TABLE learn
CHANGE COLUMN chapterschapter_count` TINYINT NULL DEFAULT 0
增加字段名
ALTER TABLE learn
ADD COLUMN price DECIMAL (8,2) NOT NULL DEFAULT 0 AFTER chapter_count;
删除字段
ALTER TABLE learn
DROP COLUMN price;
3.事务
(1)使用Innodb数据库引擎的数据库或表才支持事务
(2)事务处理可以用来维护数据库的完整性,保证SQL语句要么全部执行,要不全部不执行。
(3)事务用来管理delete,insert,update语句。
事务自动提交:
(1)数 autocommit=0,表示本次对数据操作时,自动开启,在用户执行commit命令时提交,从开始操作数据库开始到执行commit命令之间的一系列操作称为一个完整的事务周期。加入不执行commit命令,系统则默认事务回滚,当前情况下事务的状态是自动开启手动提交。
(2)若参数 autocommit=1(系统默认值),事务的开启与提交又分为两种状态:
手动开启手动提交:
用户执行start transaction命令时(事务初始化),一个事务开启,用户执行commit命令时,当前事务提交,从用户执行start transaction命令到用户执行commit 命令之间的一系列操作为一个完整的事务周期。若不执行 commit 命令,系统则默认事务回滚。
自动开启自动提交:
用户在当前情况下(参数 autocommit=1)未执行start transaction 命令而对数据库进行了操作,系统则默认用户对数据库的每一个操作为一个孤立的事务,即用户每次进行操作,都会及时提交或回滚,这种情况下用户的每一个操作都是一个完整的事务周期。
事务的使用
开启事务
start transaction 或者 begin transaction
提交事务
commit;
回滚事务
rollback;
事务的特性
要满足4个条件
原子性
一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在某个环节。如果发生错误,则回滚到事务开始前的状态,就当这个事务从来没有执行过。
一致性
在事务开始前和结束后,数据库的完整性没有被破坏。表示写入的数据符合所有的预设规则,可以自发的完成所有预定的工作。
隔离型
防止多个事务并发执行时,导致数据的不一致。事务隔离分为不同级别,包括读未提交,读提交,可重复读和串行化。
持久性
事务处理结束后,对数据的修改就是永久,即便系统故障不会丢失。
MySQL 事务隔离级别


例子
脏读:当前事务(A)中可以读到其他事务(B)未提交的数据(脏数据),这种现象是脏读
比如有个两个事务,分别是转账事务,取款事务,取款事务查询账户余额为2000,取款1000,余额被改为1000,但是没有提交。这时查询账户余额为1000,产生了脏数据。全款事务发生未知错误,事务回滚,则余额变为2000元。这个转账事务又去读,又产生了脏读数据,发现余额是3000, 正常逻辑应该是4000。这种现象就是脏读。
不可重复读:事务A两次读取同一个数据,两次读取的结果不一样,这种现象为不可重复读。脏读与不可重复读的区别,脏读是读取没有提交的数据,不可重复读读到的是其它事务已提交的数据。
幻读: 在事务A中按照某个条件,先后两次查询数据库,两次查询结果的条数不同。 不可重复读与幻读的区别,前者是数据变了,后者是数据的行数变了。 例如有事务A和事务B,A第一次查询数据总量为100条,然后事务A开始其它操作,这个时候,事务B新增100条数据,并提交事务,事务A第二次查询,数据总量为200条,则新增的100条数据为幻读。按照正常逻辑,事务A前后两次读取到的数据总量应该一致。
注意,不可重复读和幻读有什么区别呢?
(1)不可重复读是读取了其它事务更改的数据,针对update操作
(2)幻读是读取了其它事务新增的数据,针对insert与delete操作
怎样解决不可重复读呢?
使用行级锁,锁定该行,事务A多次读取操作完成之后,才释放锁,这个时候,才允许其它事务更改刚才的数据。
怎样解决幻读呢?
使用表级锁,锁定整张表,事务A多次读取数据总量之后才释放锁,这个时候才允许其它事务新增数据。
总的来说,幻读和不可重复读都是指一个事务范围内操作受其它事务的影响,只不过幻读是重点在插入和删除,不可重复读重点在修改。
行级锁
行级锁是粒度最小的锁,只针对当前操作进行加锁。行级锁分为共享锁和排他锁。
特点:开销大,会出现死锁,粒度小,发生锁冲突的概率低,并发度最高
表级锁
锁定粒度最大,对整张表加锁,实现简单,资源消耗少,不会出现死锁,发生锁冲突最高,并发度最低。表级锁定分为表共享读锁(共享锁)与表独占写锁(排他锁)。
页级锁
介于行级锁和表级锁中间的一种锁,每次锁定相邻的一组记录。
开销和加锁时间介于表锁和行锁之间;会出现死锁。粒度在表锁和行锁间,并发度一般。
4.MyISAM 存储引擎
MyISAM不支持事务和外键,所以访问速度快。适合对当前事务的完整性没有要求,以访问为主的应用。
MyISAM的索引文件和数据文件是分离。有3个表相关文件,frm是存放表结构数据,MYD是表数据,MYI 是存放索引,索引树(b+树),索引存在叶子节点上,存储实际数据MYD的地址。
MyISAM 基于 ISAM 存储引擎,并对其进行扩展。它是在 Web、数据仓储和其他应用环境
下最常使用的存储引擎之一。MyISAM 拥有较高的插入、查询速度,但不支持事物和外键。
主要特点:
(1)支持大文件(达到63位文件长度)的文件系统和操作系统上被支持。
(2)删除、更新、插入混合使用,动态尺寸的行产生更少碎片,主要是通过合并相邻被删除的块完成,若下个块被删除,就扩展到下一块自动完成。
(3)每个表最大索引数一般是64,可以通过编译改变。每个索引的最大列数是16。
(4) 最大的键长度是1000字节,可以通过编译改变,对于键长度超过 250 字节的情况,一个超过 1024 字节的键将被用上
(5) BLOB 和 TEXT 列可以被索引,支持 FULLTEXT (全文)类型的索引,而 InnoDB 不支持这种类
型的索引,InnoDB主要是效率太低了。
(6) NULL 被允许在索引的列中,这个值占每个键的 0~1 个字节。
(7) 所有数字键值以高字节优先被存储以允许一个更高的索引压缩。
(8) 由于每个表都有一个AUTO_INCREMENT的内部列,当INSERT和UPDATE操作的时候该列被更新
,同时AUTO_INCREMENT 列将被刷新。所以说,MyISAM 类型表的 AUTO_INCREMENT 列更新比比 InnoDB 类型的AUTO_INCREMENT更快。
(9) 可以把数据文件和索引文件放在不同目录
(10) 每个字符列可以有不同的字符集
(11) 有 VARCHAR 的表可以固定或动态记录长度
(12) VARCHAR 和 CHAR 列可以多达 64KB
存储格式:
(1)静态表(默认),字段都是固定长度,存储迅速,容易缓存,出现故障容易恢复,占用空间通常别动态表多。
(2)动态表,占用的空间少,但频繁更新删除记录容易产生碎片,需要定期执行optimize table或myisamchk -r命令来改善性能,而且出现故障的时候恢复比较困难。
(3)压缩表,用myisampack工具创建,占用非常小的磁盘空间,每个记录是被单独压缩,有非常小的访问开支。
MyISAM适合场景:
主要用于插入新记录和读出记录,选择MyISAM能实现处理高效率。
5.InnoDB 存储引擎
InnoDB在事务上具有优势,支持提交,回滚及崩溃恢复能力等事务特性,所以比MyISAM 存储引擎占用更多的空间,如果需要频繁的更新,删除,同时对事务的完整性要求较高,需要实现并发控制,建议选择。
InnoDB也是按照B+树组成的一个索引结构文件,主键索引节点包含了完整的数据记录,表相关的文件有2个,.frm文件是存放表结构数据,.ibd存放的数据和索引。
主要特点:
(1) InnoDB 给 MySQL 提供了具有提交、回滚和崩溃恢复能力的事物安全。在SQL查询中,可以将InnoDB类型的表和其它MySQL的表类型混合,甚至在同一个查询中也可以混合。
(2)InnoDB适合处理巨大数据,性能高,CPU效率是任何其它基于磁盘的关系型数据库引擎不能匹敌。
(3) InnoDB 存储引擎完全与 MySQL 服务器整合,InnoDB存储引擎在主内存中缓存数据和索引而维持它缓冲池。表和索引在一个逻辑表空间中,并可以包含数个文件。比如在 MyISAM 表中每个表被
存放在分离的文件中。InnoDB可以是任何尺寸,即使在文件尺寸被限制为2GB的操作系统上。
(4) InnoDB支持外键完整性约束,存储表中的数据时,每张表的存储都按主键顺序存放。如果没有指定主键,则会为每一行生成一个6字节的ROWID,并以此作为主键。
(5)一般应用与大型数据库。
应用场景:
适合支持事务处理,支持外键,支持崩溃修复能力和并发控制。如果需要对事务的完整性要求高,如银行的取款,转账,要求实现并发控制,比如火车票,那选择InnoDB有很大优势。如果需要频繁更新,删除操作,也可以选择,因为支持事务的提交和回滚。
5.InnoDB 和 MyISAM 的对比
不同点:
(1) 由于锁粒度不同,InnoDB 比 MyISAM支持更高并发。
(2) InnoDB时行级锁,加锁的粒度更细,加锁的开销更大,更容易发生死锁。
(3)InnoDB支持备份容灾,支持在线热备,有很成熟的在线热备解决方案。
(4) MyISAM查询效率比InnoDB高,因为InnoDB是需要维护数据缓存,而且查询过程是先定位到行所在的数据块,然后在从数据块中定位到要查找的行。而MyISAM可以直接定位到数据所在的内存地址,可以直接找到数据。
(5) MyISAM 的表结构文件包括: .frm 表结构定义, .MYD(索引), .MYD(数据); 而 InnoDB 的表
数据文件为: .ibd 和.frm(表结构定义)
(6)MyISAM引擎使用B+树作为索引结构,叶子节点的data域存放的是数据记录的地址。索引检索的算法为首先按照B+tree搜索算法搜索索引,如果指定key存在,则取出其data域的值,这个值就是文件的地址。MyISAM索引文件和数据文件是分离,索引文件保存数据记录地址。InnoDB,表中的数据和索引是存放在一起,这时B+树的索引,保存了完整的数据记录,这个索引的key是数据表的主键。所以InnoDB表数据文件本身就是主索引。
相同点:
InnoDB 和 MyISAM 实现都是使用 B+树。
6.MySQL优化
(1)SQL优化,这个层面的优化力度最大。
(2)数据库表结构优化
(3) 系统配置优化
(4)硬件优化
SQL优化:
(1) 对查询进行优化,应尽量避免全表扫描。首先应考虑在 where 及 order by 涉及的列上建立索引。应尽量避免在 where 子句中使用!=或<>操作符。应尽量避免在 where 子句中使用!=或<>操作符。应尽量避免在 where 子句中使用 or 来连接条件。如果在 where 子句中使用参数,也会导致全表扫描。
(2) 索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过 6 个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
(3) 应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
(4) 尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
(5) 尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
(6) 避免频繁创建和删除临时表,以减少系统表资源的消耗。
(7) 在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 createtable,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后 insert。
(8) 尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过 1 万行,那么就应
该考虑改写。
(9) 越小的数据类型通常更好,越小的数据类型通常在磁盘、内存和 CPU 缓存中都需要更少的空间,处理起来更快。
(10) 简单的数据类型更好整型数据比起字符,处理开销更小,因为字符串的比较更复杂。在 MySQL 中,应该用内置的日期和时间数据类型,而不是用字符串来存储时间;以及用整型数据类型存储 IP 地址。
(11) 主键优化,主键上有相应的索引,用于快速查询。主键要求不能为 null。InnoDB引擎物理上以一种有助于快速查询的方式存储。如果表比较大,且很重要,但是没有特别适合做主键的列,则,应该创建一个额外的列,以auto-increment 方式增长,作为主键。可以作为联合查询的外键。
数据库表结构优化:
(1) 使用最小数据类型
(2) 使用简单数据类型
(3) 尽量少用 text 类型,非用不可时最好考虑分表
(4)表的垂直拆分
垂直拆分就是把原来 很多列的表拆分成多个表,这就解决了表的宽度问题。通常垂直拆分
可以按以下原则进行:
1、把不常用的字段单独存放到一个表中。
2、把大字段独立存放到一个表中。
3、把经常一起使用的字段放到一起。
(5) 水平拆分
表的水平拆分是为了解决单表的数据量过大问题,水平拆分的表每个表的结构都是完全一致
的
常用的水平拆分方法:
1、对 customer_id 进行 hash 运算,如果要拆分成 5 个表则使用 mod(custoneer_id,5)取出
0-4 个值
2、针对不同的 hashID 把数据存到不同的表中。
操作系统级别优化:
- I/O 调度策略
NOOP、CFQ、Deadline、Anticipatory
临时生效:echo “dadline” >/sys/block/sda/queue/scheduler
永久生效:/etc/grub.conf 中 kernel 后加 elevator=deadline(需要重启)
- SWAP 使用策略
echo"vm.swappiness=10">>/etc/sysctl.conf
- 文件系统
ext3、ext4 还是使用 XFS
准确来说 XFS 要优于 ext 系列
- 避免 NUMA 问题
numactl --interleave=all 即是允许所有的处理器可以交叉访问所有的内存
- /tmp 分区
tmpfs /dev/shm tmpfs defaults 00
设置 tmpdir=/tmp 之后,某些习惯性把文件写到 tmp 下的人要改一改习惯了,因为这些文件
占用的是内存不是磁盘,而且如果不重启的话是一直占用
- CPU
关闭服务器的节能模式
查看 kondemand 进程运行情况:
ps -ef |grepkondemand
7.总结
本篇主要详解了InnoDB和MYISAM,以及SQL优化。就分享到这里。欢迎转发,点赞,评论。
欢迎关注微信公众号

欢迎关注头条号















 2477
2477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









