







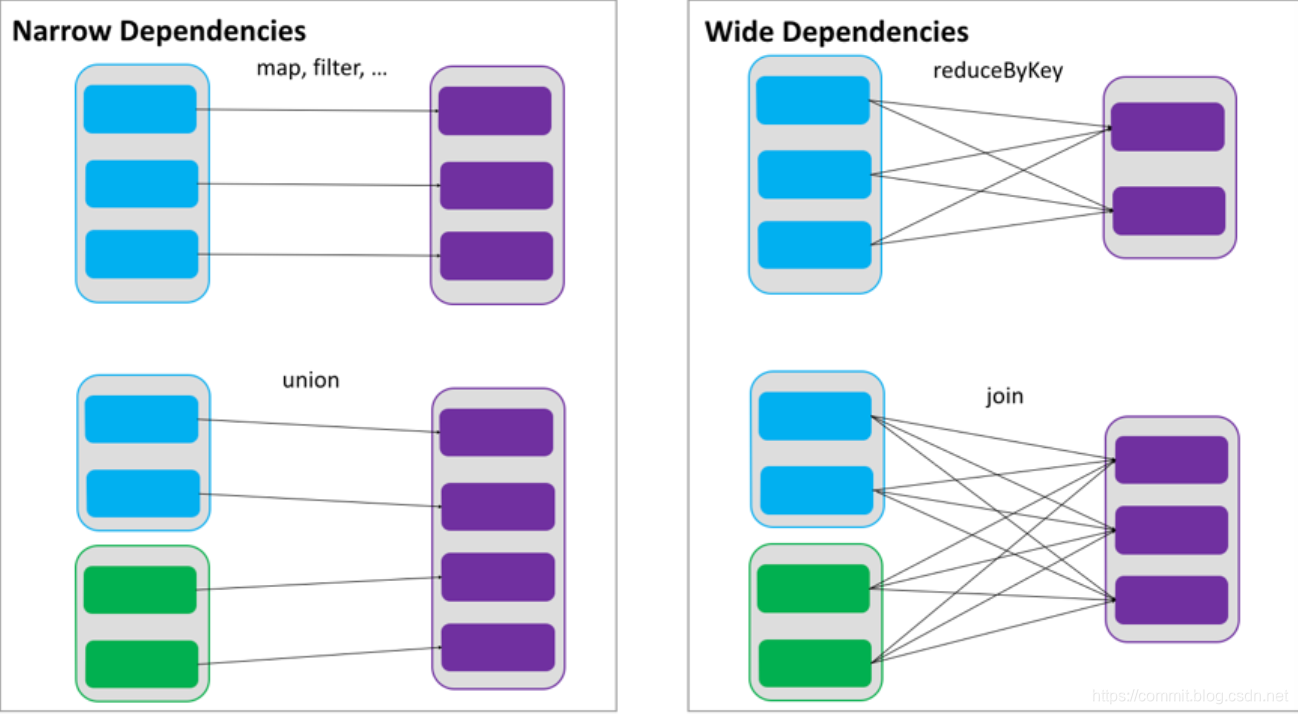
RDDs 通过操作算子进行转换,转换得到的新 RDD 包含了从其他 RDDs 衍生所必需的信息,RDDs 之间维护着这种血缘关系,也称之为依赖。依赖包括两种,一种是窄依赖,RDDs 之间分区是一一对应的,另一种是宽依赖,下游 RDD 的每个分区与上游RDD(也称之为父 RDD)的每个分区都有关,是多对多的关系。
Lineage
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列
Lineage(血统)记录下来,以便恢复丢失的分区。 RDD 的 Lineage 会记录 RDD 的元数据信息和转换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
窄依赖与宽依赖
窄依赖
一个父RDD的partition只能被子RDD的partition使用一次
类似于独生子女。
一父对一子,属于窄依赖;多父对一子,也属于窄依赖;
多父对一子,属于宽依赖;多父对多子,也属于宽依赖。
所以join操作不一定是宽依赖,亦可以是窄依赖
宽依赖
一个父RDD的partition被子RDD的partition使用不止一次
类似于超生
宽依赖与窄依赖在应用上的区别
- 数据丢失时:窄依赖:在数据丢失时,只需要修复与丢失数据的分区有血缘的父RDD的分区,这种情况,问题不大;宽依赖:一个分区丢了,之前的所有分区都需要重新计算;
- 落盘与否:窄依赖会直接以pipeline走到一个stage的底,一个pipeiline的数据是不会落盘的;而宽依赖属于shuffle算子,是会落到磁盘的;
DAG
DAG(Directed Acyclic Graph)叫做有向无环图,原始的 RDD 通过一系列的转换就就形成了 DAG,根据 RDD 之间的依赖关系的不同将 DAG 划分成不同的 Stage,对于窄依赖, partition 的转换处理在 Stage 中完成计算。对于宽依赖,由于有 Shuffle 的存在,只能在 parent RDD 处理完成后,才能开始接下来的计算,因此宽依赖是划分 Stage 的依据。
任务划分
RDD 任务切分中间分为: Application、 Job、 Stage 和 Task
- Application:初始化一个 SparkContext 即生成一个 Application
- Job:一个 Action 算子就会生成一个 Job
- Stage: 根据 RDD 之间的依赖关系的不同将 Job 划分成不同的 Stage, 遇到一个宽依赖则划分一个 Stage。
- Task: Stage 是一个TaskSet,将 Stage 划分的结果发送到不同的 Executor 执行即为一个Task。














 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









