






Diffusion Model
1、什么叫做扩散
扩散,顾名思义就是在一个图像中逐渐引入噪声污染,直到生成完全随机的噪声,并且习得从高斯噪声中恢复数据的能力。
2、GAN和Diffusion的对比
**GAN:**通过生成器和判别器互相对抗生成,最终使得两者互相收敛。
**Diffusion:**用一种更简单的方法来诠释生成模型的生成和学习,更易于理解。
**GAN的缺点:**由于需要同时训练两个网络,这导致两个网络训练难度大且不宜收敛。
在学习过程中可能会学习到我们不想得到的信息,出现无法控制的现象。
3、Diffusion原理
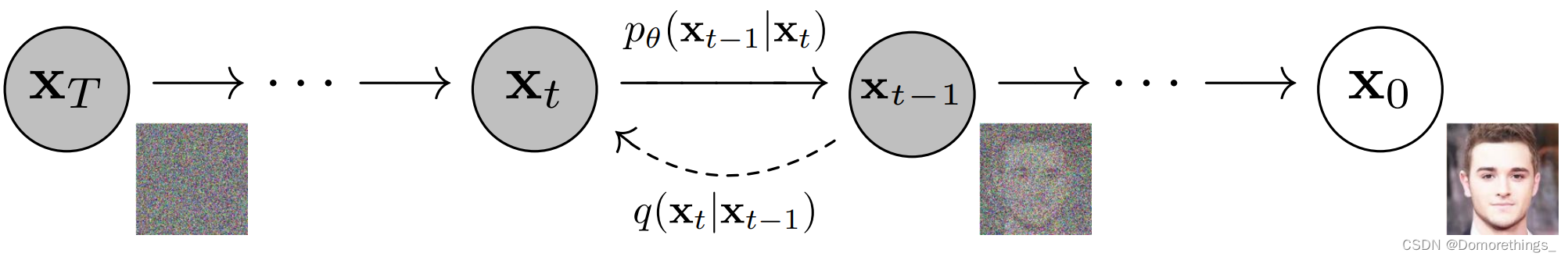
前向过程 ( T h e f o r w a r d t r a j e c t o r y ) (The\;forward \; trajectory) (Theforwardtrajectory):前向过程其实就是不断的往输入数据中添加噪声,直至最终得到一个纯噪声图片。整个过程中的加噪声操作可以被看作为构建标签的过程。
逆向过程 ( T h e r e v e r s e t r a j e c t o r y ) (The\; reverse \; trajectory) (Thereversetrajectory):逆向过程可以看作是去噪的过程,通过迭代一步步的倒退到初试的 X 0 X_0 X0 时刻,整个reverse的过程就被称作是一个修复去噪的过程。
4、公式推导
(1) 前向过程 ( T h e f o r w a r d t r a j e c t o r y ) (The\;forward \; trajectory) (Theforwardtrajectory):
α
t
=
1
−
β
t
α_t = 1-β_t
αt=1−βt
由于模型中的噪声添加是按照步骤分次进行的,每个步骤想要添加的噪声量也是不同的(越往后添加的噪声越多),因此加入 β 值,这里的β会随着t的增加逐渐增大(0.0001到0.002),α是β的互补项。
x
t
=
a
t
x
t
−
1
+
1
−
α
t
z
1
x_t = \sqrt{a_t}x_{t-1} + \sqrt{1-\alpha_t}{z_1}
xt=atxt−1+1−αtz1
对于当前时刻 t 来说,可以看作是对上一时刻 t-1 的数据添加噪声z1,随着时间推进,加入的噪声则越多,其中z为服从高斯分布
z
1
,
z
2
z_1,z_2
z1,z2。
但是,如果每次得到噪声图都需要将 X 从 X0 开始一步步的进行推导的话,整个计算过程将会变得非常漫长,因此便考虑将 Xt 由 X0 直接推导出来:
已知
x
t
=
α
t
x
t
−
1
+
1
−
α
t
z
1
x_t = \sqrt{\alpha_t}x_{t-1} + \sqrt{1-\alpha_t}{z_1}
xt=αtxt−1+1−αtz1,可以得到
x
t
−
1
=
α
t
−
1
x
t
−
2
+
1
−
α
t
−
1
z
2
x_{t-1}= \sqrt{\alpha_{t-1}}x_{t-2} + \sqrt{1-\alpha_{t-1}}{z_2}
xt−1=αt−1xt−2+1−αt−1z2
将公式(3)代入到公式(2)中可得下式:
x
t
=
α
t
(
α
t
−
1
x
t
−
2
+
1
−
α
t
−
1
z
2
)
+
1
−
α
t
z
1
x_t = \sqrt{\alpha_t}(\sqrt{\alpha_{t-1}}x_{t-2} + \sqrt{1-\alpha_{t-1}}{z_2}) + \sqrt{1-\alpha_t}z_1
xt=αt(αt−1xt−2+1−αt−1z2)+1−αtz1
= α t α t − 1 x t − 2 + α t ( 1 − α t − 1 ) z 2 + 1 − α t z 1 = \sqrt{\alpha_t\alpha_{t-1}}x_{t-2} + \sqrt{\alpha_t(1-\alpha_{t-1})}{z_2} + \sqrt{1-\alpha_t}z_1 =αtαt−1xt−2+αt(1−αt−1)z2+1−αtz1
由于 z 1 z_1 z1 和 z 2 z_2 z2 都是服从高斯分布 N ( 0 , I ) N(0,I) N(0,I),则 z 1 z_1 z1 服从 N ( 0 , ( 1 − α t ) I ) N(0,(1-\alpha_t)I) N(0,(1−αt)I) ; z 2 z_2 z2 服从 N ( 0 , α t ( 1 − α t − 1 ) I ) N(0,\alpha_t(1-\alpha_{t-1})I) N(0,αt(1−αt−1)I);
根据公式 N ( 0 , σ 1 2 I ) + N ( 0 , σ 2 2 I ) N(0,\sigma^2_1I)+N(0,\sigma^2_2I) N(0,σ12I)+N(0,σ22I) ~ N ( 0 , ( σ 1 2 + σ 2 2 ) I ) N(0,(\sigma^2_1+\sigma^2_2)I) N(0,(σ12+σ22)I)
z 1 z_1 z1 和 z 2 z_2 z2 相加可得: x t = α t α t − 1 x t − 2 + 1 − α t α t − 1 x_t=\sqrt{\alpha_t\alpha_{t-1}}x_{t-2} + \sqrt{1-\alpha_t\alpha_{t-1}} xt=αtαt−1xt−2+1−αtαt−1 z t z_t zt
综上可知, x t = α t α t − 1 . . . α t − n + 1 x n + 1 − α t α t − 1 . . . α t − n + 1 x_t=\sqrt{\alpha_t\alpha_{t-1}...\alpha_{t-n+1}}x_n+\sqrt{1-\alpha_t\alpha_{t-1}...\alpha_{t-n+1}} xt=αtαt−1...αt−n+1xn+1−αtαt−1...αt−n+1 z ‾ t − n \overline{z}_{t-n} zt−n
x
t
=
α
t
‾
x
0
+
1
−
α
t
‾
z
t
x_t=\sqrt{\overline{\alpha_t}}x_0 + \sqrt{1-\overline{\alpha_t}}z_t
xt=αtx0+1−αtzt {**}
其中:
α
t
‾
\overline{\alpha_t}
αt表示累乘
α
t
α
t
−
1
.
.
.
α
1
\alpha_t\alpha_{t-1}...\alpha_1
αtαt−1...α1
根据以上公式,任意时刻的分布都可以通过初始值 x 0 x_0 x0 经过一次计算得到,这也是Diffusion中的第一个核心公式。
(2) 逆向过程 ( T h e r e v e r s e t r a j e c t o r y ) (The\; reverse \; trajectory) (Thereversetrajectory):
贝叶斯公式:
P
(
A
∣
B
)
=
P
(
B
∣
A
)
∗
P
(
A
)
/
P
(
B
)
P (A|B)=P (B|A)*P (A)/P (B)
P(A∣B)=P(B∣A)∗P(A)/P(B)
在逆向过程中,我们的主要目的是由已知的
X
t
X_t
Xt ,推导到前一个状态
X
t
−
1
X_{t-1}
Xt−1,即求出概率
q
(
X
t
−
1
∣
X
t
)
q(X_{t-1}|X_t)
q(Xt−1∣Xt)
根据公式(7)可知:
q
(
X
t
−
1
∣
X
t
)
=
q
(
X
t
∣
X
t
−
1
)
q
(
X
t
−
1
)
q
(
X
t
)
q(X_{t-1}|X_t) = q(X_t|X_{t-1})\frac{q(X_{t-1})}{q(X_{t})}
q(Xt−1∣Xt)=q(Xt∣Xt−1)q(Xt)q(Xt−1)
公式 (8) 中
q
(
X
t
∣
X
t
−
1
)
q(X_t|X_{t-1})
q(Xt∣Xt−1) 由前向过程得到,而
q
(
X
t
−
1
)
q(X_{t-1})
q(Xt−1)和
q
(
X
t
)
q(X_{t})
q(Xt)无法直接得到,故在等式两边加入条件
X
0
X_0
X0 ,可得:
q
(
X
t
−
1
∣
X
t
,
X
0
)
=
q
(
X
t
∣
X
t
−
1
,
X
0
)
q
(
X
t
−
1
∣
X
0
)
q
(
X
t
∣
X
0
)
q(X_{t-1}|X_t,X_0) = q(X_t|X_{t-1},X_0)\frac{q(X_{t-1}|X_0)}{q(X_{t}|X_0)}
q(Xt−1∣Xt,X0)=q(Xt∣Xt−1,X0)q(Xt∣X0)q(Xt−1∣X0)
前向可知:
q ( X t ∣ X t − 1 , X 0 ) = α t x t − 1 + 1 − α t z q(X_t|X_{t-1},X_0) = \sqrt{\alpha_t}x_{t-1} + \sqrt{1-\alpha_t}{z} q(Xt∣Xt−1,X0)=αtxt−1+1−αtz ~ N ( α t x t − 1 , ( 1 − α t ) I ) N(\sqrt{\alpha_t}x_{t-1},(1-\alpha_t)I) N(αtxt−1,(1−αt)I)
$q(X_t|X_0)=\sqrt{\overline{\alpha}_t}x_0 + \sqrt{1-\overline{\alpha}_t} $ z z z ~ N ( α ‾ t x 0 , ( 1 − α ‾ t ) I ) N(\sqrt{\overline\alpha}_{t}x_0,(1-\overline{\alpha}_t)I) N(αtx0,(1−αt)I)
$q(X_{t-1}|X_0)=\sqrt{\overline{\alpha}{t-1}}x_0 + \sqrt{1-\overline{\alpha}{t-1}} $ z z z ~ N ( α ‾ t − 1 x 0 , ( 1 − α ‾ t − 1 ) I ) N(\sqrt{\overline{\alpha}_{t-1}}x_0,(1-\overline{\alpha}_{t-1})I) N(αt−1x0,(1−αt−1)I)
根据上述三项可知:
q
(
X
t
−
1
∣
X
t
,
X
0
)
∝
e
x
p
(
−
1
2
(
(
x
t
−
α
t
x
t
−
1
)
2
β
t
+
(
x
t
−
1
−
α
‾
t
−
1
x
0
)
2
1
−
α
‾
t
−
1
−
(
x
t
−
α
‾
t
x
0
)
2
1
−
α
‾
t
)
)
q(X_{t-1}|X_t,X_0) \varpropto exp (- \frac{1}{2}(\frac{(x_t-\sqrt\alpha_tx_{t-1})^2}{\beta_t}+\frac{(x_{t-1}-\sqrt{\overline{\alpha}_{t-1}}x_{0})^2}{1-\overline{\alpha}_{t-1}}-\frac{(x_{t}-\sqrt{\overline{\alpha}_{t}}x_{0})^2}{1-\overline{\alpha}_{t}}))
q(Xt−1∣Xt,X0)∝exp(−21(βt(xt−αtxt−1)2+1−αt−1(xt−1−αt−1x0)2−1−αt(xt−αtx0)2))
注:
N
(
μ
,
σ
2
)
∝
e
x
p
−
1
2
(
x
−
μ
)
2
σ
2
N(\mu,\sigma^2)\varpropto exp^{-\frac{1}{2}\frac{(x-\mu)^2}{\sigma^2}}
N(μ,σ2)∝exp−21σ2(x−μ)2
β t = 1 − α t \beta_t = 1- \alpha_t βt=1−αt
对公式(10)进行合并同类项并展开可得:
q
(
X
t
−
1
∣
X
t
,
X
0
)
=
e
x
p
(
−
1
2
(
(
α
t
β
t
+
1
1
−
α
‾
t
−
1
)
x
t
−
1
2
−
(
2
α
t
β
t
x
t
+
2
α
‾
t
−
1
1
−
α
‾
t
−
1
x
0
)
x
t
−
1
+
C
(
x
t
,
x
0
)
)
)
)
q(X_{t-1}|X_t,X_0) = exp(-\frac{1}{2}((\frac{\alpha_t}{\beta_t}+\frac{1}{1-\overline{\alpha}_{t-1}})x_{t-1}^2- (\frac{2\sqrt{\alpha_t}}{\beta_t}x_t+\frac{2\sqrt{\overline{\alpha}_{t-1}}}{1-\overline{\alpha}_{t-1}}x_0)x_{t-1}+ C(x_t,x_0)) ))
q(Xt−1∣Xt,X0)=exp(−21((βtαt+1−αt−11)xt−12−(βt2αtxt+1−αt−12αt−1x0)xt−1+C(xt,x0))))
已知:
e
x
p
(
−
(
x
−
μ
)
2
2
σ
2
)
=
e
x
p
(
−
1
2
(
1
σ
2
x
2
−
2
μ
σ
2
x
+
μ
2
σ
2
)
)
exp(-\frac{(x-\mu)^2}{2\sigma^2}) = exp(-\frac{1}{2}(\frac{1}{\sigma^2}x^2-\frac{2\mu}{\sigma^2}x+\frac{\mu^2}{\sigma^2}))
exp(−2σ2(x−μ)2)=exp(−21(σ21x2−σ22μx+σ2μ2))
公式(11)与公式(12)整理归纳可知:
μ
‾
t
(
x
t
,
x
0
)
=
α
t
(
1
−
α
‾
t
−
1
)
1
−
α
‾
t
x
t
+
α
‾
t
−
1
β
t
1
−
α
‾
t
x
0
\overline{\mu}_t(x_t,x_0)= \frac{\sqrt{\alpha_t(1-\overline{\alpha}_{t-1})}}{1-\overline{\alpha}_t}x_t + \frac{\sqrt{\overline{\alpha}_{t-1}}\beta_t}{1-\overline{\alpha}_t}x_0
μt(xt,x0)=1−αtαt(1−αt−1)xt+1−αtαt−1βtx0
根据公式(6)变换可知:
x
0
=
1
α
t
(
x
t
−
1
−
α
‾
t
z
t
)
x_0=\frac{1}{\sqrt{\over{\alpha}}_t}(x_t-\sqrt{1-\overline{\alpha}_t}z_t)
x0=αt1(xt−1−αtzt)
最终可得:
μ
t
~
=
1
a
t
(
x
t
−
β
t
1
−
a
‾
t
z
t
)
\tilde{\mu_t}=\frac{1}{\sqrt{a_t}}(x_t-\frac{\beta_t}{\sqrt{1-\overline{a}_t}}z_t)
μt~=at1(xt−1−atβtzt)
其中,
z
t
z_t
zt是我们需要预测的每个时刻的噪声。
5、最终流程图

(1)训练过程(前向过程)
2: x 0 x_0 x0为训练集中的对比图像;
3: t t t 为前向过程的扩散轮数,类似于transformer中的位置编码,对于每一个数据,会随机分配不固定的轮数 t t t,其目的是防止学习到规律;
4: ϵ \epsilon ϵ 是每个时刻采样得到的噪声,是给定的真实值,对应前文的 z z z,噪声严格遵循标准正态分布;
5: ▽ θ \triangledown_\theta ▽θ 是我们要更新的参数,$\epsilon_\theta $ 是利用模型训练得到的参数, α t ‾ x 0 + 1 − α t ‾ ϵ \sqrt{\overline{\alpha_t}}x_0 + \sqrt{1-\overline{\alpha_t}}\epsilon αtx0+1−αtϵ 实则为当前输入的待处理图像。
(2)推理过程(后向过程)
1: X T X_T XT 为随机采样后得到的待处理图;
2:每一个处理图像都需要经过从T到0的处理步骤;
3:最后一步将不再添加噪音点;
4: x t − 1 x_{t-1} xt−1来源于公式(14) ,其中 ϵ \epsilon ϵ 来自于训练阶段训练到的模型。















 5615
5615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









