







脱离八爪鱼,最近两天用scrapy爬了一个商品网站,本来可以快很多的,其中有一天把时间花在一行代码上最后绕了一大圈改了个参数就解决了??希望大家少走点弯路。
很多都是对慕课网的一个总结,网址:https://www.imooc.com/video/17519
讲得非常好!
比较敏感所以用课程的代码例子了。
第一次写,难免不专业多多指教。
1.新建项目
第一步先安装,可以按照视频上安装,略。
例子中,我们要爬的是:https://movie.douban.com/top250
首先:
scrapy startproject douban
就创建好了一个文件夹叫douban
在cmd上进入到douban文件夹中cd douban,再进入子目录cd douban/
好的,现在我们需要与网站相关联的一个包,cmd输入
scrapy genspider douban_spider movie.douban.com
然后我们就可以用pycharm或者sublime把包导进去check一下
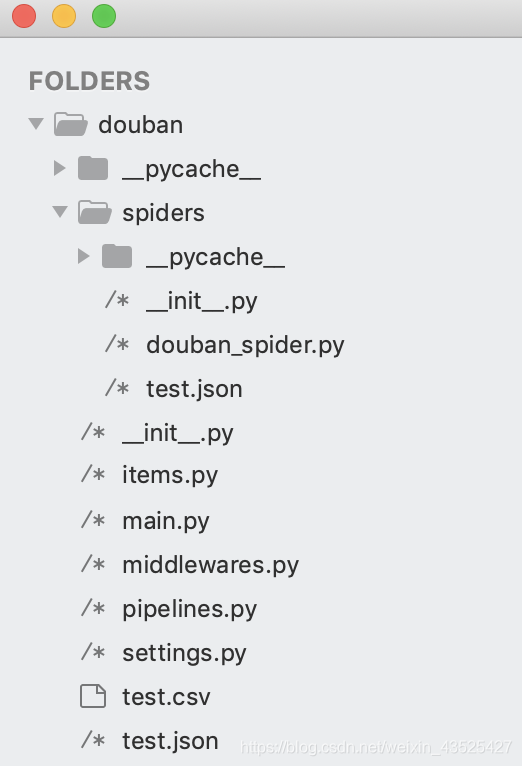
不要紧张,如果你的和我不一样,那么应该在douban目录下新建一个文件叫main.py
找到Settings.py文件 -> 找到被#掉的user agent -> (这个不是真正的user agent,我们需要打开https://movie.douban.com/top250,win直接F12,Mac就option+command+I ,打开检查栏)
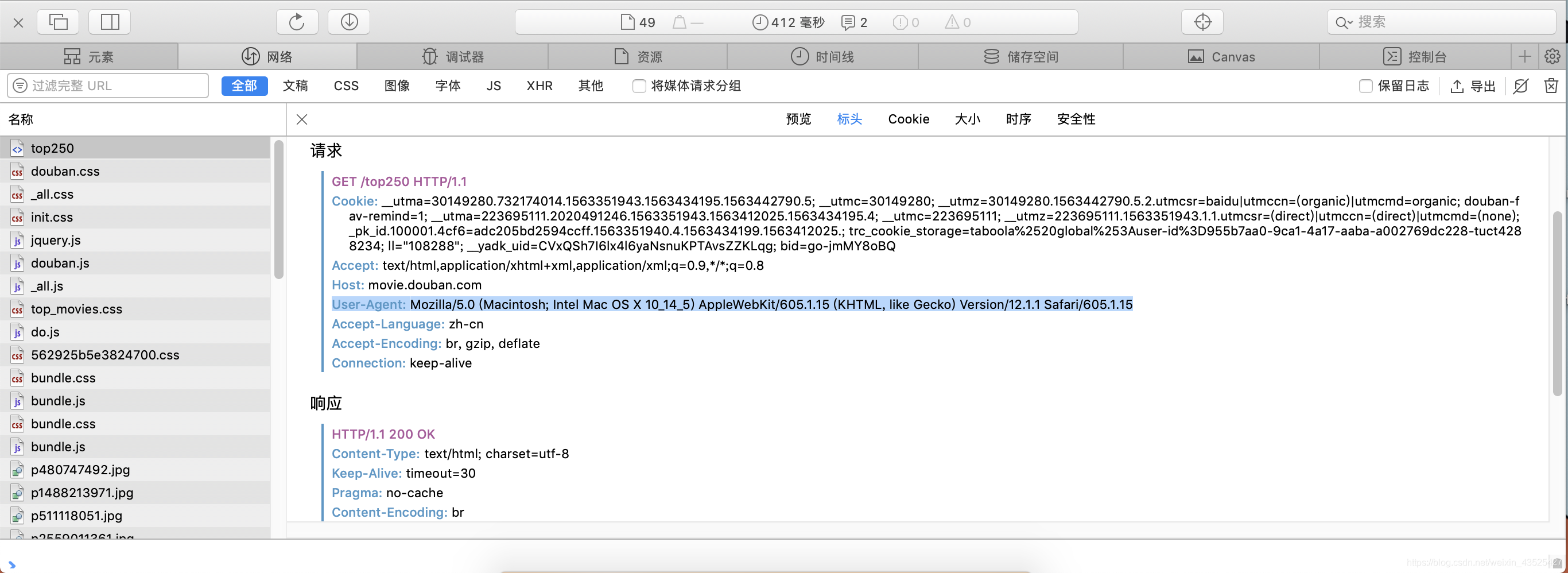
把黑字复制了拷在settings.py上的user agent后面就好,别忘了去掉注释
2.快捷运行
在main.py文件中,让他代替终端的功能,在环境中运行就好
from scrapy import cmdline
cmdline.execute('scrapy crawl douban_spider'.split())
3. 修改douban_spider.py
先贴上源码
# -*- coding: utf-8 -*-
import scrapy
from douban.items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
allowed_domains = ['movie.douban.com']
start_urls = ['http://movie.douban.com/top250']
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 726
726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











