







目录
栈和队列的原理
队列是先进先出,栈是先进后出
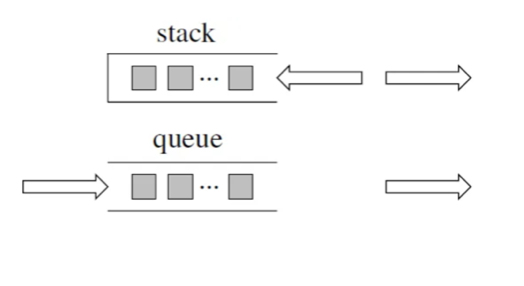
栈提供push 和 pop 等等接口,所有元素必须符合先进后出规则,所以栈不提供走访功能,也不提供迭代器(iterator)。 不像是set 或者map 提供迭代器iterator来遍历所有元素。栈是以底层容器完成其所有的工作,对外提供统一的接口,底层容器是可插拔的(也就是说我们可以控制使用哪种容器来实现栈的功能)。队列中先进先出的数据结构,同样不允许有遍历行为,不提供迭代器
LeetCode:232.用栈实现队列
使用栈来模式队列的行为,如果仅仅用一个栈,是一定不行的,所以需要两个栈:一个输入栈,一个输出栈,这里要注意输入栈和输出栈的关系。
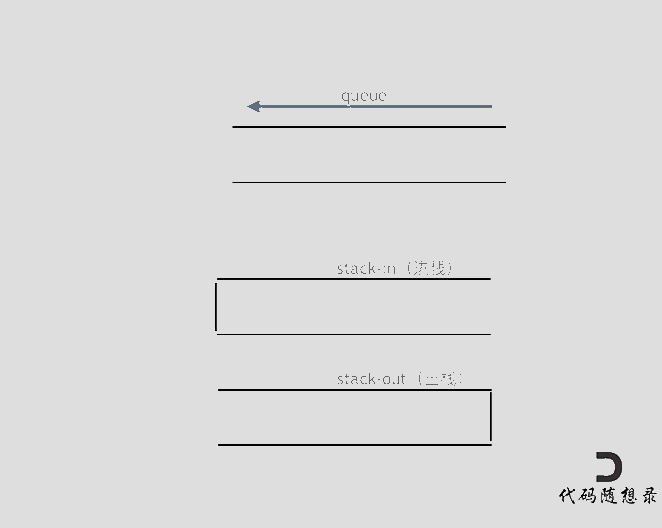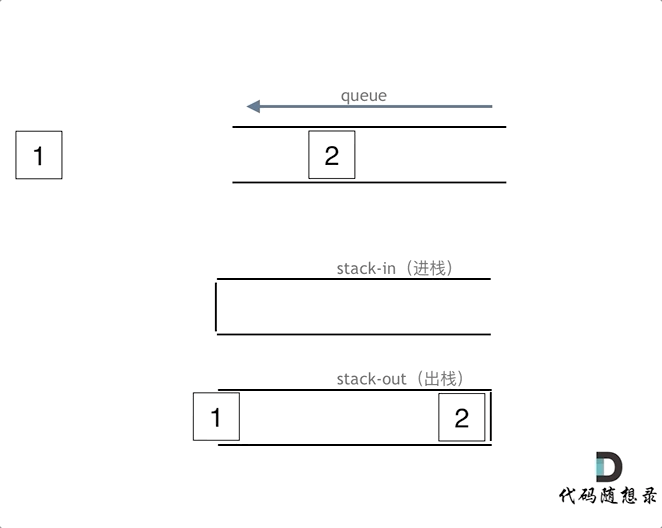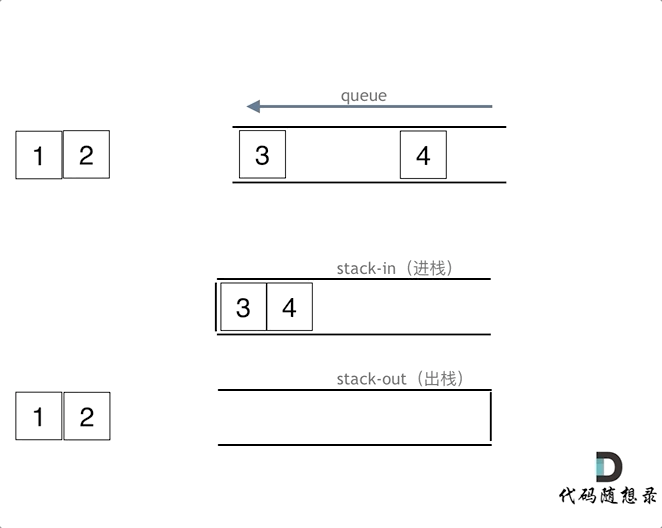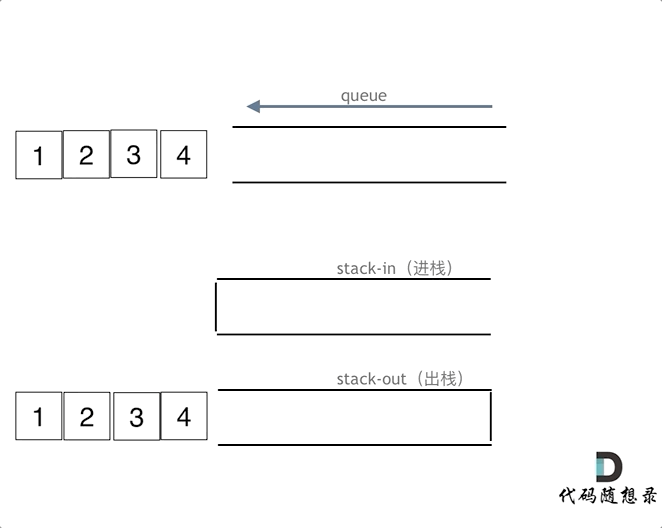
在push数据的时候,只要数据放进输入栈就好,但在pop的时候,操作就复杂一些,输出栈如果为空,就把进栈数据全部导入进来(注意是全部导入),再从出栈弹出数据,如果输出栈不为空,则直接从出栈弹出数据就可以了。
最后如何判断队列为空呢?如果进栈和出栈都为空的话,说明模拟的队列为空了。在代码实现的时候,会发现pop() 和 peek()两个函数功能类似,代码实现上也是类似的,可以思考一下如何把代码抽象一下。
var MyQueue = function() {
//定义两个栈,一个出栈,一个进栈,模拟队列
this.stackIn = [];
this.stackOut = [];
};
/**
* @param {number} x
* @return {void}
*/
//将元素 x 推到队列的末尾
MyQueue.prototype.push = function(x) {
this.stackIn.push(x);
};
/**
* @return {number}
*/
//从队列的开头移除并返回元素
MyQueue.prototype.pop = function() {
const size = this.stackOut.length;
if (size) { //出栈不为空则弹出栈顶元素
return this.stackOut.pop();
}
while (this.stackIn.length) { //入栈不为空时,将入栈的栈顶元素推进出栈
this.stackOut.push(this.stackIn.pop());
}
return this.stackOut.pop();
};
/**
* @return {number}
*/
//返回队列开头的元素
MyQueue.prototype.peek = function() {
const x = this.pop(); //调用队列开头移出元素的方法
this.stackOut.push(x); // 因为pop函数弹出了元素res,所以再添加回去
return x;
};
/**
* @return {boolean}
*/
//判断队列是否为空
MyQueue.prototype.empty = function() {
return !this.stackIn.length && !this.stackOut.length; //两个栈的元素都为空,则队列也为空
};LeetCode:225. 用队列实现栈
队列模拟栈,其实一个队列就够了,那么我们先说一说两个队列来实现栈的思路。队列是先进先出的规则,把一个队列中的数据导入另一个队列中,数据的顺序并没有变,并没有变成先进后出的顺序。所以用栈实现队列, 和用队列实现栈的思路还是不一样的,这取决于这两个数据结构的性质。但是依然还是要用两个队列来模拟栈,只不过没有输入和输出的关系,而是另一个队列完全用来备份的!
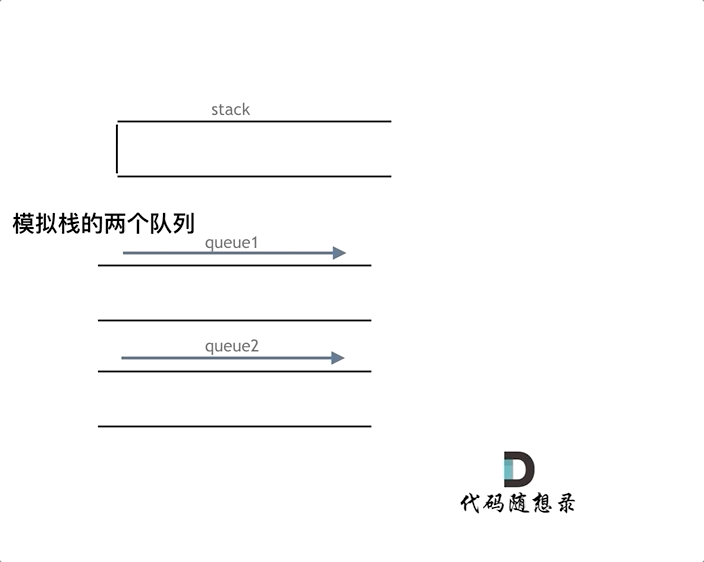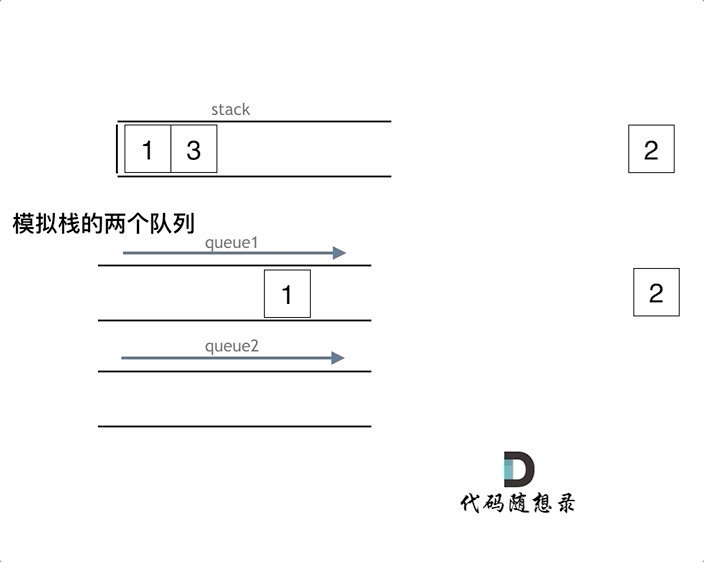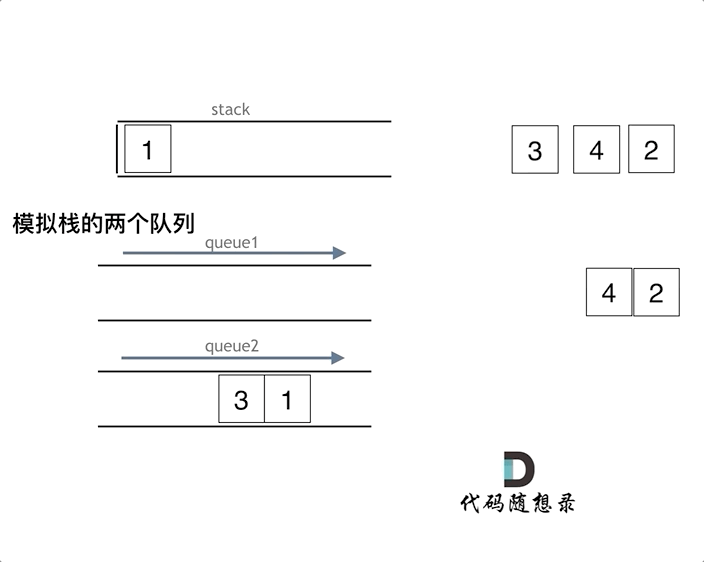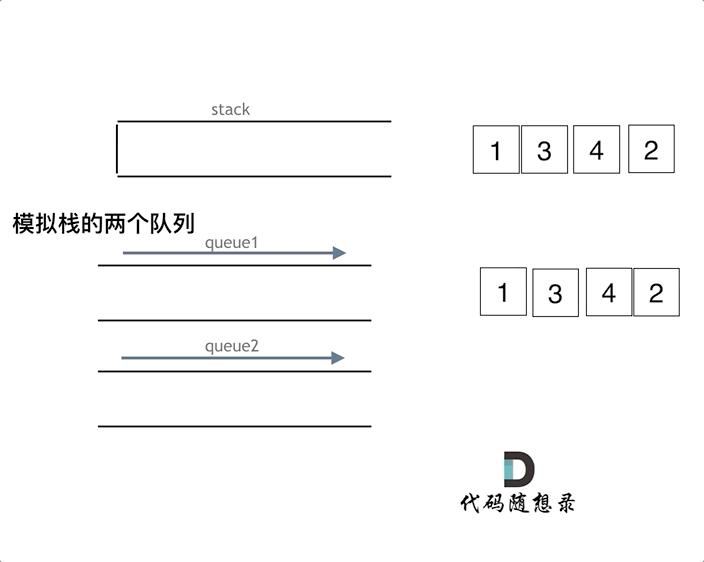
var MyStack = function() {
//一个队列用来操作,一个队列用来备份
this.queue1 = [];
this.queue2 = [];
};
/**
* @param {number} x
* @return {void}
*/
//将元素 x 压入栈顶
MyStack.prototype.push = function(x) {
this.queue1.push(x);
};
/**
* @return {number}
*/
//移除并返回栈顶元素。
MyStack.prototype.pop = function() {
// 减少两个队列交换的次数, 只有当queue1为空时,交换两个队列
if (!this.queue1.length) {
[this.queue1, this.queue2] = [this.queue2, this.queue1];
}
while (this.queue1.length > 1) {
this.queue2.push(this.queue1.shift());
}
return this.queue1.shift(); //弹出栈顶元素
};
/**
* @return {number}
*/
// 返回栈顶元素。
MyStack.prototype.top = function() {
const x = this.pop();
this.queue1.push(x);
return x;
};
/**
* @return {boolean}
*/
//判断栈是否空
MyStack.prototype.empty = function() {
return !this.queue1.length && !this.queue2.length;
};<扩展>只用一个队列
一个队列在模拟栈弹出元素的时候只要将队列头部的元素(除了最后一个元素外) 重新添加到队列尾部,此时再去弹出元素就是栈的顺序了。
// 使用一个队列实现
/**
* Initialize your data structure here.
*/
var MyStack = function() {
this.queue = [];
};
/**
* Push element x onto stack.
* @param {number} x
* @return {void}
*/
MyStack.prototype.push = function(x) {
this.queue.push(x);
};
/**
* Removes the element on top of the stack and returns that element.
* @return {number}
*/
MyStack.prototype.pop = function() {
let size = this.queue.length;
while(size-- > 1) {
this.queue.push(this.queue.shift());
}
return this.queue.shift();
};
/**
* Get the top element.
* @return {number}
*/
MyStack.prototype.top = function() {
const x = this.pop();
this.queue.push(x);
return x;
};
/**
* Returns whether the stack is empty.
* @return {boolean}
*/
MyStack.prototype.empty = function() {
return !this.queue.length;
};LeetCode:20. 有效的括号
由于栈结构的特殊性,非常适合做对称匹配类的题目。括号匹配是使用栈解决的经典问题。题意其实就像我们在写代码的过程中,要求括号的顺序是一样的,有左括号,相应的位置必须要有右括号。如果还记得编译原理的话,编译器在词法分析的过程中处理括号、花括号等这个符号的逻辑,也是使用了栈这种数据结构。
首先要弄清楚,字符串里的括号不匹配有几种情况。第一种情况,字符串里左方向的括号多余了 ,所以不匹配。第二种情况,括号没有多余,但是 括号的类型没有匹配上。第三种情况,字符串里右方向的括号多余了,所以不匹配。我们的代码只要覆盖了这三种不匹配的情况,就不会出问题。
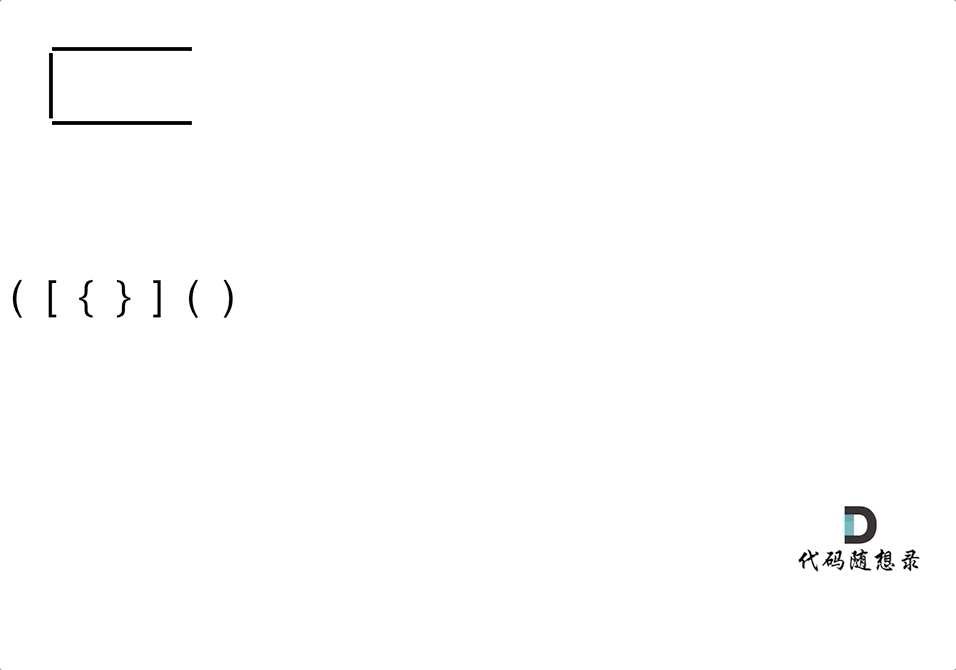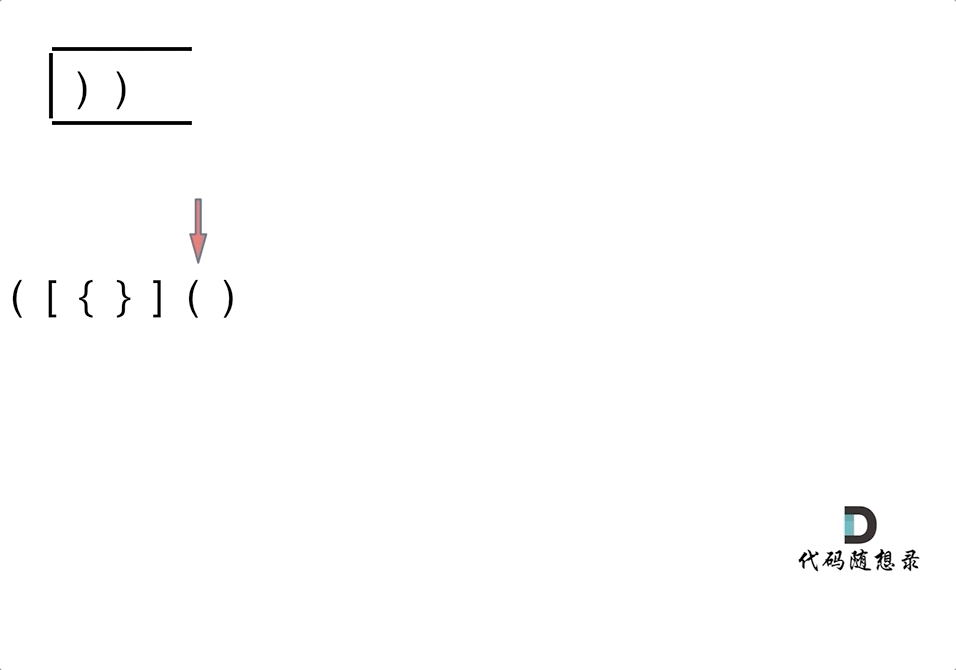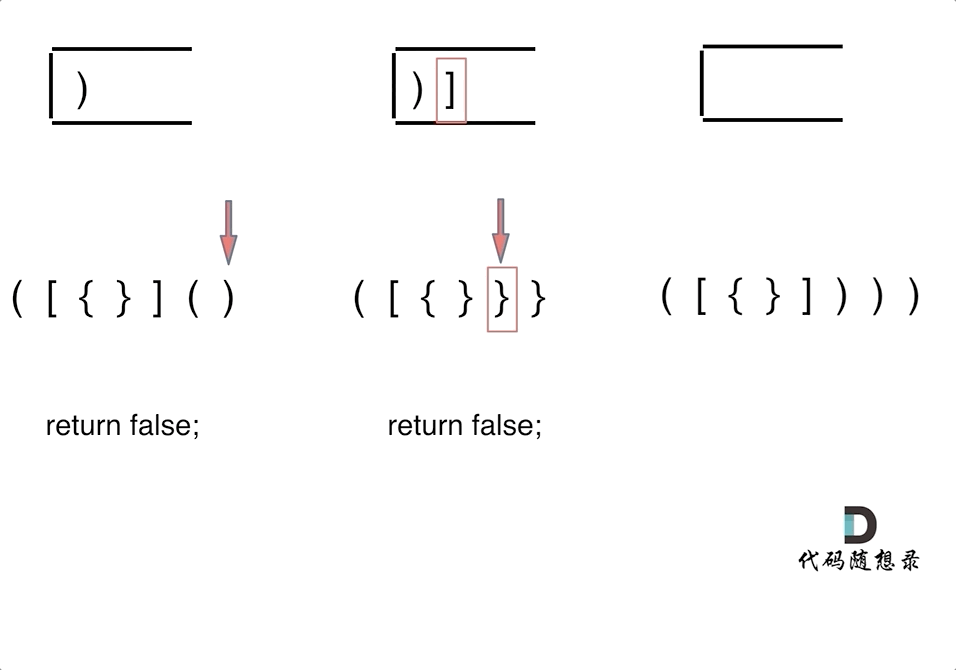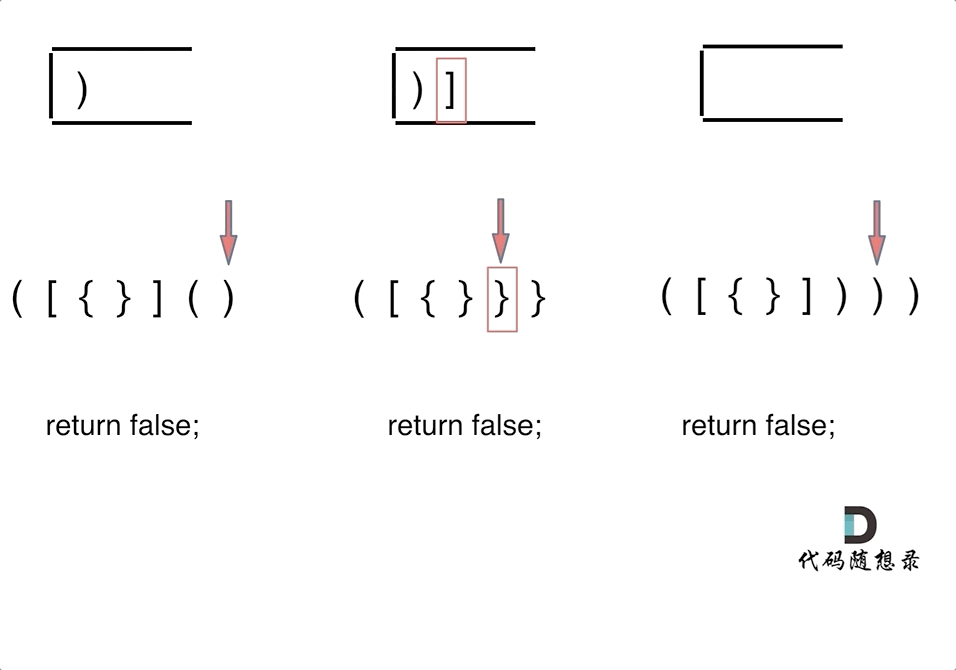
第一种情况:已经遍历完了字符串,但是栈不为空,说明有相应的左括号没有右括号来匹配,所以return false第二种情况:遍历字符串匹配的过程中,发现栈里没有要匹配的字符。所以return false第三种情况:遍历字符串匹配的过程中,栈已经为空了,没有匹配的字符了,说明右括号没有找到对应的左括号return false。那么什么时候说明左括号和右括号全都匹配了呢,就是字符串遍历完之后,栈是空的,就说明全都匹配了。
var isValid = function (s) {
const stack = [];
for (let i = 0; i < s.length; i++) {
let c = s[i];
switch (c) {
case '(':
stack.push(')');
break;
case '[':
stack.push(']');
break;
case '{':
stack.push('}');
break;
default:
if (c !== stack.pop()) {
return false;
}
}
}
return stack.length === 0;
};
// 简化版本
var isValid = function(s) {
const stack = [],
map = {
"(":")",
"{":"}",
"[":"]"
};
for(const x of s) {
if(x in map) {
stack.push(x);
continue;
};
if(map[stack.pop()] !== x) return false;
}
return !stack.length;
};LeetCode:1047. 删除字符串中的所有相邻重复项
本题要删除相邻相同元素,相对于20. 有效的括号 (opens new window)来说其实也是匹配问题,20. 有效的括号 是匹配左右括号,本题是匹配相邻元素,最后都是做消除的操作。本题也是用栈来解决的经典题目。
栈的目的,就是存放遍历过的元素,当遍历当前的这个元素的时候,去栈里看一下我们是不是遍历过相同数值的相邻元素。然后再去做对应的消除操作。
var removeDuplicates = function(s) {
const stack = [];
for(const x of s) {
let c = null;
if(stack.length && x === (c = stack.pop())) continue;
c && stack.push(c);
stack.push(x);
}
return stack.join("");
};<扩展>双指针
// 原地解法(双指针模拟栈)
var removeDuplicates = function(s) {
s = [...s];
let top = -1; // 指向栈顶元素的下标
for(let i = 0; i < s.length; i++) {
if(top === -1 || s[top] !== s[i]) { // top === -1 即空栈
s[++top] = s[i]; // 入栈
} else {
top--; // 推出栈
}
}
s.length = top + 1; // 栈顶元素下标 + 1 为栈的长度
return s.join('');
};LeetCode:150. 逆波兰表达式求值
逆波兰表达式是一种后缀表达式,所谓后缀就是指算符写在后面。平常使用的算式则是一种中缀表达式,如 ( 1 + 2 ) * ( 3 + 4 ) 。该算式的逆波兰表达式写法为 ( ( 1 2 + ) ( 3 4 + ) * ) 。
逆波兰表达式主要有以下两个优点:①去掉括号后表达式无歧义,上式即便写成 1 2 + 3 4 + * 也可以依据次序计算出正确结果。②适合用栈操作运算:遇到数字则入栈;遇到算符则取出栈顶两个数字进行计算,并将结果压入栈中
逆波兰表达式相当于是二叉树中的后序遍历。 大家可以把运算符作为中间节点,按照后序遍历的规则画出一个二叉树。但我们没有必要从二叉树的角度去解决这个问题,只要知道逆波兰表达式是用后序遍历的方式把二叉树序列化了,就可以了。
在进一步看,本题中每一个子表达式要得出一个结果,然后拿这个结果再进行运算,那么这岂不就是一个相邻字符串消除的过程,和1047.删除字符串中的所有相邻重复项 (opens new window)中的对对碰游戏是不是就非常像了。
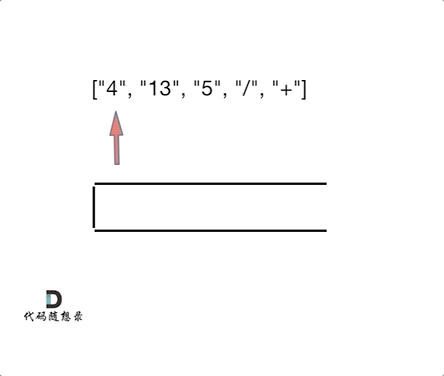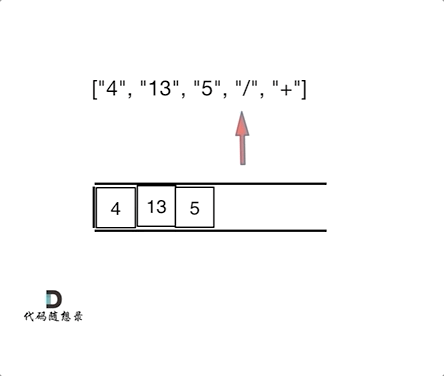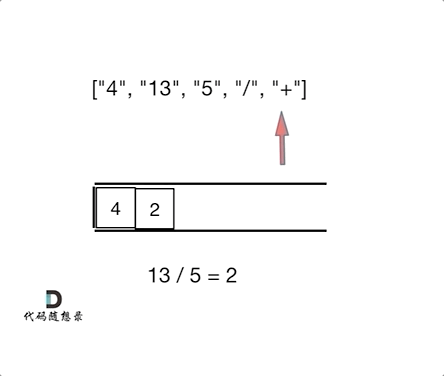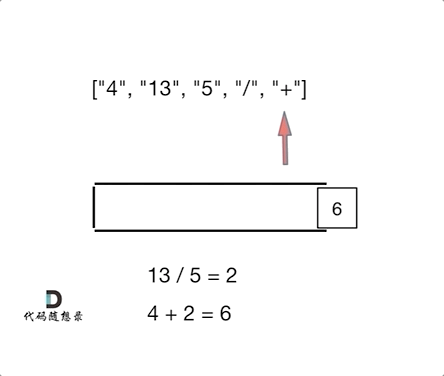
我们习惯看到的表达式都是中缀表达式,因为符合我们的习惯,但是中缀表达式对于计算机来说就不是很友好了。例如:4 + 13 / 5,这就是中缀表达式,计算机从左到右去扫描的话,扫到13,还要判断13后面是什么运算符,还要比较一下优先级,然后13还和后面的5做运算,做完运算之后,还要向前回退到 4 的位置,继续做加法,你说麻不麻烦!那么将中缀表达式,转化为后缀表达式之后:["4", "13", "5", "/", "+"] ,就不一样了,计算机可以利用栈来顺序处理,不需要考虑优先级了。也不用回退了, 所以后缀表达式对计算机来说是非常友好的。
var evalRPN = function (tokens) {
const stack = [];
for (const token of tokens) {
if (isNaN(Number(token))) { // 非数字
const n2 = stack.pop(); // 出栈两个数字
const n1 = stack.pop();
switch (token) { // 判断运算符类型,算出新数入栈
case "+":
stack.push(n1 + n2);
break;
case "-":
stack.push(n1 - n2);
break;
case "*":
stack.push(n1 * n2);
break;
case "/":
stack.push(n1 / n2 | 0);
break;
}
} else { // 数字
stack.push(Number(token));
}
}
return stack[0]; // 因没有遇到运算符而待在栈中的结果
};<扩展>带括号得字符串的表达式
LeetCode:239. 滑动窗口最大值
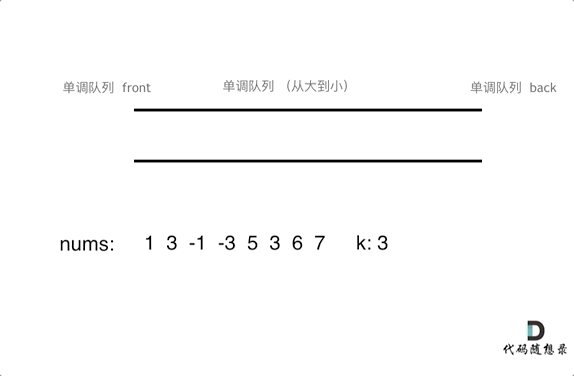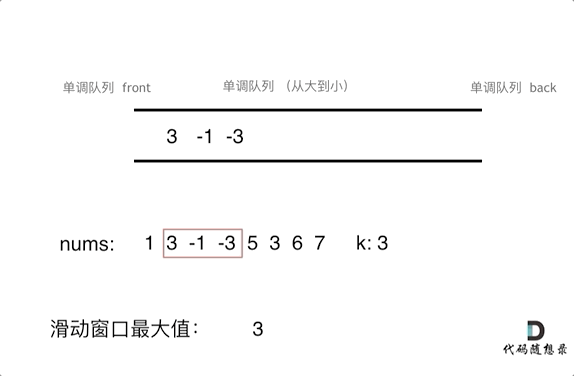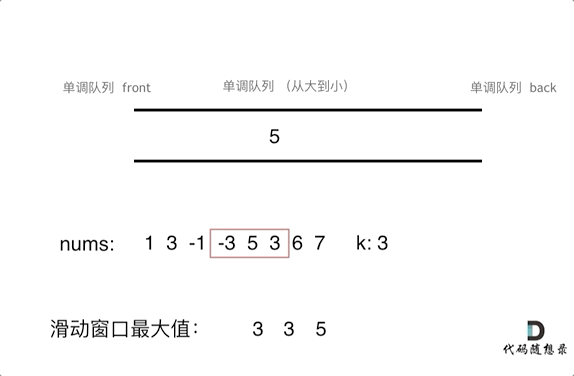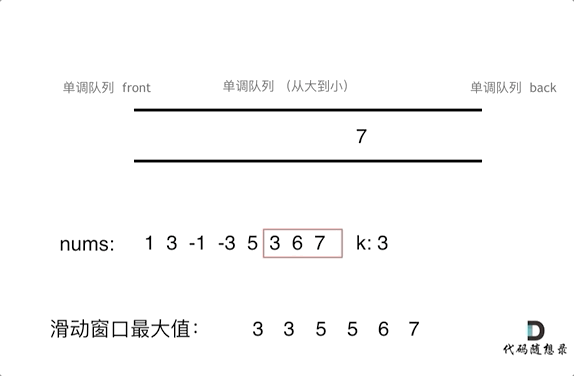
用一个队列,放进去窗口里的元素,然后随着窗口的移动,队列也一进一出,每次移动之后,队列告诉我们里面的最大值是什么。
队列里的元素一定是要排序的,而且要最大值放在出队口,要不然怎么知道最大值呢。但如果把窗口里的元素都放进队列里,窗口移动的时候,队列需要弹出元素。
其实队列没有必要维护窗口里的所有元素,只需要维护有可能成为窗口里最大值的元素就可以了,同时保证队列里的元素数值是由大到小的。那么这个维护元素单调递减的队列就叫做单调队列,即单调递减或单调递增的队列。不要以为实现的单调队列就是对窗口里面的数进行排序,如果排序的话,那和优先级队列又有什么区别了呢。
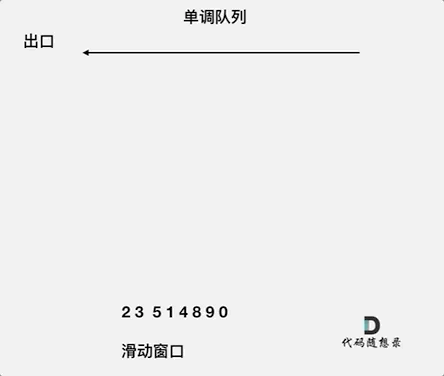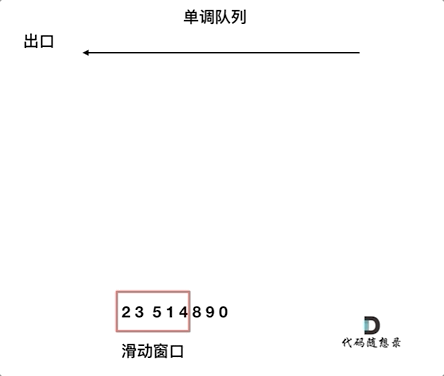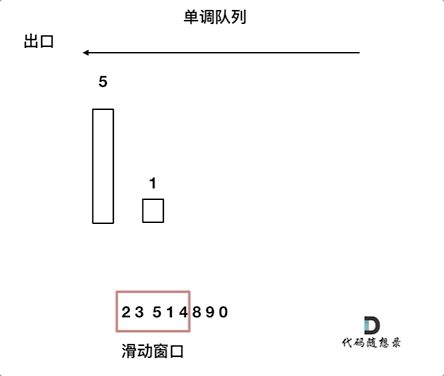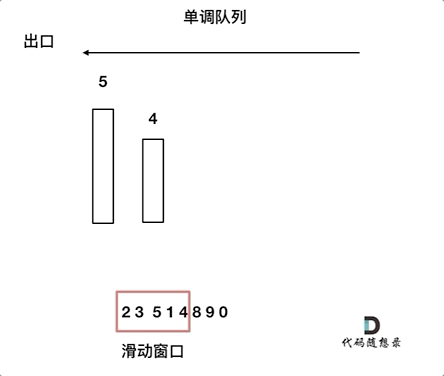
来看一下单调队列如何维护队列里的元素。对于窗口里的元素{2, 3, 5, 1 ,4},单调队列里只维护{5, 4} 就够了,保持单调队列里单调递减,此时队列出口元素就是窗口里最大元素。此时大家应该怀疑单调队列里维护着{5, 4} 怎么配合窗口进行滑动呢?设计单调队列的时候,pop,和push操作要保持如下规则:
- pop(value):如果窗口移除的元素value等于单调队列的出口元素,那么队列弹出元素,否则不用任何操作
- push(value):如果push的元素value大于入口元素的数值,那么就将队列入口的元素弹出,直到push元素的数值小于等于队列入口元素的数值为止
保持如上规则,每次窗口移动的时候,只要问que.front()就可以返回当前窗口的最大值。为了更直观的感受到单调队列的工作过程,以题目示例为例,输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3
var maxSlidingWindow = function (nums, k) {
//JavaScript没有单调队列,自己定义一个
class MonoQueue {
queue;
constructor() {
this.queue = [];
}
enqueue(value) {
let back = this.queue[this.queue.length - 1]; //队尾元素
while (back !== undefined && back < value) { //如果窗口移出元素value大于队列出口元素back
this.queue.pop(); //队列入口元素弹出
back = this.queue[this.queue.length - 1];
}
this.queue.push(value); //将窗口元素进入队列
}
dequeue(value) { //如果窗口移除的元素value等于单调队列的出口元素,那么队列弹出元素,否则不用任何操作
let front = this.front();
if (front === value) {
this.queue.shift();
}
}
front() { //返回当前窗口的最大值
return this.queue[0];
}
}
let helperQueue = new MonoQueue();
let i = 0, j = 0;
let resArr = [];
while (j < k) { //数组下标<窗口大小
helperQueue.enqueue(nums[j++]); //将该元素队列
}
resArr.push(helperQueue.front()); //窗口的最大值加入resArr
while (j < nums.length) {
helperQueue.enqueue(nums[j]);
helperQueue.dequeue(nums[i]);
resArr.push(helperQueue.front());
i++, j++;
}
return resArr;
};LeetCode:347.前 K 个高频元素
这道题目主要涉及到如下三块内容:
- 要统计元素出现频率
- 对频率排序
- 找出前K个高频元素
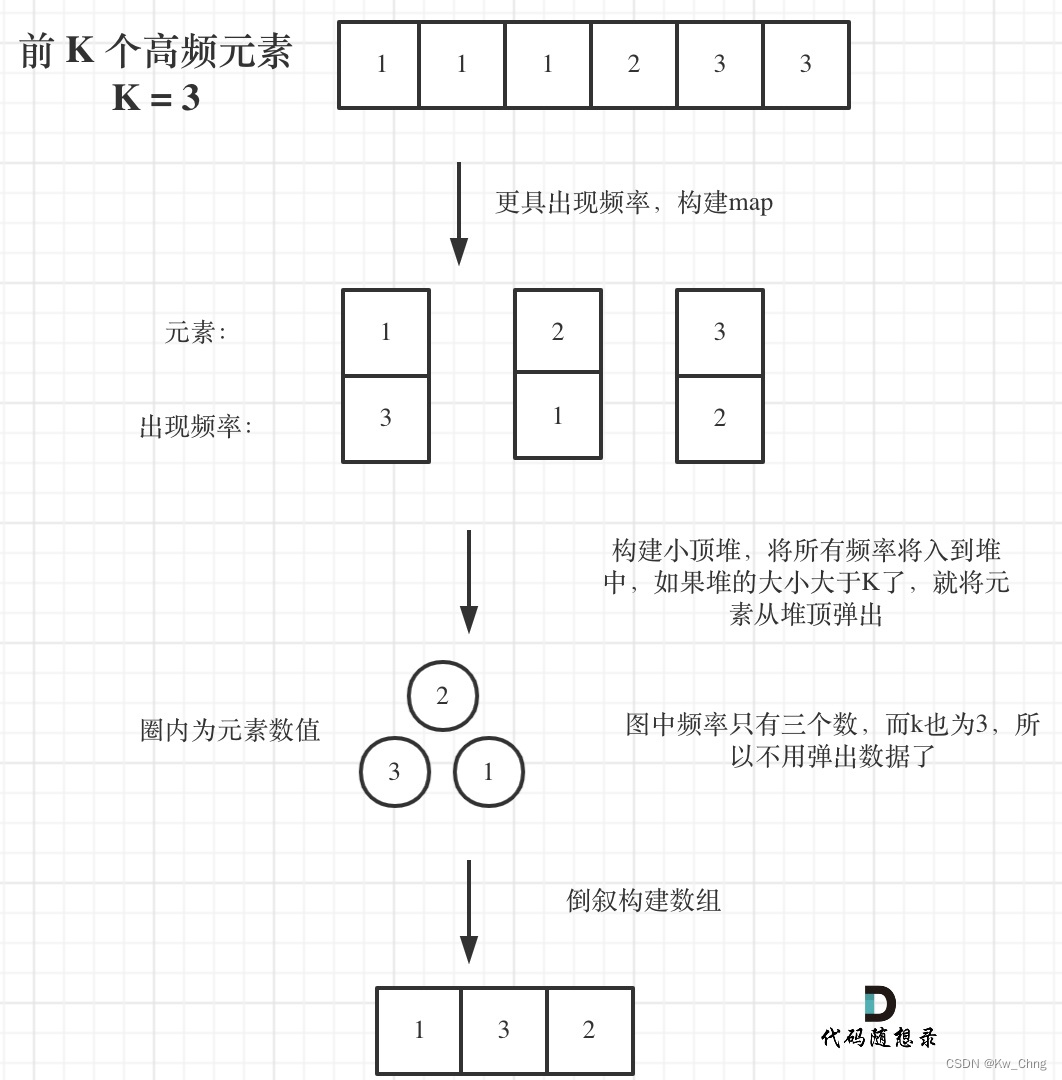
首先统计元素出现的频率,这一类的问题可以使用map来进行统计。然后是对频率进行排序,这里我们可以使用一种容器适配器就是优先级队列。
什么是优先级队列呢?其实就是一个披着队列外衣的堆,因为优先级队列对外接口只是从队头取元素,从队尾添加元素,再无其他取元素的方式,看起来就是一个队列。而且优先级队列内部元素是自动依照元素的权值排列。
那么它是如何有序排列的呢?缺省情况下priority_queue利用max-heap(大顶堆)完成对元素的排序,这个大顶堆是以vector为表现形式的complete binary tree(完全二叉树)。
什么是堆呢?堆是一棵完全二叉树,树中每个结点的值都不小于(或不大于)其左右孩子的值。 如果父亲结点是大于等于左右孩子就是大顶堆,小于等于左右孩子就是小顶堆。所以大家经常说的大顶堆(堆头是最大元素),小顶堆(堆头是最小元素),如果懒得自己实现的话,就直接用priority_queue(优先级队列)就可以了,底层实现都是一样的,从小到大排就是小顶堆,从大到小排就是大顶堆。
是使用小顶堆呢,还是大顶堆?题目要求前 K 个高频元素,那么果断用大顶堆啊。那么问题来了,定义一个大小为k的大顶堆,在每次移动更新大顶堆的时候,每次弹出都把最大的元素弹出去了,那么怎么保留下来前K个高频元素呢。而且使用大顶堆就要把所有元素都进行排序,那能不能只排序k个元素呢?所以我们要用小顶堆,因为要统计最大前k个元素,只有小顶堆每次将最小的元素弹出,最后小顶堆里积累的才是前k个最大元素。
// js 没有堆 需要自己构造
class Heap {
constructor(compareFn) {
this.compareFn = compareFn;
this.queue = [];
}
// 添加
push(item) {
// 推入元素
this.queue.push(item);
// 上浮
let index = this.size() - 1; // 记录推入元素下标
let parent = Math.floor((index - 1) / 2); // 记录父节点下标
while (parent >= 0 && this.compare(parent, index) > 0) { // 注意compare参数顺序
[this.queue[index], this.queue[parent]] = [this.queue[parent], this.queue[index]];
// 更新下标
index = parent;
parent = Math.floor((index - 1) / 2);
}
}
// 获取堆顶元素并移除
pop() {
// 堆顶元素
const out = this.queue[0];
// 移除堆顶元素 填入最后一个元素
this.queue[0] = this.queue.pop();
// 下沉
let index = 0; // 记录下沉元素下标
let left = 1; // left 是左子节点下标 left + 1 则是右子节点下标
let searchChild = this.compare(left, left + 1) > 0 ? left + 1 : left;
while (searchChild !== undefined && this.compare(index, searchChild) > 0) { // 注意compare参数顺序
[this.queue[index], this.queue[searchChild]] = [this.queue[searchChild], this.queue[index]];
// 更新下标
index = searchChild;
left = 2 * index + 1;
searchChild = this.compare(left, left + 1) > 0 ? left + 1 : left;
}
return out;
}
size() {
return this.queue.length;
}
// 使用传入的 compareFn 比较两个位置的元素
compare(index1, index2) {
// 处理下标越界问题
if (this.queue[index1] === undefined) return 1;
if (this.queue[index2] === undefined) return -1;
return this.compareFn(this.queue[index1], this.queue[index2]);
}
}
const topKFrequent = function (nums, k) {
const map = new Map();
for (const num of nums) {
map.set(num, (map.get(num) || 0) + 1);
}
// 创建小顶堆
const heap= new Heap((a, b) => a[1] - b[1]);
// entry 是一个长度为2的数组,0位置存储key,1位置存储value
for (const entry of map.entries()) {
heap.push(entry);
if (heap.size() > k) {
heap.pop();
}
}
// return heap.queue.map(e => e[0]);
const res = [];
for (let i = heap.size() - 1; i >= 0; i--) {
res[i] = heap.pop()[0];
}
return res;
};Python解法,时间超过90%用户,空间超40%
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
dic = defaultdict(int)
for i in range(len(nums)):
dic[nums[i]] += 1
new = sorted(dic.items(), key=lambda item:item[1], reverse=True)[:k]
ans = []
for i in new:
ans.append(i[0])
return ans<扩展>桶排序















 193
193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









