







文档
HyperLogLog
HyperLogLog(HLL)是从Loglog算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值。相关算法原理大家可以参考: https://juejin.cn/post/6844903785744056333#heading-0
Redis中的HLL是基于String结构实现的,单个HLL的内存永远小于16kb,内存占用低的令人发指!作为代价,其测量结果是概率性的,有小于0.81%的误差。不过对于UV统计来说,这完全可以忽略。
不会存储输入的元素的本身,会根据输入的元素来计算基数。
统计 APP或网页 的一个页面,每天有多少用户点击进入的次数。同一个用户的反复点击进入记为 1 次。
PFADD 添加一个元素
PFADD key [element [element ...]]命令描述
key:键
element:添加一个元素。也可以添加多个元素
PFCOUNT 统计元素个数
PFCOUNT key [key ...]命令描述
key:键。添加多个key。如果多key中存储相同元素的时候,统计出来的会去除相同元素的。
比如,key1 key2分别都有3个元素。使用PFCOUNT 一起统计两个key的个数就只有5个。
key1: 1 2 3
key2: 3 4 5
PFMERGE 多个key合并生成一个新的key
将多个HyperLogLog值合并成为一个唯一值。
PFMERGE destkey sourcekey [sourcekey ...]命令描述
destkey:新的key
sourcekey:需要合并的多个key
Bitmap 位图
Bitmap,即位图,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素。BitMap通过最小的单位bit来进行0|1的设置,表示某个元素的值或者状态,时间复杂度为O(1)。由于bit是计算机中最小的单位,使用它进行储存将非常节省空间,特别适合一些数据量大且使用二值统计的场景。

这里的二值状态就是指集合元素的取值就只有 0 和 1 两种。例如在签到打卡的场景中,我们只用记录签到(1)或未签到(0),所以它就是非常典型的二值状态。在签到统计时,每个用户一天的签到用 1 个 bit 位就能表示,一个月(假设是 31 天)的签到情况用 31 个 bit 位就可以,而一年的签到也只需要用 365 个 bit 位,根本不用太复杂的集合类型。这个时候,我们就可以选择 Bitmap。
Bitmap不属于Redis的基本数据类型,而是基于String类型进行的位操作。而Redis中字符串的最大长度是 512M,所以 BitMap 的 offset 值也是有上限的,其最大值是:8 * 1024 * 1024 * 512 = 2^32
常用命令
SETBIT:向指定位置(offset)存入一个0或1
GETBIT:获取指定位置(offset)的bit值
BITCOUNT:统计BitMap中值为1的bit位的数量
BITFIELD:可以用来操作(查询、修改、自增)BitMap数组中指定位置(offset)的值(一般只用来查询)
BITPOS:查找bit数组中的指定范围内的第一个0或1出现的位置
SETBIT 指定位置存入0或1
SETBIT命令会返回指定偏移量原来储存的值。
原来是0就会返回0 。原来是1就会返回1。不管他
SETBIT key offset valuekey:键
offset:存入第几位。偏移量
value:0或1
GETBIT 获取指定位置的bit值
获取指位置(offset)的bit值返回int
GETBIT key offset命令描述
key:键
返回key对应的字符串,offset位置的位(bit)
offset:取出第几位的bit值 (integer)。偏移量
当key不存在时,会返回0
offset肯定大于字符串长度也返回0
BITCOUNT 统计BitMap中值为1的bit位数量
BITCOUNT key [start end]key:键
**[start end]**:从第几个到第几个==字节==(注意这里是字节的位置,一个字节8个bit)从左到右
一般不用管负数了。正常玩正数就行
start 和 end也可以是负数,-1表示最后一个字节,-2表示倒数第二个字节。注意这里是字节,1字节=8比特
示例
a:01000101 --> 3个1
b:01000111 --> 4个1
c:01001111 --> 5个1
Key : a b c -> 01000101 01000111 01001111
统计全部1
BITCOUNT Key
统计a有多少个1
BITCOUNT Key 0 0
统计b有多少个1
BITCOUNT Key 1 1
统计c有多少个1
BITCOUNT Key 2 2
统计b~c有多少个1
BITCOUNT Key 1 2
BITFIELD 操作(查询、修改、自增)指定位置的值
这个可以操作(查询、修改、自增)。一般用来查询。所以下面演示查询的
BITFIELD key [GET type offset] [SET type offset value] [INCRBY type offset increment] [OVERFLOW WRAP|SAT|FAIL]key:键
GET
type 返回有符号和无符号 后面带上获取多少个**==bit==**位 [u | i count]
u:无符号
i: 有符号
offset :从第几位bit开始。从左到右
示例
01000101
获取前面三个bit位的值。
BITFIELD bit get u3 0
返回2。0000 0010。是以这样的形式去返回十进制的
u代表无符号 3获取三个 0就是从0个bit开始
BITPOS 查找第一个0或1
查找bit数组中指定范围内第一个0或1出现的位置
BITPOS key bit [start [end]]key:键
bit:指定一个0或1。当找到了就会放回bit的位置
当指定1的时候,指定范围没找到1的bit位置就会返回 -1
当指定0的时候,指定范围没找到返回0
start:从多少开始
end:多少结束。
GEO 存储经纬度
Redis GEO 主要用于存储地理位置信息,并对存储的信息进行操作,该功能在 Redis 3.2 版本新增。
可以用来做附近的商品、人什么的
在文档里面是 Geospatial indices 简称GEO
常用命令
GEOADD:添加地理位置的坐标。经度(longitude)、纬度(latitude)、值(member)
GEODIST:计算两个点之间的距离并返回
GEOPOS:获取member的坐标。
GEOHASH:获取指定member的坐标的hash字符串
GEOSEARCH:在指定范围内搜索member,并按照与指定地点之间的距离排序后返回。范围可以是圆形或矩形。(查找10km内的酒店等等。附近的功能)
GEOADD 添加
添加地理位置的坐标。经度(longitude)、纬度(latitude)、值(member)
三个为一组,可以一次性添加多组
GEOADD key longitude latitude member [longitude latitude member ...]
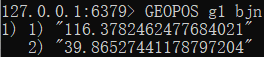
GEOADD g1 116.378248 39.865275 bjn 116.42803 39.903738 bj 116.322287 39.893729 bjx
(返回3,因为添加了3条)longitude:经度
latitude:纬度
member:值
GEODIST 计算两点距离
传入两个值,计算出距离
GEODIST key member1 member2 [m|km|ft|mi] [米|千米|英尺|英里]key:键
member1 、member2 :传入地理位置的值
最后一个距离单位参数说明:
m :米,默认单位
km :千米
ft :英尺
mi :英里
GEOPOS 获取坐标
GEOPOS key member [member ...]key:键
member :传入地理位置的值,可以传入多个
GEOHASH 获取坐标的hash字符串
GEOHASH key member [member ...]key:键
member :传入地理位置的值,可以传入多个

GEOSEARCH 搜索指定范围内的地理位置
GEOSEARCH key
[<FROMMEMBER member | FROMLONLAT longitude latitude>]
<BYRADIUS radius <M | KM | FT | MI> | BYBOX width height <M | KM | FT | MI>>
[ASC | DESC]
[COUNT count [ANY]]
[WITHCOORD]
[WITHDIST]
[WITHHASH]第一个参数 作为搜索中心 <FROMMEMBER member | FROMLONLAT longitude latitude>
FROMMEMBER:使用给定的存在member于排序集中的位置。
FROMLONLAT: 使用给定longitude和latitude位置。给定经纬度
第二个参数 <BYRADIUS radius <M | KM | FT | MI> | BYBOX width height <M | KM | FT | MI>>
BYRADIUS 根据给定的在圆形区域内搜索。半径
radius 圆的半径 输入数字
<M | KM | FT | MI> <米|千米|英尺|英里> 半径的单位
BYBOX 根据矩形搜索。单位
width height 矩形的宽高
<米|千米|英尺|英里> 宽高的单位
**[ASC | DESC]**: 二选一
ASC: 以中心点为中心,从近到远对返回的物品进行排序。
DESC:以中心点为基准,从远到近对返回的物品进行排序。
[COUNT count]
取多少条
WITHCOORD: 同时返回位置元素的经纬度。
WITHDIST: 返回位置元素和指定中心点的距离
WITHHASH:这个应该是位置元素的hash值。经纬度转成hash值 GEOHASH命令输出的那种
SortedSet 有序集合
常用命令
ZADD 添加一个元素
ZCARD 获取集合中有多少个元素)
**ZRANGE ** 获取指定索引范围的元素
ZREVRANGEBYSCORE 指定分数区间查询 分页查询 范围查询 根据分数
ZADD
添加一个元素
ZADD key [sorted value] ...
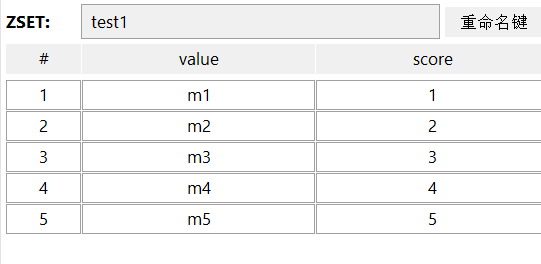
ZADD test1 1 m1 2 m2 3 m3 4 m4 5 m5key:集合的键
srted :指定分数值
value :值
ZCARD 获取集合中有多少个元素
ZCARD key
ZCARD test1 key:集合的键

ZRANGE 获取指定索引范围的元素
ZRANGE key start stop
ZRANGE test1 0 2
ZREVRANGEBYSCORE 根据分数区间进行查询
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]key:集合的键
max:分数的最大值
min:分数的最小值
WITHSCORES 查询结果是否携带分数
LIMIT
offset:偏移量,就是跳过的个数
count:查询的个数
示例
分页查询
需求 每页查询3条
1、先查询前三条
这里可以看到查询出来了两个相同的分数值
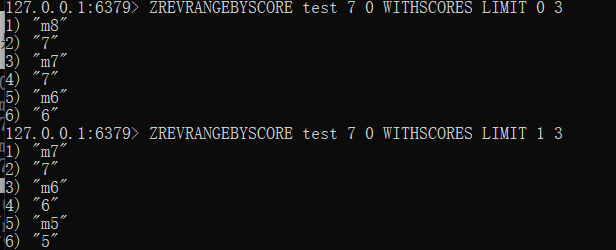
ZREVRANGEBYSCORE test 8 0 WITHSCORES LIMIT 0 3
2、第二次查询
然后根据查询出来的最小分数值 放到max里面。然后offset设置为2,因为上一次查询可以看到查询出来了两个相同分数值,使用需要跳过两个。
查看结果,可以看到是已经跳过了两个7.

那么如果不设置偏移量为2,而是设置为1或者0就会出现,重复获取到分数为7的值了。看下图
3、以此类推
将上一次的最小分数值放到这一次的max里面。offset就根据有多少个重复的分数来设置(如果没有重复那就是1,因为要跳过上一个max)。

Stream 流
Stream 流主要用于消息队列(MQ,Message Queue),Redis本身有一个Redis发布订阅 (pub/sub) 来实现消息队列的功能,但它有一个确定就是无法做到消息的持久化(保存到客户端的),如果网络断开、Redis宕机等,消息就会被丢弃。
简单来说发布订阅可以做到分发消息,但不能持久化消息(无法记录历史消息)。
而Stream提供了消息的持久化和主备复制的功能,可以让任何客户端访问到任何时刻的数据,并记录每个客户端访问的位置。
常用命令
XADD - 添加消息到末尾
XGROUP CREATE - 创建消费者组
XREADGROUP GROUP - 读取消费者组中的消息
XACK - 将消息标记为"已处理"
需要提前创建消费组才能读取
XGROUP CREATE 创建消费者组
XGROUP CREATE key groupname <id | $> [MKSTREAM]
XGROUP CREATE queueKey xfzName $ MKSTREAM
XGROUP CREATE queueKey(队列名称) xfzName(消费者组名称) $ MKSTREAM (这一条就把队列和消费者组创建好了)key :队列名称,如果不存在就创建
groupname :消费者组名称
$ : 表示从尾部开始消费,只接受新消息,当前 Stream 消息会全部忽略。
MKSTREAM : 子命令作为最后一个参数自动创建长度为 0 的流(反正加上就是会创建一个队列,一般带上就好了)
https://redis.io/commands/xgroup-create/
XADD 给消费者组发送信息
XADD key ID field value [field value ...]
XADD queueKey * name LM address GdGzPykey :队列名称,如果不存在就创建
ID :消息 id,我们使用 * 表示由 redis 生成,可以自定义,但是要自己保证递增性。
field value : 记录。{"address":"GdGzPy","name":"LM"} 存储结构
XREADGROUP GROUP 读取消费者组中的消息
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] id [id ...]
XREADGROUP GROUP xfzName Order COUNT 1 BLOCK 10000 STREAMS queueKey >
XREADGROUP GROUP
xfzName(消费者组名称-这个用来ACK) Order(消费者名称随便)
COUNT 1 BLOCK 10000
STREAMS queueKey(队列key)
>group:消费者组名称
consumer:消费者名字
COUNT:读取多少条消息
BLOCK:是否堵塞读取 读取多少毫秒。0表示一直堵塞直到获取消息成功
NOACK:加上这个好像就不需要确认消息,就没有未处理消息的队列了。==反正没事不加,一般不加==
STREAMS:指定队列名称
ID : 消息 ID
==>== 就是读取一条没有被任何客户端读取过的最新消息
==0== 读取第一条没有被ACK的信息
==1== 读取第二条没有被ACK的信息
。。。以此类推。但比如队列中只有3条信息,你写了4或者5、6、7 什么的就会读取第一条信息
XACK 消费者成功消费一条信息
XACK key group id [id ...]
XACK queueKey(队列key) xfzName(消费者组名称) 1674182289845-0key:队列key
group:消费者组名称
id:读取到信息的id














 406
406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









