






2023-SQLZOO刷题下(8-9,题目+答案+解析)
作为一名新手推荐算法工程师,不仅需要做建模相关的工作,还需要处理许多数据方面的问题。
SQLZOO是一个很好的SQL刷题网站,可以快速的巩固和温习一下写SQL的能力。
说明:
0-7的题目部分为中文
详见:2023-SQLZOO刷题上(0-7,题目+答案+解析)
8-12的题目部分为英中双语
前言
不忘初心,坚持热爱。——Tusunny
文章目录
- 2023-SQLZOO刷题下(8-9,题目+答案+解析)
- 前言
- 8 Using Null
- 1.List the teachers who have NULL for their department.
- 2.Note the INNER JOIN misses the teachers with no department and the departments with no teacher.
- 3.Use a different JOIN so that all teachers are listed.
- 4.Use a different JOIN so that all departments are listed.
- 5.Use COALESCE to print the mobile number. Use the number '07986 444 2266' if there is no number given. Show teacher name and mobile number or '07986 444 2266'
- 6.Use the COALESCE function and a LEFT JOIN to print the teacher name and department name. Use the string 'None' where there is no department.
- 7.Use COUNT to show the number of teachers and the number of mobile phones.
- 8.使用COUNT 和 GROUP BY dept.name來顯示每一學系的老師數目。 使用 RIGHT JOIN 以確保工程系Engineering 是在當中。
- 9.Use CASE to show the name of each teacher followed by 'Sci' if the teacher is in dept 1 or 2 and 'Art' otherwise.
- 10.Use CASE to show the name of each teacher followed by 'Sci' if the teacher is in dept 1 or 2, show 'Art' if the teacher's dept is 3 and 'None' otherwise.
- 8+ Numeric Examples
- 1.The example shows the number who responded for:
- 2.Show the institution and subject where the score is at least 100 for question 15.
- 3.Show the institution and score where the score for '(8) Computer Science' is less than 50 for question 'Q15'.
- 4.Show the subject and total number of students who responded to question 22 for each of the subjects '(8) Computer Science' and '(H) Creative Arts and Design'.
- 5.Show the subject and total number of students who A_STRONGLY_AGREE to question 22 for each of the subjects '(8) Computer Science' and '(H) Creative Arts and Design'.
- 6.Show the percentage of students who A_STRONGLY_AGREE to question 22 for the subject '(8) Computer Science' show the same figure for the subject '(H) Creative Arts and Design'.Use the ROUND function to show the percentage without decimal places.
- 7.Show the average scores for question 'Q22' for each institution that include 'Manchester' in the name.
- 8.Show the institution, the total sample size and the number of computing students for institutions in Manchester for 'Q01'.
- 9- Window function
- 1.Show the lastName, party and votes for the constituency 'S14000024' in 2017.
- 2.You can use the RANK function to see the order of the candidates. If you RANK using (ORDER BY votes DESC) then the candidate with the most votes has rank 1.
- 3.The 2015 election is a different PARTITION to the 2017 election. We only care about the order of votes for each year.
- 4.Edinburgh constituencies are numbered S14000021 to S14000026.Use PARTITION BY constituency to show the ranking of each party in Edinburgh in 2017. Order your results so the winners are shown first, then ordered by constituency.
- 5.You can use SELECT within SELECT to pick out only the winners in Edinburgh.Show the parties that won for each Edinburgh constituency in 2017.
- 6.You can use COUNT and GROUP BY to see how each party did in Scotland. Scottish constituencies start with 'S'.Show how many seats for each party in Scotland in 2017.
- 9+ COVID 19
- 1.The example uses a WHERE clause to show the cases in 'Italy' in March 2020.Modify the query to show data from Spain
- 2.The LAG function is used to show data from the preceding row or the table. When lining up rows the data is partitioned by country name and ordered by the data whn. That means that only data from Italy is considered.Modify the query to show confirmed for the day before.
- 3.The number of confirmed case is cumulative - but we can use LAG to recover the number of new cases reported for each day.Show the number of new cases for each day, for Italy, for March.
- 4.The data gathered are necessarily estimates and are inaccurate. However by taking a longer time span we can mitigate some of the effects.You can filter the data to view only Monday's figures WHERE WEEKDAY(whn) = 0.Show the number of new cases in Italy for each week - show Monday only.
- 5.You can JOIN a table using DATE arithmetic. This will give different results if data is missing.Show the number of new cases in Italy for each week - show Monday only.In the sample query we JOIN this week tw with last week lw using the DATE_ADD function.
- 6.The query shown shows the number of confirmed cases together with the world ranking for cases.United States has the highest number, Spain is number 2...Notice that while Spain has the second highest confirmed cases, Italy has the second highest number of deaths due to the virus.Include the ranking for the number of deaths in the table.
- 7.The query shown includes a JOIN t the world table so we can access the total population of each country and calculate infection rates (in cases per 100,000).Show the infect rate ranking for each country. Only include countries with a population of at least 10 million.
- 8.For each country that has had at last 1000 new cases in a single day, show the date of the peak number of new cases.
- 9 Self join
- 1.How many stops are in the database.
- 2.Find the id value for the stop 'Craiglockhart'
- 3.Give the id and the name for the stops on the '4' 'LRT' service. Some of the data is incorrect.
- 4.The query shown gives the number of routes that visit either London Road (149) or Craiglockhart (53). Run the query and notice the two services that link these stops have a count of 2. Add a HAVING clause to restrict the output to these two routes.
- 5.Execute the self join shown and observe that b.stop gives all the places you can get to from Craiglockhart, without changing routes. Change the query so that it shows the services from Craiglockhart to London Road.
- 6.The query shown is similar to the previous one, however by joining two copies of the stops table we can refer to stops by name rather than by number. Change the query so that the services between 'Craiglockhart' and 'London Road' are shown. If you are tired of these places try 'Fairmilehead' against 'Tollcross'.
- 7.Give a list of all the services which connect stops 115 and 137 ('Haymarket' and 'Leith').
- 8.Give a list of the services which connect the stops 'Craiglockhart' and 'Tollcross'.
- 9.Give a distinct list of the stops which may be reached from 'Craiglockhart' by taking one bus, including 'Craiglockhart' itself, offered by the LRT company. Include the company and bus no. of the relevant services.
- 10.Find the routes involving two buses that can go from Craiglockhart to Lochend.Show the bus no. and company for the first bus, the name of the stop for the transfer, and the bus no. and company for the second bus.
8 Using Null
1.List the teachers who have NULL for their department.
列出學系department是NULL值的老師。
select name from teacher where dept is null;
2.Note the INNER JOIN misses the teachers with no department and the departments with no teacher.
注意INNER JOIN 不理會沒有學系的老師及沒有老師的學系。
select teacher.name,dept.name
from teacher inner join dept
on teacher.dept=dept.id
where teacher.name is not null and dept.name is not null
3.Use a different JOIN so that all teachers are listed.
使用不同的JOIN(外連接),來列出全部老師。
select teacher.name,dept.name
from teacher left join dept
on teacher.dept=dept.id;
4.Use a different JOIN so that all departments are listed.
使用不同的JOIN(外連接),來列出全部學系。
select teacher.name,dept.name
from teacher right join dept
on teacher.dept=dept.id;
5.Use COALESCE to print the mobile number. Use the number ‘07986 444 2266’ if there is no number given. Show teacher name and mobile number or ‘07986 444 2266’
使用 COALESCE 打印手机号码。如没有编号,请使用编号「079864442266」。显示教师姓名及手机号码或’079864442266’
select name,coalesce(mobile,'07986 444 2266')
from teacher;
6.Use the COALESCE function and a LEFT JOIN to print the teacher name and department name. Use the string ‘None’ where there is no department.
使用 COALESCE 函数和一个 LEFT JOIN 打印教师姓名和系名。在没有部门的地方使用字符串“无”。
select teacher.name,coalesce(dept.name,'None')
from teacher left join dept
on teacher.dept=dept.id;
小结:
COALESCE ( expression,value1,value2……,valuen) ;
COALESCE()函数的第一个参数expression为待检测的表达式,而其后的参数个数不定。
COALESCE()函数将会返回包括expression在内的所有参数中的第一个非空表达式。
如果expression不为空值则返回expression;
否则判断value1是否是空值,如果value1不为空值则返回value1;
否则判断value2是否是空值,如果value2不为空值则返回value3;
……以此类推。
详见:
mysql的COALESCE函数、NULLIF函数、IFNULL函数
7.Use COUNT to show the number of teachers and the number of mobile phones.
使用COUNT來數算老師和流動電話數目。
select count(name),count(mobile) from teacher;
小结:
COUNT(1):统计不为NULL 的记录。
COUNT(*):统计所有的记录(包括NULL)。
COUNT(字段):统计该"字段"不为NULL 的记录。
1.如果这个字段是定义为not null的话,一行行地从记录里面读出这个字段,判断不能为null,按行累加。
2.如果这个字段定义允许为null的话,判断到有可能是null,还要把值取出来在判断一下,不是null才累加。
COUNT(DISTINCT 字段):统计该"字段"去重且不为NULL 的记录。
详见:
MySql统计函数COUNT详解
8.使用COUNT 和 GROUP BY dept.name來顯示每一學系的老師數目。 使用 RIGHT JOIN 以確保工程系Engineering 是在當中。
select dept.name,count(teacher.name)
from
teacher right join dept
on teacher.dept=dept.id
group by dept.name;
详见:
MySQL–Group by分组与count计数(进阶)
9.Use CASE to show the name of each teacher followed by ‘Sci’ if the teacher is in dept 1 or 2 and ‘Art’ otherwise.
如果教师的部门是1或2,则使用 CASE 显示每位教师的姓名,后面跟着“ Sci”,否则使用“ Art”。
select name,
case when dept in (1,2) then 'Sci' else 'Art' end
from teacher;
10.Use CASE to show the name of each teacher followed by ‘Sci’ if the teacher is in dept 1 or 2, show ‘Art’ if the teacher’s dept is 3 and ‘None’ otherwise.
使用 CASE 显示每个教师的名字,如果教师在专业1或专业2后面跟着“ Sci”,如果教师专业3则显示“ Art”,否则显示“ Nothing”。
select name,
case when dept in (1,2) then 'Sci'
when dept = 3 then 'Art'
else 'None' end
from teacher;
8+ Numeric Examples
下图为nss表的表结构
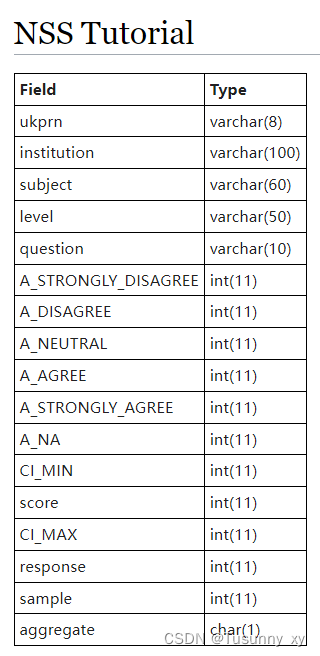
1.The example shows the number who responded for:
question 1
at ‘Edinburgh Napier University’
studying ‘(8) Computer Science’
Show the the percentage who STRONGLY AGREE
该示例显示响应的人数:
· 问题一
· 在“爱丁堡龙比亚大学”
· 学习《(8)计算机科学》
显示强烈同意的百分比
select A_STRONGLY_AGREE
from nss
where question = 'Q01'
and institution='Edinburgh Napier University'
and subject='(8) Computer Science';
2.Show the institution and subject where the score is at least 100 for question 15.
显示问题 15 的分数至少为 100 的机构和主题。
select institution, subject
from nss
where score >= 100 and question = 'Q15';
3.Show the institution and score where the score for ‘(8) Computer Science’ is less than 50 for question ‘Q15’.
显示问题’Q15’'(8)计算机科学’分数低于50分的机构和分数
select institution, score
from nss
where question = 'Q15'
and subject = '(8) Computer Science'
and score < 50;
4.Show the subject and total number of students who responded to question 22 for each of the subjects ‘(8) Computer Science’ and ‘(H) Creative Arts and Design’.
显示科目和回答科目“(8) 计算机科学”和科目“(H) 创意艺术与设计” 22 问题的学生总数。
select subject, sum(response) as number
from nss
where question = 'Q22'
and subject in ('(8) Computer Science',
'(H) Creative Arts and Design')
group by subject;
5.Show the subject and total number of students who A_STRONGLY_AGREE to question 22 for each of the subjects ‘(8) Computer Science’ and ‘(H) Creative Arts and Design’.
显示科目和回答科目“(8) 计算机科学”和科目“(H) 创意艺术与设计” 22 问题并表示同意问题 22的学生总数。
select subject, sum(response * A_STRONGLY_AGREE / 100) number
from nss
where question = 'Q22'
and subject in ('(8) Computer Science',
'(H) Creative Arts and Design')
group by subject;
注意:
因为A_STRONGLY_AGREE 是整数形式的百分比,不是小数形式的百分比,所以要除以100
6.Show the percentage of students who A_STRONGLY_AGREE to question 22 for the subject ‘(8) Computer Science’ show the same figure for the subject ‘(H) Creative Arts and Design’.Use the ROUND function to show the percentage without decimal places.
显示 A_STRONGLY_AGREE 主题“(8) Computer Science”的问题 22 显示主题“(H) Creative Arts and Design”相同数字的学生百分比。使用 ROUND 函数显示不带小数位的百分比。
-- 正确写法,在除数sum(response * A_STRONGLY_AGREE / 100)的基础上直接乘以100,直接在除法这一步就得到计算出来的百分比。
-- round可以不加
select subject,
sum(response * A_STRONGLY_AGREE / 100)*100 / sum(response) as percentage
from nss
where question = 'Q22'
and subject in ('(8) Computer Science',
'(H) Creative Arts and Design')
group by subject;
-- round也可以加
select subject,
round(sum(response * A_STRONGLY_AGREE / 100)*100 / sum(response), 0)as percentage
from nss
where question = 'Q22'
and subject in ('(8) Computer Science',
'(H) Creative Arts and Design')
group by subject;
-- 错误写法
select subject,
round(sum(response * A_STRONGLY_AGREE / 100) / sum(response), 2) * 100 as percentage
from nss
where question = 'Q22'
and subject in ('(8) Computer Science',
'(H) Creative Arts and Design')
group by subject;
7.Show the average scores for question ‘Q22’ for each institution that include ‘Manchester’ in the name.
The column score is a percentage - you must use the method outlined above to multiply the percentage by the response and divide by the total response. Give your answer rounded to the nearest whole number.
显示名称中包含“曼彻斯特”的每个机构的问题“Q22”的平均分数。
列分数是一个百分比 - 您必须使用上述方法将百分比乘以响应并除以总响应。 将您的答案四舍五入到最接近的整数。
select institution,
round(sum(score * response) / sum(response),0) as score
from nss
where question = 'Q22' and (institution like '%Manchester%')
group by institution
order by institution;
8.Show the institution, the total sample size and the number of computing students for institutions in Manchester for ‘Q01’.
显示“Q01”曼彻斯特机构的机构、总样本量和计算学生人数。
select institution,
sum(sample) sample,
sum(case when subject = '(8) Computer Science'
then sample
else 0 end) comp
from nss
where question = 'Q01'
and (institution like '%Manchester%')
group by institution;
9- Window function
1.Show the lastName, party and votes for the constituency ‘S14000024’ in 2017.
显示 2017 年选区“S14000024”的姓氏、政党和选票。
select lastName, party, votes
from ge
where constituency = 'S14000024' AND yr = 2017
order by votes DESC;
2.You can use the RANK function to see the order of the candidates. If you RANK using (ORDER BY votes DESC) then the candidate with the most votes has rank 1.
Show the party and RANK for constituency S14000024 in 2017. List the output by party.
您可以使用 RANK 函数查看候选人的顺序。 如果您使用 (ORDER BY votes DESC) 进行排名,那么得票最多的候选人排在第 1 位。
显示 2017 年选区 S14000024 的政党和排名。按政党列出产出。
select party, votes,
rank() over(order by votes desc) as posn
from ge
where constituency = 'S14000024' and yr = 2017
order by party;
3.The 2015 election is a different PARTITION to the 2017 election. We only care about the order of votes for each year.
Use PARTITION to show the ranking of each party in S14000021 in each year. Include yr, party, votes and ranking (the party with the most votes is 1).
2015 年的选举与 2017 年的选举不同。 我们只关心每年的投票顺序。
用PARTITION显示每一年S14000021中各方的排名。 包括年份、政党、选票和排名(得票最多的政党是 1)。
select yr, party, votes,
rank() over(partition by yr
order by votes desc) as posn
from ge
where constituency = 'S14000021'
order by party, yr;
小结:
over()是分析函数(开窗函数),必须与聚合函数或排序函数一起使用。
聚合函数一般指:
sum(),max(),min,count(),avg()等常见函数。
排序函数一般指:rank(),dense_rank(),row_number(),ntile(n)等常见函数。
例如
--注意1:rank(),dense_rank(),row_number(),ntile(n)等排序函数必须与order by一起使用
rank() over(partition by 列名,order by 列名);
dense_rank() over(partition by 列名,order by 列名);
row_number() over(partition by 列名,order by 列名);
ntile(n) over(partition by 列名,order by 列名);
--注意2:若是没有指定,就至关于对指定分区集合内的数据进行总体sum操作。
sum() over(partition by 列名,order by 列名)
over(partition by 列名,order by 列名)
--注意3:使用聚合函数时,使用order by则可以看到数据聚合的过程(例如累加,累减,逐步计数,逐步求平均)。
sum() over(partition by 列名)
是分组后求和,出来的结果每一行都是分组后的累加和;
sum() over(partition by 列名,order by 列名)
是分组后累加求和,是可以根据order by的排序看到累加的过程的。
;
四个函数的特点:
rank() :可有重复值。对于相等的两个数字,排序序号一致,但是总数会减少;
| 数值 | 排序序号 |
|---|---|
| 10 | 1 |
| 10 | 1 |
| 20 | 3 |
dense_rank():可有重复值。对于相等的两个数字,排序序号一致;
| 数值 | 排序序号 |
|---|---|
| 10 | 1 |
| 10 | 1 |
| 20 | 2 |
row_number():不会有重复的排序数值。对于相等的两个数字,排序序号不一致;
| 数值 | 排序序号 |
|---|---|
| 10 | 1 |
| 10 | 2 |
| 20 | 3 |
ntile():平均分组,ntile(n),n是一个字面正整数。桶号的范围是1到n。函数会将数据分为n组,自动进行分组 (每组数量大致相等,若无法均分为n组,则每组的记录数不能大于它上一组的记录数),每组将会分配同一个序号(组号为1-n);
例如:
ntile(2) over(partition by 列名,order by 列名);
| 数值 | 排序序号 |
|---|---|
| 10 | 1 |
| 20 | 1 |
| 30 | 2 |
| 40 | 2 |
详见:
SQL中的开窗函数over()
(排序函数)-row_number/rank/dense_rank/ntile
ROW_NUMBER,RANK,DENSE_RANK,NTILE
4.Edinburgh constituencies are numbered S14000021 to S14000026.Use PARTITION BY constituency to show the ranking of each party in Edinburgh in 2017. Order your results so the winners are shown first, then ordered by constituency.
爱丁堡选区编号为 S14000021 至 S14000026。
使用 PARTITION BY constituency 显示 2017 年爱丁堡各政党的排名。对结果进行排序,以便首先显示获胜者,然后按选区排序。
select constituency, party, votes,
rank() over(partition by constituency
order by votes desc) as posn
from ge
where constituency between 'S14000021' and 'S14000026'
and yr = 2017
order by posn, constituency;
5.You can use SELECT within SELECT to pick out only the winners in Edinburgh.Show the parties that won for each Edinburgh constituency in 2017.
您可以在 SELECT 中使用 SELECT 来仅选出爱丁堡的获胜者。显示 2017 年为每个爱丁堡选区获胜的政党。
select a.constituency, a.party
from
(select constituency, party,
rank() over(partition by constituency
order by votes desc) as nums
from ge
where constituency between 'S14000021' and 'S14000026' and yr = 2017) as a
where a.nums= 1;
6.You can use COUNT and GROUP BY to see how each party did in Scotland. Scottish constituencies start with ‘S’.Show how many seats for each party in Scotland in 2017.
您可以使用 COUNT 和 GROUP BY 查看每一方在苏格兰的表现。 苏格兰选区以“S”开头。显示 2017 年苏格兰各党派的席位数量。
select a.party, count(*) seats
from
(select party,
rank() over(partition by constituency
order by votes desc) as nums
from ge
where constituency like 'S%' and yr = 2017) as a
where a.nums = 1
group by a.party;
9+ COVID 19
1.The example uses a WHERE clause to show the cases in ‘Italy’ in March 2020.Modify the query to show data from Spain
该示例使用 WHERE 子句显示 2020 年 3 月“意大利”的案例。
修改查询以显示来自西班牙的数据。
select name, day(whn), confirmed, deaths, recovered
from covid
where name = 'Spain'
and month(whn) = 3
order by whn;
SQL day() 、month()、year()的应用:
1、day(date_expression)
返回date_expression中的日期值
2、month(date_expression)
返回date_expression中的月份值
3、year(date_expression)
返回date_expression中的年份值
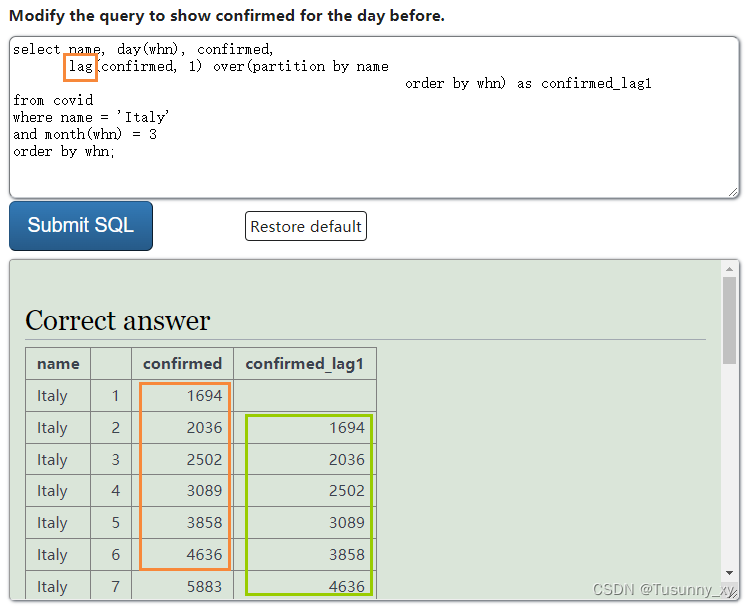
2.The LAG function is used to show data from the preceding row or the table. When lining up rows the data is partitioned by country name and ordered by the data whn. That means that only data from Italy is considered.Modify the query to show confirmed for the day before.
LAG 函数用于显示前一行或表格中的数据。 排列行时,数据按国家名称分区并按数据 whn 排序。 这意味着只考虑来自意大利的数据。
修改查询以显示前一天已确认。
select name, day(whn), confirmed,
lag(confirmed, 1) over(partition by name
order by whn) as confirmed_lag1
from covid
where name = 'Italy'
and month(whn) = 3
order by whn;
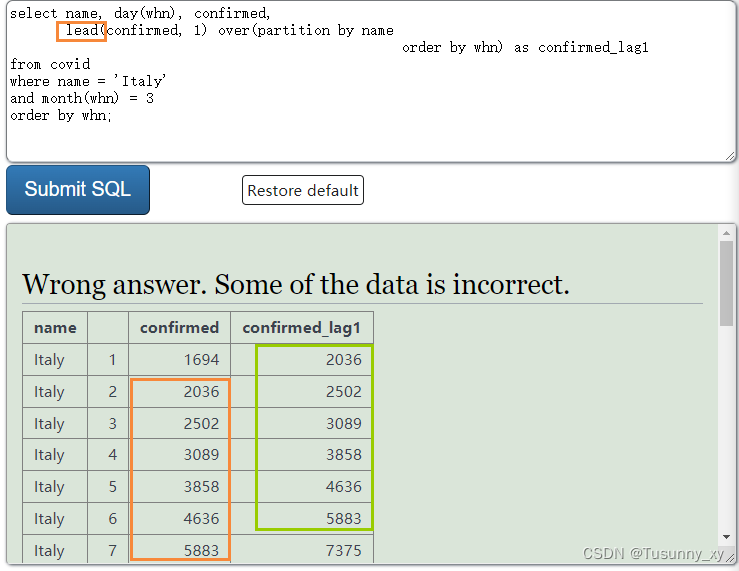
lag ,lead 分别是
查询当前行直观上总体下移n行
查询当前行直观上总体上移n行
lag 和lead 有三个参数,
第一个参数是待查询的列名,
第二个参数是偏移的行数,
第三个参数是 超出窗口边界时的默认值
lag(查询当前行直观上总体下移n行)
lead (查询当前行直观上总体上移n行)
详见:
Sql窗口分析函数【lead、lag详解】
3.The number of confirmed case is cumulative - but we can use LAG to recover the number of new cases reported for each day.Show the number of new cases for each day, for Italy, for March.
确诊病例数是累积的 - 但我们可以使用 LAG 恢复每天报告的新病例数。显示意大利 3 月份每天的新病例数。
select name, day(whn),
confirmed - lag(confirmed, 1) over(partition by name order by whn) as newcases
from covid
where name = 'Italy'
and month(whn) = 3
order by whn;
4.The data gathered are necessarily estimates and are inaccurate. However by taking a longer time span we can mitigate some of the effects.You can filter the data to view only Monday’s figures WHERE WEEKDAY(whn) = 0.Show the number of new cases in Italy for each week - show Monday only.
收集到的数据必然是估计值,并不准确。 然而,通过延长时间跨度,我们可以减轻一些影响。您可以过滤数据以仅查看星期一的数据,其中 WEEKDAY(whn) = 0。显示意大利每周的新病例数 - 仅显示星期一。
--第一种写法:
select name, date_format(whn,'%Y-%M-%D'),
confirmed - lag(confirmed, 1)
over (partition by name order by whn) newcases
from covid
where name = 'Italy'
and weekday(whn) = 0
order by whn;
--第二种写法:
select name, date_format(whn,'%Y-%M-%D'),
confirmed - lag(confirmed, 1)
over (partition by name order by whn) newcases
from covid
where name = 'Italy'
and dayofweek(whn) = 2
order by whn;
1:date_format()
date_format()函数用于以不同的格式显示日期/时间数据,函数接受两个参数:
date:待格式化的日期值列名
format:是由预定义的说明符组成的格式字符串,每个说明符前面都有一个百分比字符(%)
注意:
date_format()里面的格式不能写成‘YYYY-MM-DD’,格式应该是’%Y-%M-%D’这种。
详见:
DATE_FORMAT() 函数
2:dayofweek() 和 weekday()
在mysql中,我们可以用dayofweek() 和 weekday()函数获取指定日期的星期。区别在于
dayofweek 获取的星期索引是以1开始,并且这些索引值对应于ODBC标准。
具体的星期索引(1=星期天,2=星期一, ……7=星期六);
而weekday获取的星期索引是以0开始,
具体的星期索引(0=星期一,1=星期二, ……6= 星期天)
'2023-03-06’是星期一
select dayofweek(‘2023-03-06’);
输出 2
select weekday(‘2023-03-06’);
输出 0
详见:
DAYOFWEEK 和 WEEKDAY函数
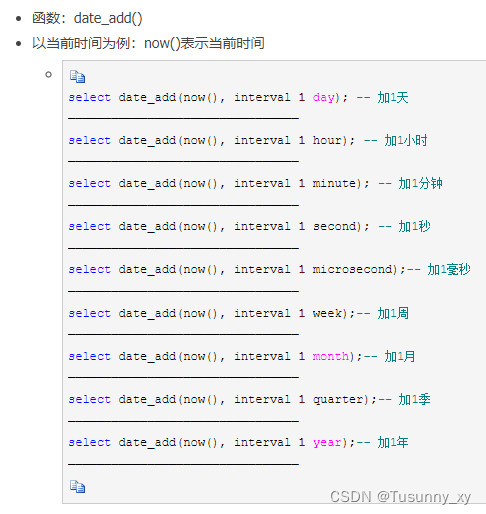
5.You can JOIN a table using DATE arithmetic. This will give different results if data is missing.Show the number of new cases in Italy for each week - show Monday only.In the sample query we JOIN this week tw with last week lw using the DATE_ADD function.
您可以使用 DATE 算术连接表。 如果数据缺失,这将给出不同的结果。显示意大利每周的新病例数 - 仅显示星期一。在示例查询中,我们使用 DATE_ADD 函数加入本周 tw 和上周 lw。
select tw.name, date_format(tw.whn,'%Y-%M-%D'),
(tw.confirmed - lw.confirmed) as newcases
from covid tw left join covid lw
on date_add(lw.whn, interval 1 week) = tw.whn
and tw.name=lw.name
where tw.name = 'Italy' and weekday(tw.whn) = 0
order by tw.whn;
6.The query shown shows the number of confirmed cases together with the world ranking for cases.United States has the highest number, Spain is number 2…Notice that while Spain has the second highest confirmed cases, Italy has the second highest number of deaths due to the virus.Include the ranking for the number of deaths in the table.
显示的查询显示了确诊病例数以及世界病例排名。美国的病例数最高,西班牙排名第二…请注意,虽然西班牙的确诊病例数第二多,但意大利的死亡人数第二多 由于病毒。包括表格中死亡人数的排名。
select name,
confirmed,
rank() over(order by confirmed desc) rank_confirmed,
deaths,
rank() over(order by deaths desc) rank_deaths
from covid
where whn = '2020-04-20'
order by confirmed desc;
7.The query shown includes a JOIN t the world table so we can access the total population of each country and calculate infection rates (in cases per 100,000).Show the infect rate ranking for each country. Only include countries with a population of at least 10 million.
显示的查询包括一个 连接的world 表,因此我们可以访问每个国家的总人口并计算感染率(以每 100,000 例为单位)。显示每个国家的感染率排名。 仅包括人口至少为 1000 万的国家。
select world.name,
round(100000*confirmed/population,0) as infection_rates,
rank() over(order by confirmed/population) as rank_infection_rates
from covid join world
on covid.name = world.name
where whn = '2020-04-20' and population > 10000000
order by population desc;
8.For each country that has had at last 1000 new cases in a single day, show the date of the peak number of new cases.
对于单日新增病例数达到 1000 例的每个国家/地区,显示新增病例数达到峰值的日期。
??
结果和答案一样但错误
WITH temp1 AS (
SELECT *, (confirmed - LAG(confirmed, 1) OVER (PARTITION BY name ORDER BY whn)) day_count
FROM covid
),
temp2 AS (
SELECT name, MAX(day_count) peak_cases
FROM temp1
GROUP BY name
HAVING peak_cases > 1000
)
SELECT temp2.name, DATE_FORMAT(whn, '%Y-%m-%d') date_, peak_cases
FROM temp2 LEFT JOIN temp1 ON (temp2.name = temp1.name) AND (temp2.peak_cases = temp1.day_count)
ORDER BY date
https://www.codenong.com/cs107031202/
9 Self join
1.How many stops are in the database.
在数据库中查询有多少停靠点。
select count(*) from stops;
2.Find the id value for the stop ‘Craiglockhart’
查找停靠点“Craiglockhart”的 id 值
select id from stops where name = 'Craiglockhart'
3.Give the id and the name for the stops on the ‘4’ ‘LRT’ service. Some of the data is incorrect.
提供“4”“LRT”服务的站点 ID 和名称。 部分数据不正确。
select id, name
from stops left join route
on id = stop
where num = 4 and company = 'LRT';
4.The query shown gives the number of routes that visit either London Road (149) or Craiglockhart (53). Run the query and notice the two services that link these stops have a count of 2. Add a HAVING clause to restrict the output to these two routes.
显示的查询给出了访问 London Road (149) 或 Craiglockhart (53) 的路线数量。 运行查询并注意链接这些站点的两个服务的计数为 2。添加一个 HAVING 子句以将输出限制为这两个路由。
select company, num, count(*)
from route
where stop=149 or stop=53
group by company, num
having count(*) = 2;
5.Execute the self join shown and observe that b.stop gives all the places you can get to from Craiglockhart, without changing routes. Change the query so that it shows the services from Craiglockhart to London Road.
执行所示的自连接并观察 b.stop 给出了您可以从 Craiglockhart 到达的所有地点,而无需更改路线。 更改查询,使其显示从 Craiglockhart 到 London Road 的服务。
select a.company, a.num, a.stop, b.stop
from route a left join route b
on (a.company = b.company and a.num = b.num)
where a.stop = 53 and b.stop = 149;
6.The query shown is similar to the previous one, however by joining two copies of the stops table we can refer to stops by name rather than by number. Change the query so that the services between ‘Craiglockhart’ and ‘London Road’ are shown. If you are tired of these places try ‘Fairmilehead’ against ‘Tollcross’.
显示的查询与前一个查询类似,但是通过连接停靠点表的两个副本,我们可以按名称而不是按编号来引用停靠点。 更改查询,以便显示“Craiglockhart”和“London Road”之间的服务。 如果您厌倦了这些地方,请试试“Fairmilehead”而不是“Tollcross”。
select a.company, a.num, stopa.name, stopb.name
from route a join route b
on (a.company = b.company and a.num = b.num)
join stops stopa
on a.stop = stopa.id
join stops stopb
on b.stop = stopb.id
where stopa.name = 'Craiglockhart' and stopb.name = 'London Road';
7.Give a list of all the services which connect stops 115 and 137 (‘Haymarket’ and ‘Leith’).
列出所有连接 115 号和 137 号站(‘Haymarket’ 和 ‘Leith’)的服务。
select distinct a.company, a.num
from route a join route b on
(a.company = b.company and a.num = b.num)
where a.stop = 115 and b.stop = 137;
8.Give a list of the services which connect the stops ‘Craiglockhart’ and ‘Tollcross’.
给出连接“Craiglockhart”和“Tollcross”站点的服务列表。
select distinct a.company, a.num
from route a join route b
on (a.company = b.company and a.num = b.num)
join stops stopa
on a.stop = stopa.id
join stops stopb
on b.stop = stopb.id
where stopa.name = 'Craiglockhart' and stopb.name = 'Tollcross';
9.Give a distinct list of the stops which may be reached from ‘Craiglockhart’ by taking one bus, including ‘Craiglockhart’ itself, offered by the LRT company. Include the company and bus no. of the relevant services.
列出从“Craiglockhart”搭乘一辆公共汽车可以到达的站点的明确列表,包括轻轨公司提供的“Craiglockhart”本身。 包括公司和巴士号码。 的相关服务。
select distinct stopb.name, a.company, a.num
from route a join route b
on (a.company = b.company and a.num = b.num)
left join stops stopa
on a.stop = stopa.id
left join stops stopb
on b.stop = stopb.id
where stopa.name = 'Craiglockhart' and a.company = 'LRT';
10.Find the routes involving two buses that can go from Craiglockhart to Lochend.Show the bus no. and company for the first bus, the name of the stop for the transfer, and the bus no. and company for the second bus.
查找涉及可以从 Craiglockhart 到 Lochend 的两辆公共汽车的路线。显示公共汽车号。 和第一辆公共汽车的公司,换乘站的名称,以及公共汽车号。 和公司的第二辆公共汽车。
select routea.num,
routea.company,
routea.name,
routeb.num,
routeb.company
from
(select a.company, a.num, stopb.name, b.stop
from route a inner join route b
on (a.company = b.company
and a.num = b.num
and a.stop != b.stop)
join stops stopa on (a.stop = stopa.id)
join stops stopb on (b.stop = stopb.id)
where stopa.name='Craiglockhart') as routea
inner join
(select c.company, c.num, stopc.name, c.stop
from route c inner join route d
on (c.company = d.company
and c.num = d.num
and c.stop != d.stop)
join stops stopc on(c.stop = stopc.id)
join stops stopd on (d.stop = stopd.id)
where stopd.name = 'Lochend') AS routeb
on routea.stop=routeb.stop
order by routea.num, routea.name, routeb.num;















 5519
5519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









