







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
残差提升决策树
提升方法实际是采用加法模型(基模型的线性组合)与前向分步算法来将弱学习器变为强学习器。而其中以决策树为基函数的提升方法就是提升树。
集成学习本身可以完成分类与回归两种任务。与adaboost分类相比,若仍然使用决策树作为基模型,则必须对统计学习三要素(模型,策略,算法)中的模型与策略都进行改变。adaboost的基模型为分类树,策略即损失函数为指数损失函数,算法为前向分布算法,而残差提升决策树的基模型为回归树,策略即损失函数为平方误差损失函数,算法为前向分布算法。
算法的具体流程如下:

梯度提升决策树
对于更为一般的情况,若不特别指定策略(即损失函数),则可使用损失函数的负梯度在当前模型的值作为回归问题提升树算法中的残差近似值,进而拟合回归树。并且,与其说负梯度作为残差的近似值,不如说残差是负梯度的一种特例,也就是说adaboost与残差提升决策树是梯度提升决策树的特例。

from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
x, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
x_train, x_test = x[:200], x[200:]
y_train, y_test = y[:200], y[200:]
est = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1,
max_depth=1, random_state=0, loss='ls').fit(x_train, y_train)
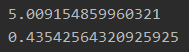
print(mean_squared_error(y_test, est.predict(x_test)))
x, y = make_regression(random_state=0)
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0)
reg = GradientBoostingRegressor(random_state=0)
reg.fit(x_train, y_train)
print(reg.score(x_test, y_test))















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









