







Absrtact
- 挑战:跨场景人群计数(目标场景无标注);
- 提出DCNN,由人群密度和人数交替训练;
- 提出data-driven方法微调CNN模型以适应目标场景;
- 提出包含108个场景(标注200000人头)的数据集;
1. Introduction
难点:严重遮挡、场景透视形变、不同的人群分布。
利用低水平特征和回归的方法:针对特定场景
我们需要克服以下困难:1)提出高级特征;2)不同场景有不同的透视形变、人群分布、光照情况;3)前景分割的准确性;4)没有合适的数据集。
解决方案:跨场景CNN——固定数据训练DCNN后,利用数据自驱动方法微调,就是在训练集中找出相似场景进行微调。

我们跨场景人群密度估计和计数框架有以下优点:
1.DCNN模型是通过两个学习目标——人群密度图和人数交替训练的。
2.目标场景不需要标注。
3.不依赖前景分割的效果,因为我们只考虑外观特征。不管人群有没有移动,CNN能够得到人群纹理特征。
4.新数据集。
2. Related work
1、全局回归的人群计数:基于检测器或者轨迹集聚。忽略空间信息
2、密度估计的人群计数:像素级的密度图回归,Fiaschi et al. [7]利用随机森林回归密度,优点是能够知道图片中任一个区域的物体数量。不能适用于跨场景。
3、深度学习:person reidentification [13], pedestrian detection [30, 31, 20], tracking [28], crowd behavior analysis [9] and crowd segmentation [10]。
4、场景标记的数据自驱动方法:将训练标签迁移到测试标签中(通过检索相似的训练图片,match them with the test image)。Liu et al. [15]提出密集形变场。我们不是直接将标签迁移到目标场景中,而是用训练场景微调已经训练好的CNN模型。
Method
3.1. Normalized crowd density map for training
CNN模型的主要任务目标就是学习映射关系:F : X→D,X是低级特征,D是人群密度图。假设行人的位置是标注好的,密度图就根据行人的空间位置、身体形状、透视形变产生。随机选取的patch作为训练样本,patch对应的密度图就是CNN模型的真值。选定的训练样本的总人数就通过密度图的积分求出。
Many works followed [12],定义了密度图的回归真值为物体中心卷积核的和。这种密度图适用于圆形的物体,例如细胞和细菌。然而,当不是鸟瞰图时,这种假设不再适合行人。行人图片有三个直观特征:1)由于透视形变行人有不同大小;2)行人形状是椭圆;3)由于遮挡严重,头肩部是判别行人与背景的主要依据。考虑这些因素,人群密度图是视角归一化的几种分布的结合。
视角归一化是很有必要的。受【4】启发,随机选取几个行人,从头到脚做好标注。假设行人是175cm,透视图M(图2a)就能通过线性回归计算出来。透视图M(p)中的像素的数目表示实际的一米。当我们获得透视图和ROI区域中行人头部中心Ph后,密度图如下:
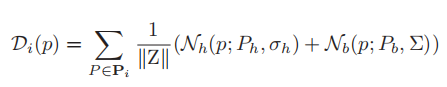
人群密度分布核包括两部
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3746
3746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









