







引言
在自然语言处理领域,预训练语言模型(PLMs)扮演着至关重要的角色,它可以根据任务需求,可迁移至各种下游任务中。然而,PLMs在适应新语言时面临挑战,尤其是在数据和计算资源受限的情况下。本文提出了一种通过「主动遗忘机制」,可在预训练期间增强PLMs语言可塑性的方法。实验结果表明,采用该机制的预训练模型在低数据环境下表现出更快的收敛速度,并且相比标准PLMs准确率高出21.2%。

https://arxiv.org/pdf/2307.01163.pdf
背景介绍
预训练语言模型(Pretrained Language Models, PLMs)在自然语言处理(Natural Language Processing, NLP)领域的应用上存在一定的局限性。具体来说,预训练语言模型的核心是通过汲取大型数据集来获取知识,并在预训练期间将这些知识存储在参数中,然后通过微调(fine-tuning)或提示(prompting)将这些知识应用于各种下游任务,如语义分析、问答等。
尽管 PLM 取得了成功,但仍然存在许多缺点。特别是「在适应新语言」时仍面临挑战,它需要大量数据和计算来对其进行预训练,并且重新训练一个新的 PLM 来适应每一次语言空间的转变付出的代价可谓是非常昂贵。在此情况下限制了它们的普遍适用性。
在实际应用过程中,虽然模型遗忘被认为是一些负面的事情,例如模型的灾难性以往,但凡事都有两面性。最近的研究表明对于人工神经网络来说,遗忘也可以增加模型的“可塑性”。例如可以提高模型在未见数据上的泛化能力、在低数据状态下的学习能力,亦或者有利于模型偏见的消除。为此本文作者拟探索利用模型的遗忘机制来改进预训练模型。
众所周知,当前模型很难在没有干预的情况下进行跨语言泛化,尤其是对于缺乏数据集的语言。本文将重点放在PLM的输入层,即Token嵌入层。具体来说,作者引入了一种主动遗忘机制,该机制定期重置令牌嵌入,同时在整个预训练过程中保持所有参数不变,以创建能够快速适应新语言的PLMs。
重置预训练模型
「重置预训练即重新学习新语言的嵌入层,同时保持所有其他参数不变」。基本假设是,Token嵌入层和Transformer主体存在责任划分,即Token嵌入层处理特定于语言的词汇含义,而后者Transformer主体主要处理高级推理。因此,为新语言重置英语PLM可以归结为分别使用新语言中的未标记数据调整Token嵌入层,并用英语任务数据调整Transformer主体。如下图所示,大概可以分为4个步骤
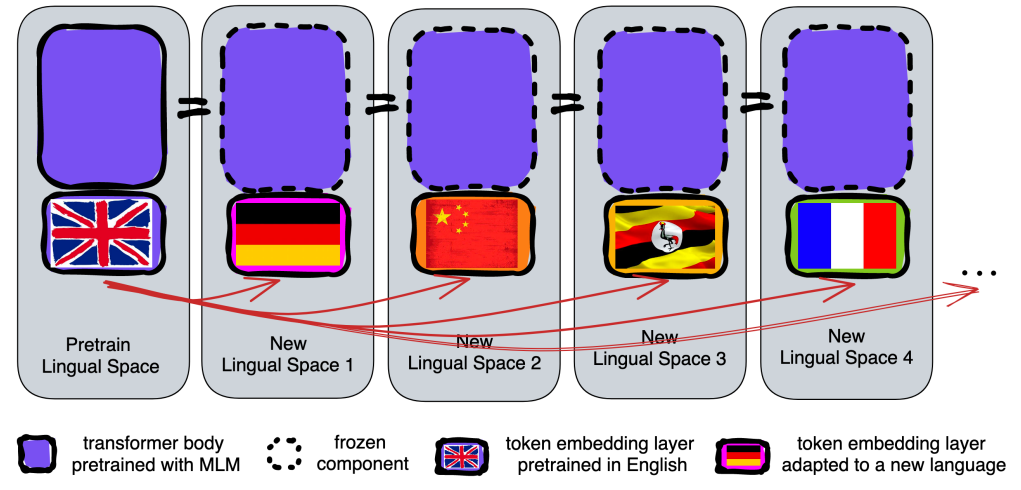
「预训练」 选择一个基于Transformer(如RoBERTa)的模型,并在一个主要语言(如英语)的大型数据集上进行预训练。预训练的目标是使模型学习到丰富的语言知识,并将其存储在模型参数中。
「语言适应」 利用新语言的未标记数据对模型的词嵌入层进行微调,同时保持其他所有参数(即Transformer主体)冻结。这一步骤的目的是让模型学习新语言的词汇表示,而不影响模型已经学到的通用知识。
「任务适配」 使用下游任务的数据(仍使用预训练语言的数据)对Transformer主体进行微调。这一步骤旨在优化模型在特定任务上的表现,同时保持对新语言适应的能力。
「组装」 将适应后的新语言词嵌入层和优化过的Transformer主体结合起来,形成一个可以在新语言上执行任务的最终模型。
主动遗忘机制
在预训练阶段,研究者引入了一种主动遗忘机制,即每隔K次更新重置词嵌入层。这种机制迫使模型在预训练过程中多次学习并遗忘词嵌入,从而培养模型快速适应新嵌入表示的能力。这种遗忘过程类似于元学习中的“遗忘”策略,旨在提高模型的泛化能力和适应性。具体如下图所示:
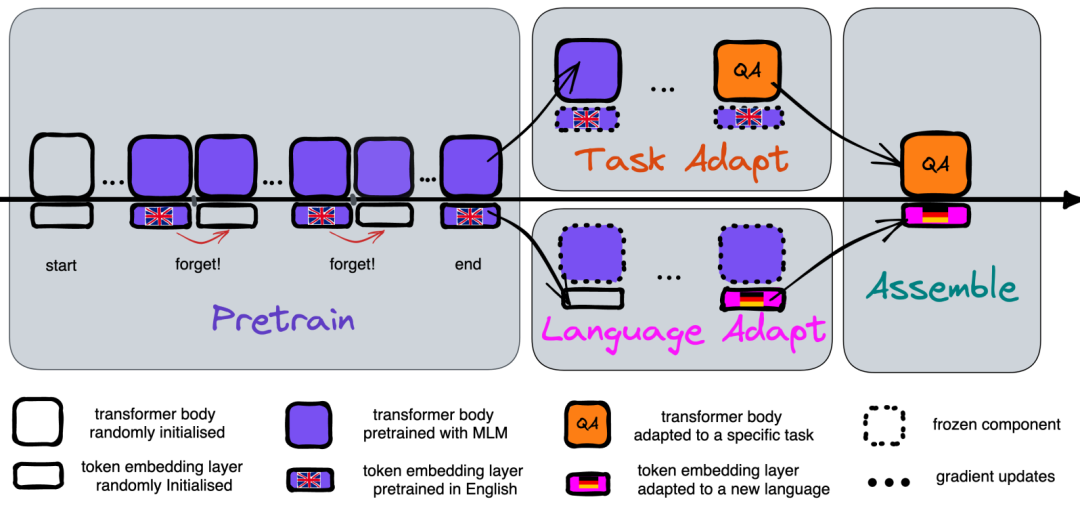
这种方法类似于元学习(meta-learning)中的“遗忘”策略,目的是让模型学会如何在有限的数据和更新次数内适应新的嵌入表示。反观传统的PLMs在适应新语言时,可能会依赖于特定的嵌入初始化(即“捷径”),这在数据有限的情况下可能会导致性能下降。通过在预训练期间引入遗忘,模型被迫学会不依赖这些捷径,而是在Transformer主体中编码更通用、更高层次的推理能力。这样的模型在适应新语言时,能够更快地学习新的词嵌入,并且在整个适应过程中需要的数据更少。
实验结果
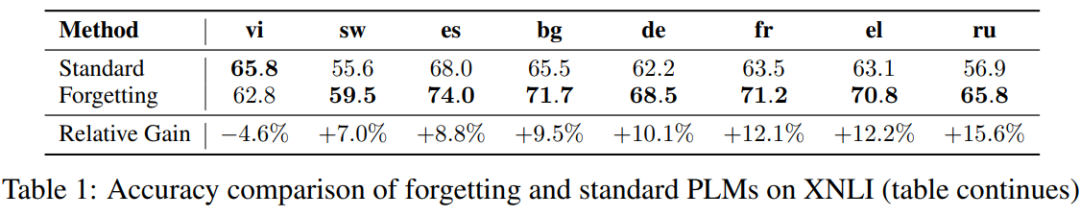
在推理方面,如下图所示,采用遗忘机制的预训练模型(PLMs)在XNLI任务上的平均准确率比要标准PLMs高出21.2%
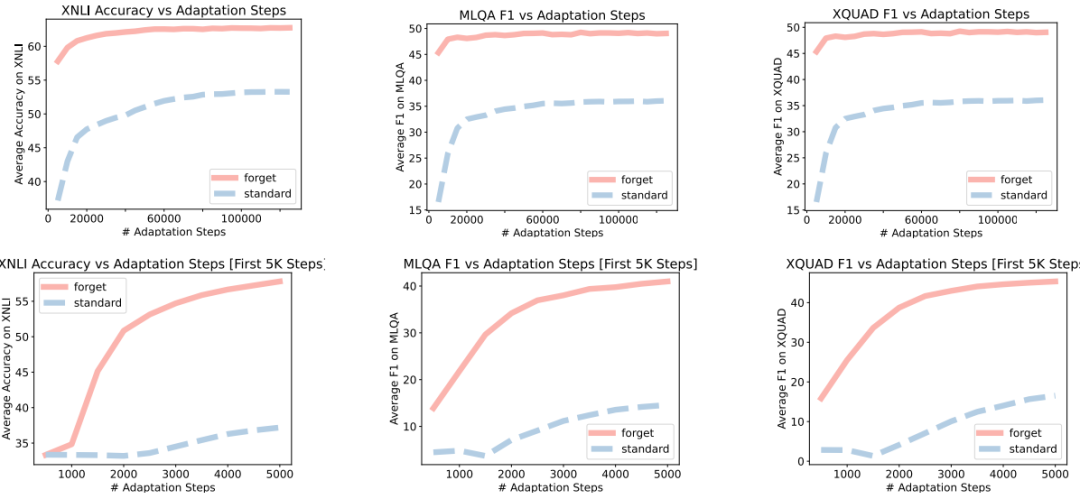
在跨语言QA方面,如下图所示,采用遗忘机制的PLMs的平均F1分数比标准PLMs高出33.8%

在收敛速度方面,采用遗忘机制的PLMs在语言适应阶段的收敛速度显著快于标准PLMs。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











