







大型语言模型(LLM)在文本摘要、问答和角色扮演对话等语言任务上表现出色,在数学推理等复杂问题上也具有应用潜力。
但目前提高 LLM 数学问题解决能力的方法,往往会导致其他方面能力的下降。例如RLHF的方法,虽然可以提高文本生成的质量,但却会忽略解决数学问题所需要的准确性和逻辑连贯性,而 SFT 微调,则可能降低大模型本身的语言多样性。
针对这一问题,我们提出了一种「Self-Critique」的迭代训练方法,通过自我反馈的机制,可以使 LLM 的语言能力和数学能力得到同步提升。
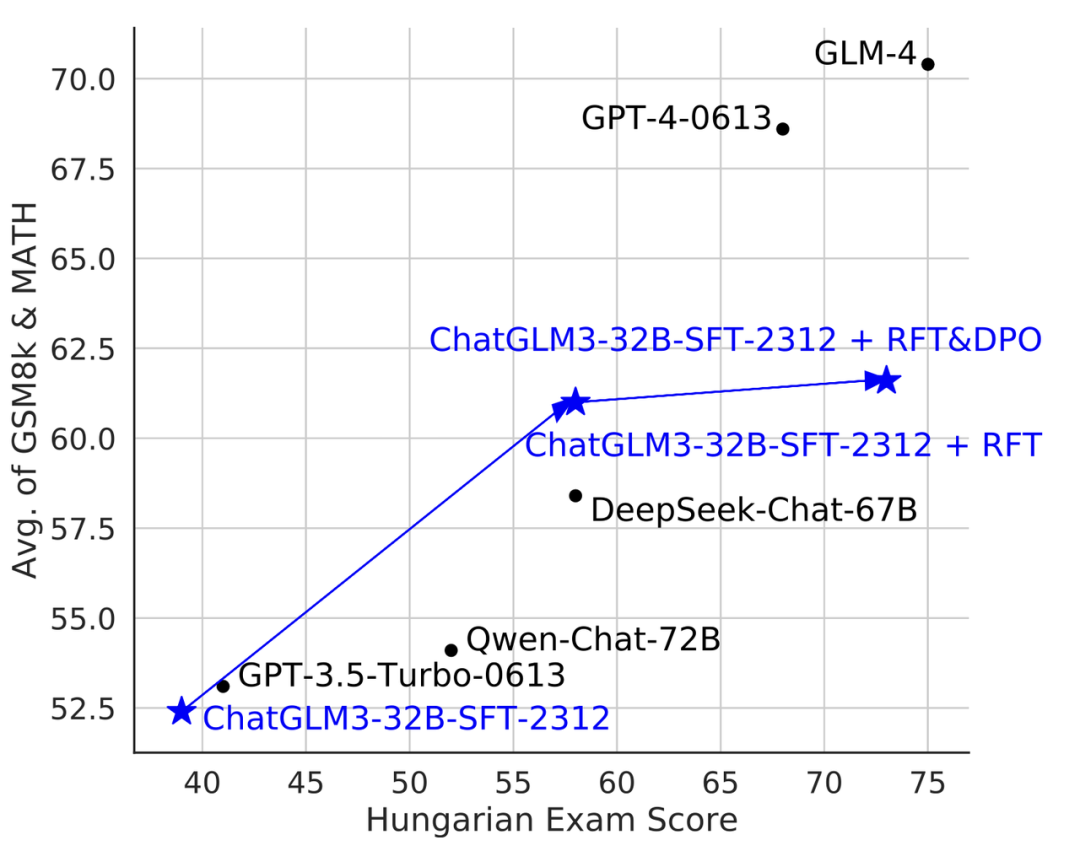
图:基于 Self-Critique 方法,ChatGLM3-32B的传统学术数据集数学能力(GSM8k)和分布外测试集匈牙利国家数学考试分数(Hungarian Exam Score)都得到了的提升。
此外,为了更加准确地评估 LLM 解决现实世界数学问题的能力,我们开发了 MathUserEval 评测基准。

项目地址:https://github.com/THUDM/ChatGLM-Math
论文地址:https://arxiv.org/pdf/2404.02893.pdf
Self-Critique 的整体流程
Self-Critique 有三个步骤:
Math-Critique

我们工作的第一部分是构建一个准确而稳健的评估模型。基于对大模型评估的启发,我们提出了 Math-Critique 的方法。Math-Critique 将根据问题和参考答案,对模型生成的数学响应进行评分,并给出评分的解释。
Math Critique 的模型可以定义为:
MathCritique(问题,参考答案,答案)-> (评分,解释评论)
在指令中,Math-Critique 会将响应结果分为四个类别:完全错误、部分正确但结果错误、部分错误但结论正确、完全正确。这些类别与 1-2、3-5、6-8 和 9-10 的评分范围相对应。
我们使用两种 Math-Critique 的评估方法:平均分数评估和硬分隔评估。前者计算给定问题集的每个模型答案分数的平均值;后者基于预定义的阈值将每个模型答案分类为通过或失败,超过阈值即为正确,反之为错误。
利用 MathCritique,我们为训练集生成了 5k 个带有注释的数据;并生成 800 个注释数据作为测试集。
Critique-RFT
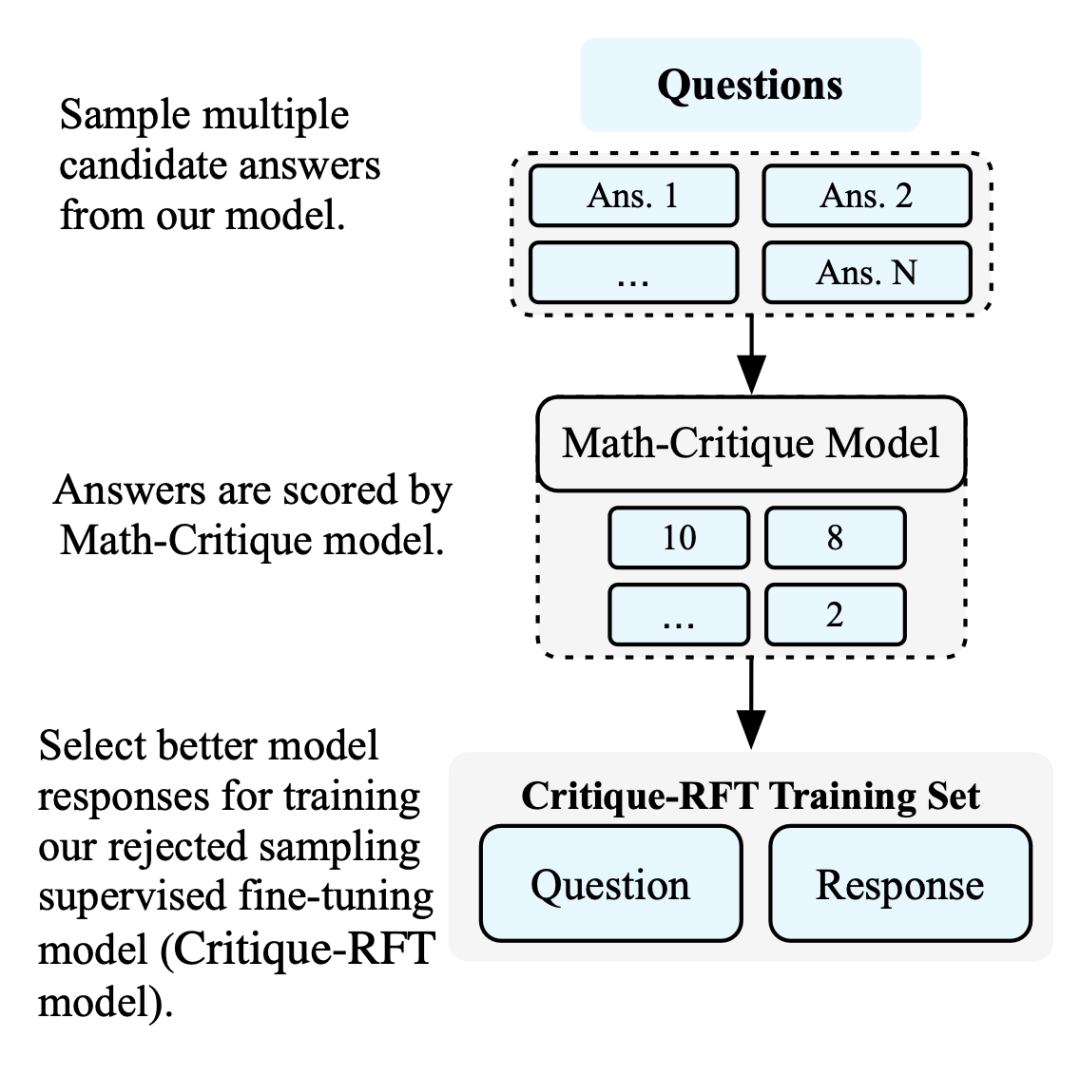
我们使用了基于 Math-Critique 的拒绝采样方法,重新审查和重新设计了RFT的实现,并发现在拒绝采样过程中,采样范围和模型都会影响结果。具体来说,我们设计了以下采样原则:
-
预去重:从训练集中对问题嵌入进行聚类,并在各个类别中均匀采样,确保在没有重复的情况下获取各种类型的问题。
-
后采样去重:我们在数学批评的结果基础上,在5-10个采样迭代之后进行了选择过程。在必要的去重之后,我们只在同一问题存在正确和不正确回答的情况下选择完全正确的回答。
Critique-DPO
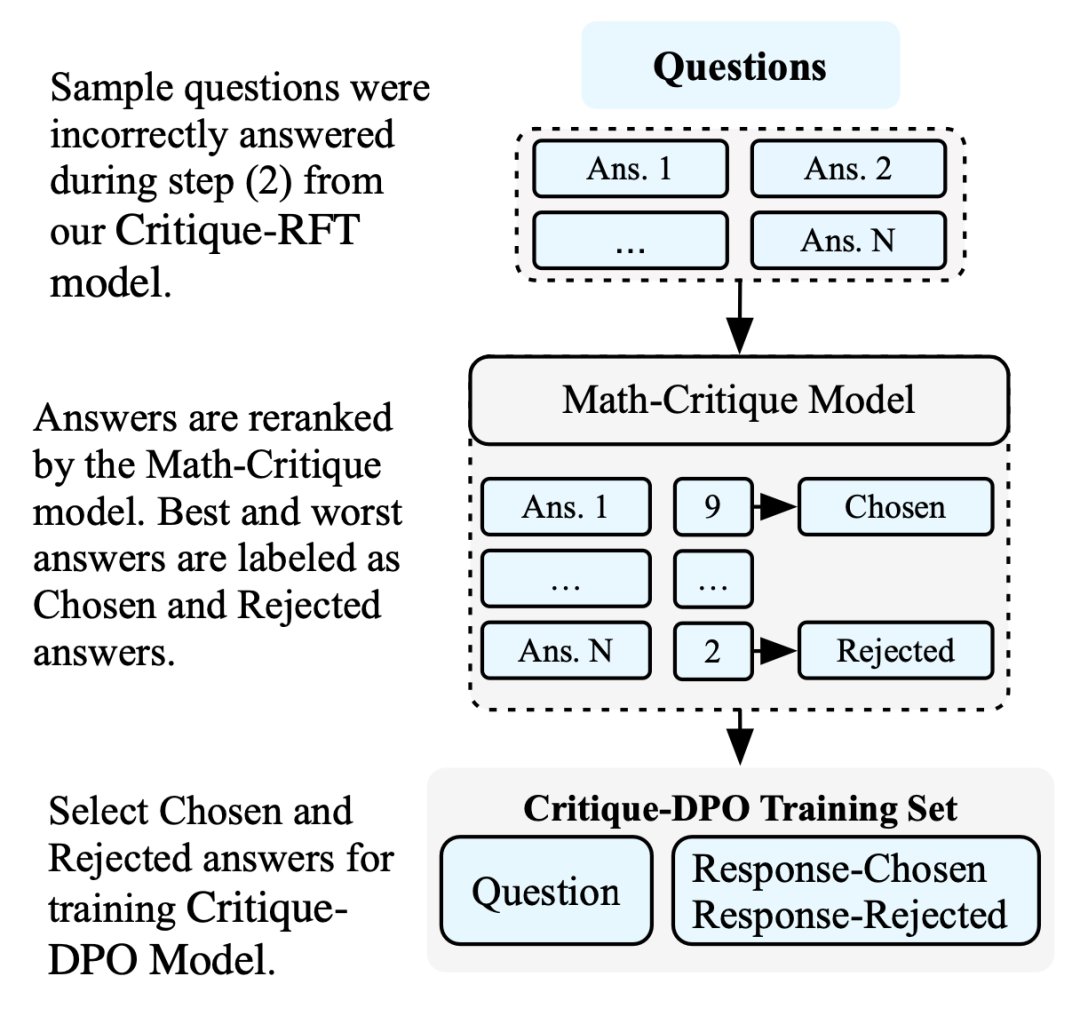
我们采用了DPO方法,以进一步增强模型能力,遵循Critique-RFT。该方法的主要优点在于在构建数据流、稳定性和训练速度方面的简单性。DPO方法直接比较了相同问题的正确和错误答案。
在我们的方法中,这两个答案都是从经过RFT后的模型中采样得到的,我们发现这一点至关重要。我们还在训练过程中集成了 DPO 正例的 SFT 损失,作为正则化项的近似替代。我们的 DPO 数据过滤过程类似于 Critique-RFT,唯一的区别在于 DPO 训练对的构建方法。在至少存在一个正确和一个错误答案的前提下,我们选择评分结果差异最大的数据对作为 DPO 对的选择。
训练过程
Math-Critique训练
我们使用ChatGLM3-32B的基础模型作为初始的Math-Critique基础模型。在每次迭代之后,通过SFT(监督微调)或评论RFT(评论反馈训练)当前经过优化的模型将被用作基础模型。我们在6B和32B模型上都使用学习率为3e-6和批量大小为128。
Critique-RFT训练
在Critique RFT阶段,我们的每次微调迭代都包括了前几个阶段的数据集经过去重后的结果,这也包括了最初的SFT数据集。我们将DRFT和DSFT合并为:
![]()
DSFT数据集包含许多常规任务,并且可以用开源指令微调数据集进行替代。为了消除这个数据集对最终结果的潜在干扰,我们在消融研究中比较了包含或排除SFT数据的影响。
Critique-DPO训练
在 Critique-DPO 阶段,观察到直接使用 DPO 损失会导致训练过程中的不稳定性。将所选答案的交叉熵损失作为总损失的正则化项引入来缓解这个问题。该加法旨在提高模型训练的稳定性。
![]()
在这种情况下,λ 表示总损失中所选答案的交叉熵损失系数。由于正则化项的加入,该系数的值高于标准 DPO,我们对该值的测试范围为 {0.5, 1, 2}。
此外,总学习速率设置为1e-6。实验部分将报告这些系数设置下的最佳结果。在这个阶段,我们以 64 的批大小训练 500 步。
测试集
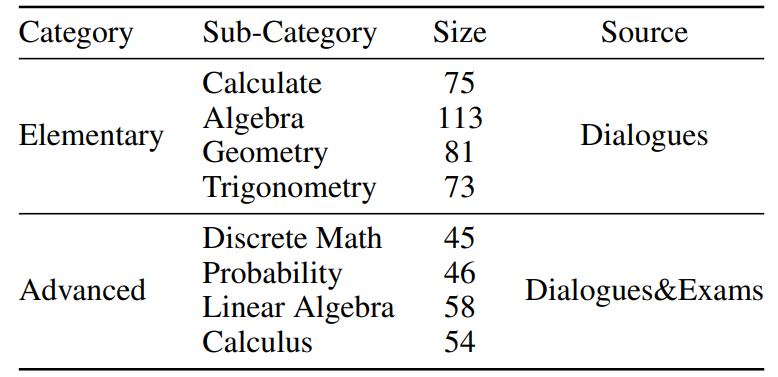
为了评估 LLM 的数学能力,我们设计了一个 MATHUSEREVAL基准测试集。这个测试集专门用于评估 LLM 解决实际应用场景中的复杂开放性数学问题的能力。
我们将测试集分为两个大类(初级和高级)和八个子类,见下表:
实验
数据
在我们的研究中,我们主要测试了MATHUSEREVAL数据集,该数据集源自模拟对话记录和实际考试试卷。与学术数据集相比,这个数据集具有更多样化的问题风格,并且更贴近于实际的使用场景。此外,我们还测试了以下学术数据集:
-
英语学术数据集:GSM8k和MATH。这两个数据集包含了中学和高中以及竞赛水平的英语数学问题。
-
中文学术数据集:ape210k和cmath。这些数据集中的问题也来自中学和高中水平。
我们还将匈牙利国家考试作为一个外部分布测试集。值得注意的是,在所有测试集中,我们只使用了GSM8k和MATH的训练集作为生成数据的种子数据。为了评估通用的语言能力,我们选择了AlignBench的中文语言组件和完整的MT-Bench进行测试。
结果
测试结果如下:
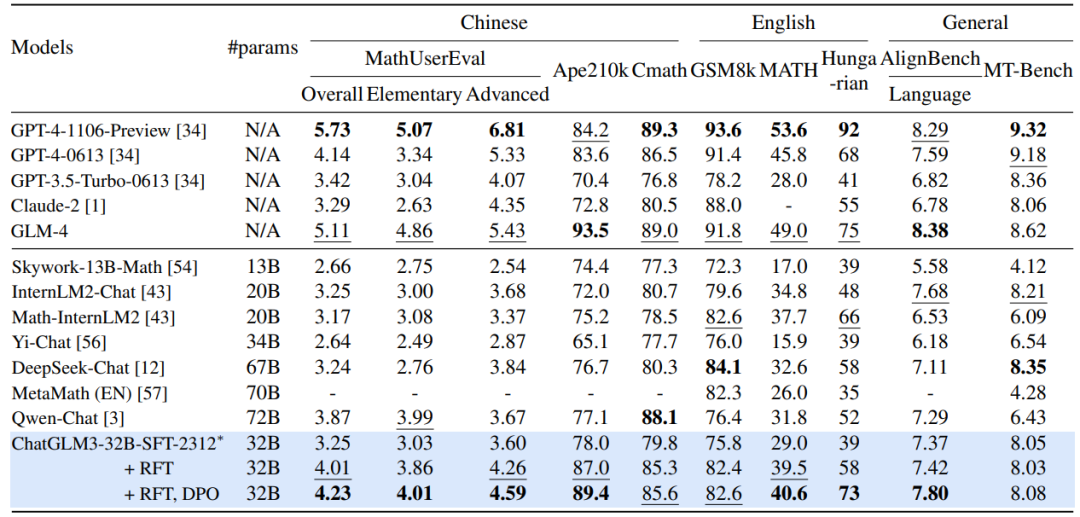
RFT &DPO 的影响:
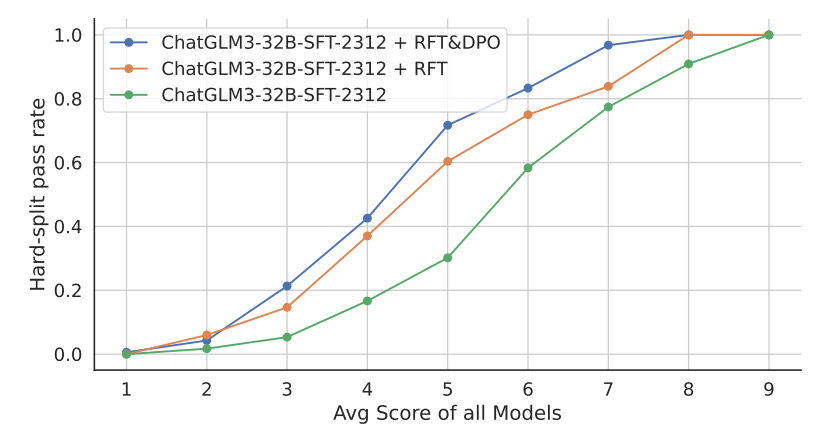
不同提升方法与问题难度的关系。横轴代表MATHUSEREVAL在24个模型中的平均得分(由GPT-4-1106-Preview评分),我们将其视为问题难度的表示。纵轴代表模型在这些问题上的硬分割分数。
可以看到,RFT几乎提高了所有难度级别的性能,但平均得分在4到6之间问题的表现改进最显著。DPO主要对平均得分在5到7之间问题的表现改进最显著。这表明,我们提高数学能力的RFT和DPO可以作为对齐模型与现实世界的有效方法,并且在中等难度的问题上改进最为显著。
Math-Critique能力评测:
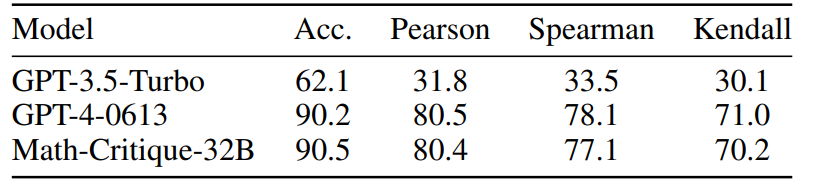
模型的Math-Critique评测。“Acc”代表模型回答正确与否的准确性,Math-Critique的Pearson、Spearman和Kendall相关系数与四类分类中的人类注释的比较。
结果表明,与人类注释相比,Math-Critique-32B模型在判断准确性和相关系数方面显著超过GPT3.5-Turbo,基本上与GPT-4.0613持平。

















 6982
6982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











