









《利用Python进行数据分析》一书中有这样一个创建虚拟变量的例子。
原始数据:
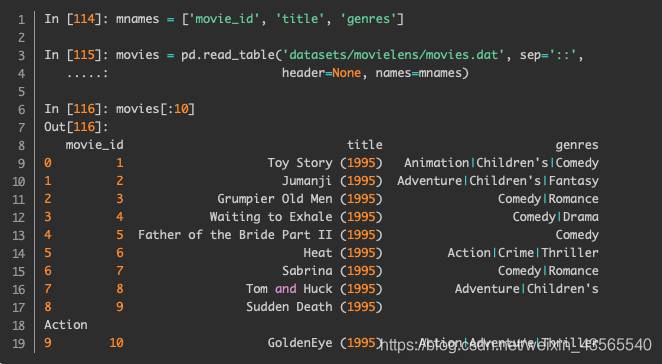
我们需要根据类别列genres生成每个电影所属类别的虚拟变量。首先问题在于每个观测属于多个类别,不能直接应用pd.get_dummies函数。
- 第一步:首先需要知道具体有多少种电影流派
all_genres = []
for x in movies.genres:
all_genres.extend(x.split('|'))
genres = pd.unique(all_genres)
- 第二步:创建一个用于储存虚拟变量的dataframe
zero_matrix = np.zeros((len(movies), len(genres))
dummies = pd.DataFrame(zero_matrix, columns = genres)
- 第三步:遍历每一部电影,根据电影所属的类别在
dummiesdataframe中进行标注
for i, gen in enumerate(movies.genres):
#dummies.columns 返回dummies的列标签
#.get_indexer方法返回列表区的索引值
# indices返回一个数组,储存了该电影所属类别对应的列标签
indices = dummies.columns.get_indexer(gen.split('|'))
# 使用iloc方法进行索引
dummies.iloc[i, indices] = 1
- 第四步:将虚拟变量结果与原始矩阵联合
movies_windic = movies.join(dummies.add_prefix('Genre_'))















 1425
1425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









