







Python定时爬取上证指数
作为一名初出茅庐的股民,在这中美贸易战的关键时刻,当然得实时关注我大A股的动向啦,所以就写了这只小爬虫~
- 选择网站
首先呢,各大网站都有A股指数的数据,但是对网易云的喜爱,让我选择了去爬 网易财经 ,就这样不地道的锁定了目标
http://quotes.money.163.com/0000001.html
然鹅,这是一个动态网站,数据都是实时更新,本人技术不够,没法用 requests 库来解决问题
于是乎,就选择了 selenium 库来模拟浏览器,实时抓取数据

browser = webdriver.Firefox()
browser.get('http://quotes.money.163.com/0000001.html')
在这里选择的是火狐浏览器,只是因为自己用的习惯了而已…
- 提取信息
虽然大家都爱用 BeautifulSoup (美丽汤)来提取信息,但我习惯于用 xpath ,毕竟萝卜白菜,各有所爱嘛,合适的才是最好的,实现功能才是王道
毕竟需要反复爬取数据,实时监控,就定义了一个函数,实现代码复用
def GetPrice(out_time,row):
while 1:
#获取当前页面源码
html=browser.page_source
#解析数据
html_ele = etree.HTML(html)
price = html_ele.xpath('/html/body/div[2]/div[1]/div[3]/table/tbody/tr/td[2]/div/table/tbody/tr[1]/td[1]/span/strong/text()')[0]
nowTimes = time.strftime('%H.%M',time.localtime())
print(nowTimes,price)
#将数据写入xls表格
sheet.write(row[0],0,nowTimes)
sheet.write(row[0],1,float(price))
row[0] = row[0]+1
if float(nowTimes)>=out_time:
print('时间到,下班喽')
break
time.sleep(60)
这里定义的两个传入数据 (out_time,row) ,第一个是爬虫结束的时间,第二个是 excel 写入时的行
print 语句是为了更好的交互,不然也不知道小爬虫在偷偷摸摸干嘛,还是得看着点
time.sleep(60) 每分钟爬一次,也别给人家服务器太大的压力了
细心的小伙伴可能已经发现了,在爬取数据的同时,也在存储数据了,这里没有选择 txt 文件,而是用 excel
毕竟如果要做图什么的,还是 excel 方便嘛
- 存储数据
利用 xlrd,xlwt 库来对 excel 文件进行读写
#创建储存数据的表格
row = [1]
workbook = xlwt.Workbook()
sheet = workbook.add_sheet("sheet")
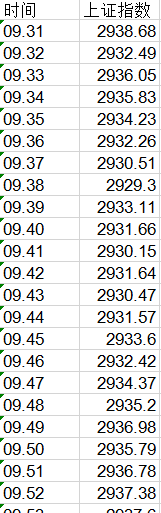
sheet.write(0,0,'时间')
sheet.write(0,1,'上证指数')
row = [1] :因为数字类型是不可变的,而列表类型可变,如果直接用 row = 1 会导致在下午时间段爬取时, excel 数据被覆盖掉
- 控制爬取过程
毕竟傲娇的大盘交易时间为9:30~11:30 , 13:00~15:00这短短的4个小时,其他时间爬取的也是无用数据
Relax(9.30)
GetPrice(11.30,row)
Relax(13.00)
GetPrice(15.00,row)
这里定义了一个 Relax 函数,在非交易时间段,让爬虫休息
def Relax(start_time):
while 1:
nowTimes = time.strftime('%H.%M',time.localtime())
print('当前时间:'+nowTimes,end=' ')
if float(nowTimes)>=start_time:
print('醒醒,该起床干活了,爬数据去...')
break
print('还早着呢,多睡会儿吧...')
time.sleep(60)
- 全代码
from selenium import webdriver
from lxml import etree
import time
import requests
import xlrd,xlwt
def GetPrice(out_time,row):
while 1:
#获取当前页面源码
html=browser.page_source
#解析数据
html_ele = etree.HTML(html)
price = html_ele.xpath('/html/body/div[2]/div[1]/div[3]/table/tbody/tr/td[2]/div/table/tbody/tr[1]/td[1]/span/strong/text()')[0]
nowTimes = time.strftime('%H.%M',time.localtime())
print(nowTimes,price)
#将数据写入xls表格
sheet.write(row[0],0,nowTimes)
sheet.write(row[0],1,float(price))
row[0] = row[0]+1
if float(nowTimes)>=out_time:
print('时间到,下班喽')
break
time.sleep(60)
def Relax(start_time):
while 1:
nowTimes = time.strftime('%H.%M',time.localtime())
print('当前时间:'+nowTimes,end=' ')
if float(nowTimes)>=start_time:
print('醒醒,该起床干活了,爬数据去...')
break
print('还早着呢,多睡会儿吧...')
time.sleep(60)
if __name__=='__main__':
#打开模拟浏览器
browser = webdriver.Firefox()
browser.get('http://quotes.money.163.com/0000001.html')
print('获取网页信息')
#创建储存数据的表格
row = [1]
workbook = xlwt.Workbook()
sheet = workbook.add_sheet("sheet")
sheet.write(0,0,'时间')
sheet.write(0,1,'上证指数')
#爬取数据
Relax(9.30)
GetPrice(11.30,row)
Relax(13.00)
GetPrice(15.00,row)
print('保存数据')
today = time.strftime('%Y-%m-%d',time.localtime())
workbook.save("{}.xls".format(today))
browser.close()
最后保存的文件名为今日
- 效果图
- 总结
该爬虫所用到的技术
- from selenium import webdriver: 爬取动态网页信息
- from lxml import etree:解析数据
- import xlrd,xlwt:对 excel 进行读写
- import time:控制时间,合理调度爬虫
最后,还请各位热爱python,热爱爬虫的小伙伴给出指导建议,一起交流,共同学习!!!














 610
610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









