







文献阅读
我认为这篇最大的亮点是从信息流的角度看待自注意力机制,但是网络设计有些牵强,解释有些生硬。
与non-local的主要区别:
1.有两个分支来学习关系;
2.参数是自适应的而非仅利用相似度。
仅从提高感受野的角度来看,与空洞卷积与全局池化的区别在于:
基于dilated-convolution和基于pooling扩展以一种非自适应的方式利用了所有图像区域的同构互依赖,忽略了不同区域的局部表示和不同种类上下文依赖的差异。
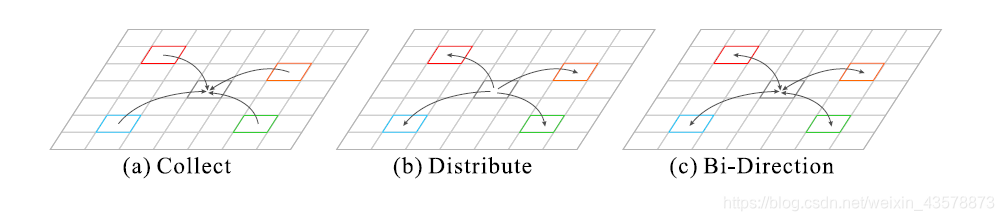
由于卷积滤波器的物理设计,卷积神经网络中的信息流被限制在局部邻域内,这限制了对复杂场景的整体理解。特征图上的每个位置都通过自适应学习的注意力模板与所有其他位置相连接。可以收集其他位置的信息来帮助预测当前位置,反之亦然,可以分布当前位置的信息来帮助预测其他位置。
特征图中的每个位置通过自适应预测注意力图与所有其他位置相连接,从而获取附近和远处的各种信息。
优势:
1.通过PSA模块学习到的掩模是自适应的
2.对位置和类别信息非常敏感
公式感觉很牵强,直接上结论:
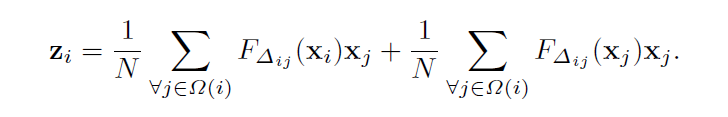
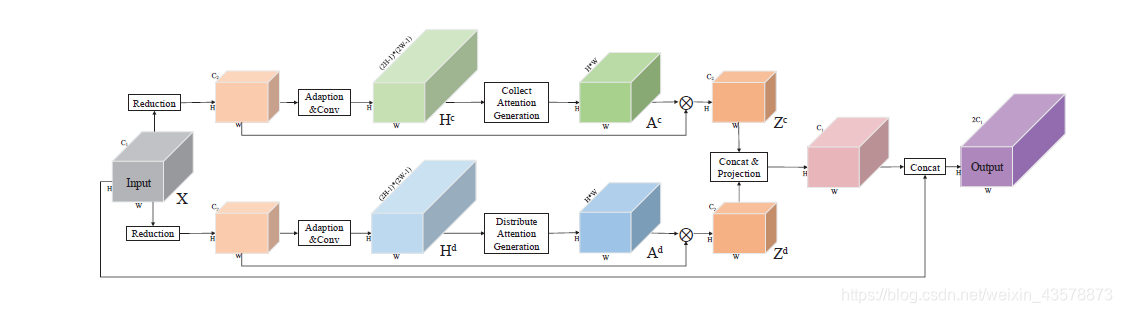
PSA模块首先生成两个逐点的空间attention map,即Ac和Ad由两个平行的支路构成;在每个分支中,首先应用1×1的卷积来减少输入feature map X的通道数,以减少计算开销;在此基础上,采用1×1卷积进行特征自适应;这些层均伴随着bn和激活函数;最后,一个卷积层负责为每个位置生成全局attention map。

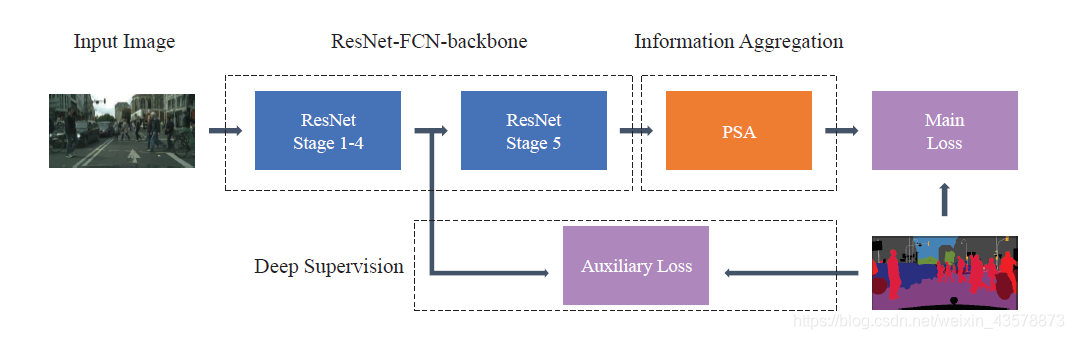
PSANet在FCN的基础上除了引入了PSA模块,还用了辅助损失。
整体框架如下:

















 2776
2776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









