







文章目录
lab1
实验内容
先看图,IPv4的数据报通过IP层后,提取出TCP报文段,交付给TCP层,数据segment交给TCPReceiver,ack确认信息交给TCPSender。发送也是一样的,TCPSender 发送的 segment + TCPReceiver 发送的接收窗口大小组成TCP报文段,交付给网络层形成IPv4数据报,发送出去。

而 lab1 要我们实现的就是TCPReceiver中的 StreamReassembler部分:
TCPReceiver接收端收到的是一个个的TCP数据段(segment),它们有可能并不按照发送端发出的顺序排列,还有可能发生丢失、重叠或者重复。我们需要一个工具来将这些可能是杂乱的数据段整理成顺序排列的信息,并且确保最终存入ByteStream的是正确的字节流
即我们此次lab要实现的StreamReassembler一个流重组器(stream reassembler),可以将带索引的字节流碎片重组成有序的字节流。重组完的字节流应当被送入指定的字节流ByteStream对象
_output中
重要点理解
由于英文水品不行,所以每次读lab时都难以get到题目的意思,导致我瞎思考了很多东西。
Interface
// Construct a `StreamReassembler` that will store up to `capacity` bytes.
StreamReassembler(const size_t capacity);
// Receive a substring and write any newly contiguous bytes into the stream,
// while staying within the memory limits of the `capacity`. Bytes that would
// exceed the capacity are silently discarded.
//
// `data`: the substring
// `index` indicates the index (place in sequence) of the first byte in `data`
// `eof`: the last byte of this substring will be the last byte in the entire stream
这里,push_substring,传递过来的 data :数据段内容 ; index:数据段的index,即TCP中的序号机制;eof:判断该数据段是否是某一大段的结尾
void push_substring(const string &data, const uint64_t index, const bool eof);
// Access the reassembled ByteStream (your code from Lab 0)
ByteStream &stream_out();
// The number of bytes in the substrings stored but not yet reassembled
size_t unassembled_bytes() const;
// Is the internal state empty (other than the output stream)?
bool empty() const;
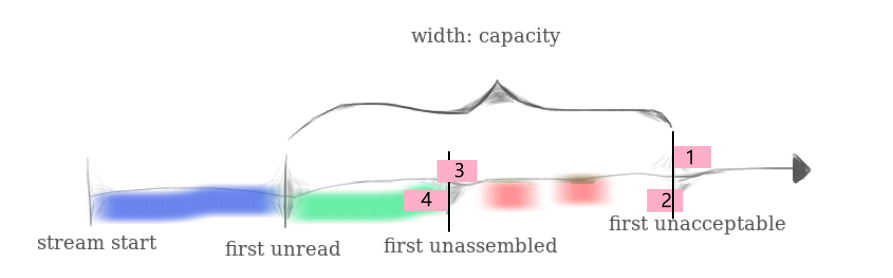
capacity
理解这个非常重要!!!
-
stream start:ByteStream交付给应用层的数据的开始下标,这里默认是0,实际上网络的开始序号值是随机的
-
first unread:第一个未写入ByteStream的数据的index; first_read = ByteStream.bytes_read() = ByteStream交付给应用层的字节数
-
first_unassembled:第一个未重组的数据index,尚未写入ByteStream 的第一个数据的index
-
first_unacceptable:第一个不可接收数据index,就是达到这个index的数据,都会被抛弃
-
最容易忽略的,就是ByteStream和StreamReassembler的容量都是capacity!
我们在红色区域对传递过来的,可能乱序、重复、冗余的数据进行重组排序,然后写入ByteStream,即绿色区域,而后ByteStream把数据交付给应用层,这个是我们在lab0已经实现了的

新来数据段的index
新到达的数据段的index是随机的,不确定的,所以可能位于上图的任意一个位置,但不会小于0,lab1的FAQs里面有讲,最小index是0
- 数据报的index在capacity之外,全部丢弃
- 数据报部部分超出容量限制,需要丢弃
- 数据报部部分重复,需要丢弃
- 数据报完全冗余,重复,全部丢弃
红色区域
我们要实现的部分其实就是红色区域,我们要对尚未交付到ByteStream的数据段,进行重新排序,等待ByteStream的调用。
那么怎么将乱序的数据段按照index进行排序呢?每个数据段有 index,代表开头的序号;data,代表数据内容和长度。这让我直接想到了Java里面的定义一个比较器Comparator,然后写一个类去实现比较器的接口,比较器的规则就是按照index进行升序排序。但是c++的话,太久没玩了,实在想不到。然后参考了其他博文才知道用set,基于红黑树的比较排序,而且是封装好了的,老好用了
合并问题
存放在set里面的数据段,它们只按照index进行了排序,但是它们之间除了有序之外,还有重复的,冗余的,所以要对数据段进行合并操作。
比如
- 第一个段:index = 7,data.length = 3
- 第二个段:index = 3, data.length = 3
它们按照在add进set时,就会自动排序,第二段在前,第一段在后,此时第三个段进来了
- 第三个段:index = 5,data.length = 3

那么,我们怎么对它们进行合并呢?
- 向后合并:先向后进行合并数据段,总是向新段上合并,这样合并完就变为了 index = 5, data.length = 5,被合并掉的字节数(merge_bytes)为 8-7 = 1,这个merge_bytes是用来维护红色区域的大小的。合并完的段如果是set的最后一段了并且不重合了,那么就停止了
- 向前合并:向后合并完,此时,set中剩下了 index = 3, length = 3, index = 5,length = 5 两段,很明显,需要合并。。。。策略相同,合并完的段如果是set的第一段了并且不重合,那么就停止了
总结思考
本次的lab1,其实很像leetcode的算法题的类型,给定接口,拓展函数实现即可。
- 读懂题意,花费时间在这上面绝对是值得的,理解才能实现,否则只会事倍功半
- 思考数据结构,读懂题意后,就应该考虑用什么样的数据结构来实现功能
- 划分功能,在小 module 上再划分更小的 功能模块,一段代码实现一个小功能
- 粗略的程序流程图,其实写代码的过程就是画流程图的过程,流程图可以很好地表达代码逻辑,查漏补缺
代码实现
下面的代码是这位大佬的,我只是多做了些解释
https://www.cnblogs.com/kangyupl/p/stanford_cs144_labs.html
stream_reassembler.hh
class StreamReassembler {
private:
// Your code here -- add private members as necessary.
// 结构体,block_node 记录segment 的开头index、长度、数据内容
// 重载了 < 运算符,使得能够在存入set时能够按照索引升序
struct block_node{
size_t begin = 0;
string data = "";
size_t length = 0;
//括号后面的 const,它的作用是 使得该函数可以被 const 对象所调用
bool operator < (const block_node t) const {
return begin < t.begin;
};
};
set<block_node> _blocks = {};
size_t _unassembled_byte = 0;
bool _eof_flag = false;
size_t _head_index = 0;
ByteStream _output; //!< The reassembled in-order byte stream
size_t _capacity; //!< The maximum number of bytes
long merge_block(block_node &elm1, const block_node &elm2);
public:
//! \brief Construct a `StreamReassembler` that will store up to `capacity` bytes.
//! \note This capacity limits both the bytes that have been reassembled,
//! and those that have not yet been reassembled.
StreamReassembler(const size_t capacity);
//! \brief Receive a substring and write any newly contiguous bytes into the stream.
//!
//! The StreamReassembler will stay within the memory limits of the `capacity`.
//! Bytes that would exceed the capacity are silently discarded.
//!
//! \param data the substring
//! \param index indicates the index (place in sequence) of the first byte in `data`
//! \param eof the last byte of `data` will be the last byte in the entire stream
void push_substring(const std::string &data, const uint64_t index, const bool eof);
//! \name Access the reassembled byte stream
//!@{
const ByteStream &stream_out() const { return _output; }
ByteStream &stream_out() { return _output; }
//!@}
//! The number of bytes in the substrings stored but not yet reassembled
//!
//! \note If the byte at a particular index has been pushed more than once, it
//! should only be counted once for the purpose of this function.
size_t unassembled_bytes() const;
//! \brief Is the internal state empty (other than the output stream)?
//! \returns `true` if no substrings are waiting to be assembled
bool empty() const;
};
stream_reassembler.cc
StreamReassembler::StreamReassembler(const size_t capacity) : _output(capacity), _capacity(capacity) {
}
long StreamReassembler::merge_block(block_node &elm1, const block_node &elm2){
block_node x,y;
if(elm1.begin < elm2.begin){
x = elm1;
y = elm2;
}else{
x = elm2;
y = elm1;
}
if(x.begin + x.length < y.begin){
return -1;
}else if(x.begin + x.length >= y.begin + y.length){
// x 包含 y
elm1 = x;
return y.length; //被合并的字节数
}else{
// x 与 y 部分重合,计算重合的部分,裁剪掉
elm1.begin = x.begin;
elm1.data = x.data + y.data.substr(x.begin + x.length - y.begin);
elm1.length = elm1.data.length();
return x.begin + x.length - y.begin;
}
}
//! \details This function accepts a substring (aka a segment) of bytes,
//! possibly out-of-order, from the logical stream, and assembles any newly
//! contiguous substrings and writes them into the output stream in order.
void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) {
if(index >= _head_index + _capacity){
return;
}
block_node elm;
// 处理冗余、超出capacity等的前缀
if(index + data.length() <= _head_index){
goto JUDGE_EOF;
}else if(index < _head_index){
size_t offset = _head_index - index;
elm.data.assign(data.begin() + offset, data.end());
elm.begin = index + offset;
elm.length = elm.data.length();
}else{
elm.begin = index;
elm.length = data.length();
elm.data = data;
}
_unassembled_bytes += elm.length;
//处理完后string,要放入 _block中,找到要插入的位置,判断是否能与前后子串进行合并,合并完之后,得到一个新elm,再放入_block中
do{
//先向后合并
long merged_bytes = 0;
// lower_bound返回不小于目标值的第一个对象的迭代器
auto iter = _block.lower_bound(elm);
while(iter != _block.end() && (merged_bytes = merge_block(elm,*iter)) >= 0){
_unassembled_bytes -= merged_bytes;
_block.erase(iter);
iter = _block.lower_bound(elm);
}
//向前合并
//判断iter是否已经是第一个元素了
if(iter == _block.begin()){
break;
}
iter--;
while((merged_bytes = merge_block(elm,*iter)) >= 0){
_unassembled_bytes -= merged_bytes;
_block.erase(iter);
iter = _block.lower_bound(elm);
if(iter == _block.begin()){
break;
}
iter --;
}
}while(false);
//合并完后,就可以向_block缓冲区存放
_block.insert(elm);
// write to ByteStream
//_blocks.begin()->begin == _head_index,这个是为了保证只有当缓冲区的第一个端前面所有的的数据报到了才能交付给ByteStream,
if (!_blocks.empty() && _blocks.begin()->begin == _head_index) {
const block_node head_block = *_blocks.begin();
// modify _head_index and _unassembled_byte according to successful write to _output
size_t write_bytes = _output.write(head_block.data);
_head_index += write_bytes;
_unassembled_byte -= write_bytes;
_blocks.erase(_blocks.begin());
}
JUDGE_EOF:
if (eof) {
_eof_flag = true;
}
if (_eof_flag && empty()) {
_output.end_input();
}
}
size_t StreamReassembler::unassembled_bytes() const { return _unassembled_bytes; }
bool StreamReassembler::empty() const { return _unassembled_bytes == 0; }
Reference
https://www.cnblogs.com/kangyupl/p/stanford_cs144_labs.html
https://zhuanlan.zhihu.com/p/262274265
https://blog.csdn.net/weixin_44520881/article/details/108911578
https://blog.csdn.net/u012495807/article/details/113193379
https://cs144.github.io/















 1117
1117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









