







实验部分
采用cs144的实验,实现大名鼎鼎的TCP协议(简单版本),此处只是说一下实现思路
Lab2需要安装libpcap
SYN (beginning of stream),FIN (end-of-stream)
注意,发送ack时,SYN和FIN也会占用字节(只是逻辑占用)。
“sender”和“receiver”被成为连接的“endpoints”或“peers.”
1.首先要实现一个可靠的双向字节流
2.再实现一个重排序模块,将乱序到来的数据(string类型)重新排序
3.TCPReceiver将TCP段转化为字节流,即将提取其负载(Segment转换为string),同时维护SYN和FIN,表征字节流的开始和结束;TCPSender则是反向转换。
3.1程序中的序列号以64位表示,这很难溢出。TCP段中的序列号以32位表示,可能会溢出。需要一个转换模块,从64位转换为32位很容易,反向转换则有歧义,我们还需要传入当前重新排序好的最后一个字节的索引(可用ByteStream中已写入的数量表示),找到距离此值最近的转换值。
(1)ByteStream:
使用循环队列实现,个人是使用String,维护其索引,核心为取模运算。每次计算索引都需要进行取模运算操作。
(2)StreamReassembler:
要求:排好序的在ByteStream中+未排好序但已接收的字节数 <= capacity。该功能其实使用ByteStream中的String就能实现,维护序号即可但需要修改ByteStream中私有变量,在不改变公共接口的情况下无法实现。
在该类中再加入一个String,专门存放未排好序但已接收的字节。
使用map实现,索引为第一个字节序号,值为最后一个字节序号(要考虑剩余空间大小)
接收到一个Substring后,将还未缓存的字节写入该类String(也可以简单粗暴的重新全部写入一遍,较好的方法是找到在map中的最后一个小于该区间左端索引(第一个>=该值的前一个),第一个>=右端索引之间的区间,遍历时遇到这些区间之间跳过,可直接使用lower_bound),再加入map中(在放入之前map中的集合是不重叠的)。
合并集合,确保没有重叠的集合。
若合并后的集合的第一个元素等于期待的下一个序号,则将其放入ByteStream,在map中删除该元素。
(3)Receiver:
相对比较简单,完成seqno到absoluate seqno的转换后,处理下SYN和FIN即可。
(4)Sender
使用map数据结构保存已发送未接收的数据,索引采用abs_seq,值为Segment
Segment中的Payload中的String采用智能指针实现,这样在保存该段副本时,不会重新拷贝底层String一份,节省空间。
注意的点:
1.接收方接收窗口为0,且当前没有未确认的数据时,发送方要认为其窗口为1,发送一个Seg。该数据可能会不断被拒绝,从而不断获取接收方接收窗口信息。
2.需要用一个bool量来确认当前接收窗口的容量是否为上述情况,而不能简单的判断发送方维护的接收窗口是否大于0。因为发送完某个Seg后其可能为0,但接收方并未接收时,接收方真正窗口大小并未减小为0,此时仍可以重传,RTO需要加倍,同时维护连续重传数量。
3.发送Seg,接收ack均需要改变发送方维护的窗口。窗口若满,则不将FIN标志加入其中。
4.fill_window应该用循环实现,只要有接收窗口及有待发送的数据就要发送。
(5)connection
这部分一定要搞清楚三次握手的状态转换,默认是工作在Listen状态。建立连接后,接收Seg处,因为可能改变接收窗口的大小,因此需要调用fill_window方法,以确保数据能够尽快发送出去。
CLOSE动作对应的就是end_input_stream函数,即向remote peer发送FIN标志。在local peer接收到FIN时,若发送过FIN,则有逗留时间,进入TIME WAIT状态,否则就没有逗留时间。
多次超时重发被触发后,最后一次超时不发送数据,直接关闭。
测试时由于网络问题后几个用例可能会超时,可以多测试几遍。在个人笔记本上的测试结果如下图所示:
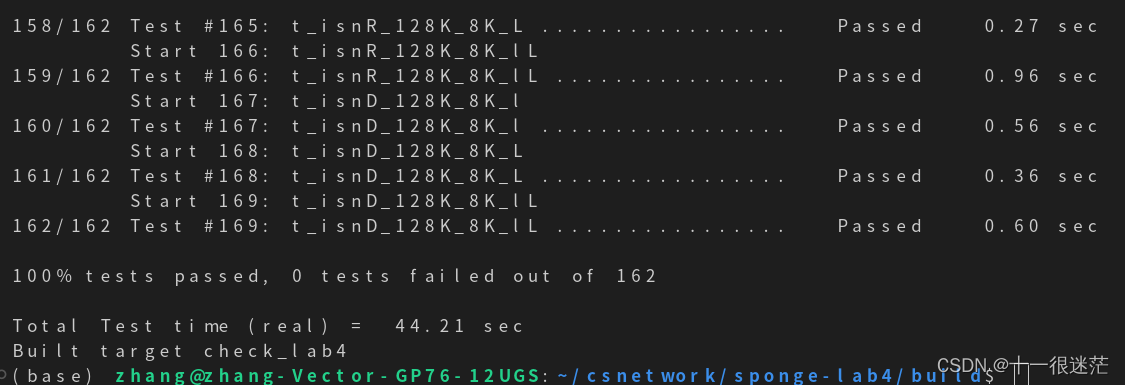
 超过了讲义要求的最低性能0.1Gbit/s。
超过了讲义要求的最低性能0.1Gbit/s。
原先的实现方式更像C语言的方式,这样直接使用索引操作容器底层在C++中并不高效,尤其在STL推荐应该更多使用区间操作。据此,可以更改下read和write的方式,即可小幅提高性能。

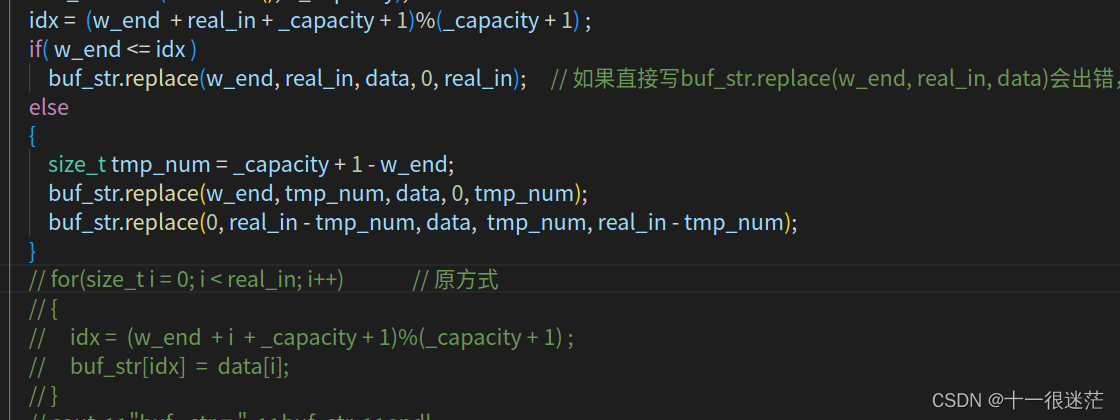
在此需要提醒一下,String的replace方法可能很难被注意到的地方,如上图所示。
str.replace(s,e,data);
这么写是直接把s到e之间的数据替代为data,在上述场景下有时在数据上没有问题,但请注意会可能改变原str的大小,从而发送意料外的结果。

性能分析
编译时需要加上-Og(优化调试体验),选项-pg能产生供gprof剖析用的可执行文件
利用Ubuntu下的gprof工具,可以分析我们的程序如下图所示:95%的耗时都在读写上,若想改进只能挑战这一部分。
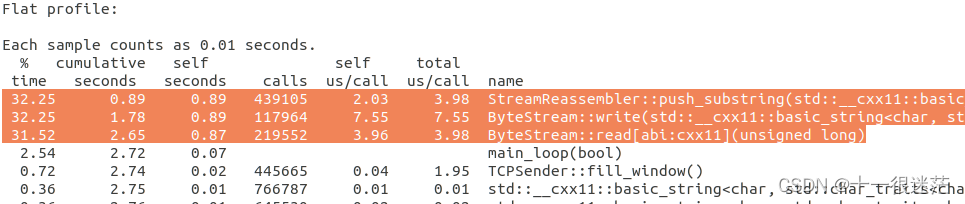
在ByteStream使用String,维护其索引,将其视为循环队列,这种方式更像C语言的方式,可能在C++容器中并不高效,推荐使用共享指针和移动语义,可参考buffer中的BufferList类。
使用BufferList的话,可以到超过1Gbit/s,接近实验讲义中的数字;
(6)网络接口:连接IP和以太网(或者说连接网络层和链路层),完成IP数据报到以太网的帧之间相互转换。
利用Address Resolution Protocol协议根据下一跳的IP地址找到数据报下一跳的MAC地址。接收到帧时,如果是IPv4数据报,则交给上层;如果是ARP请求或回复,网络接口会处理该帧,并根据需要进行学习或回复。
接收到以太网的帧后,首先看该帧的目标MAC地址是不是本机/广播地址,若是,则接收(以太网广播地址是 ff:ff:ff:ff:ff:ff);
(1)若为ARP请求,成功解析为ARPMessage后,还需要判断目标IP是否为本机IP,若是才学习和回复。
(2)若为IPv4类型,成功解析后,变成IPv4数据报。此时不需要比较IP,直接上传给上层。此处应该是兼顾了路由器的功能。
ARP协议例子:
X主机网络接口需要学习的映射类似为<ET(x),IP(x)>----EA(x),ET代表网络类型,如果本地没有匹配信息,则广播ARP请求。
ARP里面包含请求/回复,发送方IP,发送方MAC,目标IP,目标MAC。接收到该信息的Y主机匹配网络类型和IP,如果符合则解析该信息,并在本地保存<ET(x),IP(x)>----EA(x),识别出此为请求报文,填入相应信息,直接发送给X主机。
X主机得到回复报文后,本地保存<ET(y),IP(y)>----EA(y),丢弃。
结合tcp_over_ip.cc ----> 完成TCP段到IP数据报的相互转换。至此我们完成了TCP-in-IP-in-Ethernet Stack;
参考
中科大郑烇老师B站课程: link
实验参考链接: 大佬实现link
ARP参考:https://tools.ietf.org/html/rfc826














 386
386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









