







-
Flink在使用各种不同算子的同时,为了能更细粒度的控制数据和操作数据,给开发者提供了对现有函数功能进行扩展的能力,这就是函数类(FunctionClasses)。也可以简单地理解为
UDF函数(用户自定义函数) -
Flink每一个算子的参数都可以使用
lambda表达式和函数类两种的方式,其中如果使用函数类作为参数的话,需要让自定义函数继承指定的父类或实现特定的接口。
函数类(Function Classes)
- 函数类官方称之为:
user-defined function udf是接口,每种udf提供了自己独特的方法用于处理流中的每一条数据udf就是算子中的参数;各种算子对应各种udf;
(1)所有函数类接口的父接口都是Function,是一个空的接口,实现了序列化。


匿名函数(Lambda Functions)
就是Java8 Lambda表达式写法
DataStream<String> tweets = env.readTextFile("INPUT_FILE");
DataStream<String> flinkTweets = tweets.filter( tweet -> tweet.contains("flink") );
富函数(Rich Functions)☆
RichXxxFunction
RichXxxFunction是抽象类- 继承了
AbstractRichFunction抽象类,获取了RichFunction接口提供的功能; - 实现了
XxxFunction接口,获取了独特的处理数据的功能

Flink中的所有UserDefineFunction都有”富函数”版本,比如:
- MapFunction =>RichMapFunction
- FlatMapFunction => RichFlatMapFunction
- FilterFunction => RichFilterFunction
RichFunction

RichFunction是一个基本接口,也继承Function接口,此接口提供了两个额外功能:
- 获取function的生命周期的方法
- 获取function运行时上下文的方法
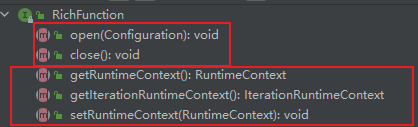
Rich-UDF的两个额外功能都是由RichFunction接口提供的,但是Rich-UDF并不直接继承此接口,flink提供了默认实现,放在AbstractRichFunction抽象类中
(1)两个生命周期方法
/**
* Initialization method for the function. It is called before the actual working methods
* (like <i>map</i> or <i>join</i>) and thus suitable for one time setup work. For functions that
* are part of an iteration, this method will be invoked at the beginning of each iteration superstep.
*
* <p>The configuration object passed to the function can be used for configuration and initialization.
* The configuration contains all parameters that were configured on the function in the program
* composition.
*
* <pre>{@code
* public class MyFilter extends RichFilterFunction<String> {
*
* private String searchString;
*
* public void open(Configuration parameters) {
* this.searchString = parameters.getString("foo");
* }
*
* public boolean filter(String value) {
* return value.equals(searchString);
* }
* }
* }</pre>
*
* <p>By default, this method does nothing.
*
* @param parameters The configuration containing the parameters attached to the contract.
*
* @throws Exception Implementations may forward exceptions, which are caught by the runtime. When the
* runtime catches an exception, it aborts the task and lets the fail-over logic
* decide whether to retry the task execution.
*
* @see org.apache.flink.configuration.Configuration
*/
void open(Configuration parameters) throws Exception;
/**
* Tear-down method for the user code. It is called after the last call to the main working methods
* (e.g. <i>map</i> or <i>join</i>). For functions that are part of an iteration, this method will
* be invoked after each iteration superstep.
*
* <p>This method can be used for clean up work.
*
* @throws Exception Implementations may forward exceptions, which are caught by the runtime. When the
* runtime catches an exception, it aborts the task and lets the fail-over logic
* decide whether to retry the task execution.
*/
void close() throws Exception;
1.open()方法:rich function的初始化方法,当一个算子例如map或者filter被调用之前open()会被调用。
2.close()方法:是生命周期中的最后一个调用的方法,做一些清理工作。
(2)生命周期方法的特点
- 生命周期方法提供了一种全局的视角,而非局限于单个元素;
生命周期方法是基于并行度的,并非整个dataStream只调用一次,而是一个并行度调用一次;生命周期方法可以提供一些建立在DataStream上的功能,比如获取第三方框架的连接
演示:生命周期方法是在并行度的基础上
public static class MyMapFunction extends RichMapFunction<SensorReading, Tuple2<Integer, String>> {
@Override
public Tuple2<Integer, String> map(SensorReading value) throws Exception {
return new Tuple2<>(getRuntimeContext().getIndexOfThisSubtask(), value.getId());
}
@Override
public void open(Configuration parameters) throws Exception {
System.out.println("my map open");
// 以下可以做一些初始化工作,例如建立一个和HDFS的连接
}
@Override
public void close() throws Exception {
System.out.println("my map close");
// 以下做一些清理工作,例如断开和HDFS的连接
}
}
@Test
public void map() throws Exception {
source = env.readTextFile("D:\\IdeaProjects\\bigdata\\flink\\src\\main\\resources\\sensort.txt");
SingleOutputStreamOperator<SensorReading> map = source.map(new MyMapFunction());
SingleOutputStreamOperator<Tuple2<Integer, String>> map1 = map.map(new MyMapRichFunction());
map1.print();
env.execute();
//my map open
//my map open
//my map open
//my map open
//3> (2,sensor_1)
//2> (1,sensor_1)
//1> (0,sensor_7)
//4> (3,sensor_1)
//my map close
//3> (2,sensor_6)
//my map close
//my map close
//1> (0,sensor_10)
//my map close
}
可以看到四个并行度,生命周期方法执行了四次;
(2)获取运行时上下文
getRuntimeContext()方法:获取函数的运行时上下文RuntimeContext,从中可以获取函数的信息:例如函数执行的并行度,任务的名字,以及状态编程(算子的状态)
此部分在状态编程中做介绍;















 715
715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









