







Python对HTML解析
Python对HTML的解析主要有以下几个库
- 使用BeautifulSoup库
- 使用XPath
- 使用pyquery
但是我们使用的一般是第一个库即bs
说明一下,这个库实在Python基础库中找不到的,即不属于Python的基础库,是属于第三方的库,所以我们要去下载
BeautifulSoup4库的安装
安装第四版

第一步是进入Anaconda的环境目录
第二部是选择项目用的环境
第三步是安装命令.
安装过程,最后是一个验证。
最后如果想卸载就
pip uninstall beautifulsoup4
输入这一行命令。还是在你使用的环境下。

就是一个简单的应用以及相应的解释
当然我们在运行当中会发现,虽然会有红色的警告,但是我们的程序可以正常运行,
这里的意思是,我们没有用解释器,但是呢系统自动给我们用了系统的解释器。
那么我们自己添加一下解释器

这里面就是我们传送的参数,我们需要在参数里面传入使用的解析器。

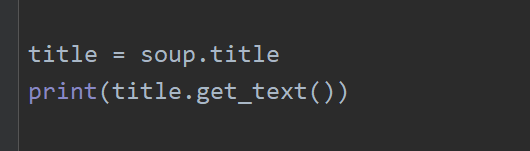
这里我们使用标签名获取内容,但是这个方法有个很大的缺陷,就是他只能获取第一个标签的内容。

下面我们写一个把他们的标签去掉,只保留内容。

加一个.string

看起来是一样的,但是也是有不一样的地方

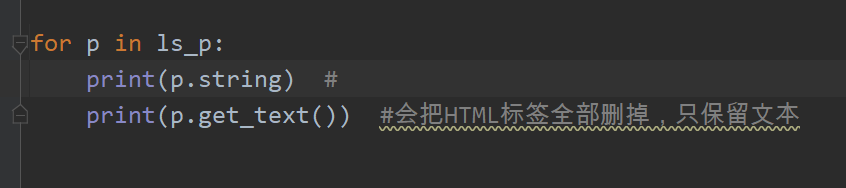
string方法通俗一点就是标签不等于1,就输出None。
Css选择器
- 标签名
- id
- class
我们可以用class名来选择想要爬取的内容
例如
通过这个我们就可以把小说名字全部爬取出来

这里说一个Findall的一个筛选的用法

自己悟一下。
如果我们想爬取的内容的class值有与之相同的节点的class值
我们可以去找父节点,但是找到父节点该怎么找下面的字节点

自己悟一下














 149
149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









