







selenium 软件功能测试工具
在环境中安装selenium

依旧是选择spider环境,然后pip下载

安装完成就会有成功提示

然后我们就能在环境里面找到。
第二部我们要安装浏览器驱动
因为selenium是之际操作浏览器啊,所以要python操作浏览器的驱动程序


进入之后他会有很多版本,我们需要下载跟自己浏览器版本一致的驱动。

这里说一下,先找下面有没有跟你版本号完全一致的驱动程序,如果有,一定下载与版本号完全一致的驱动,如果没有就找最新的,然后进入点击notes

看看是否支持你的版本。

下载完成后解压,将驱动程序,复制到项目的根目录

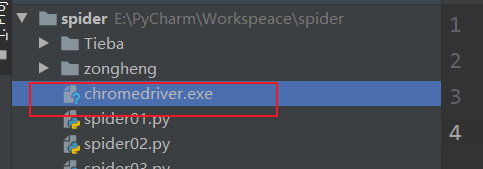
这里需要注意,如果放在根目录下不可以就放在你选择环境的Scripts文件夹下


然后我们想打开淘宝网页并且操控他输入一个华为手机并搜索

'''
selenium
软件功能测试工具
'''
from selenium import webdriver
import time
# 打开相应的浏览器,获取对象
chrome = webdriver.Chrome()
# 请求url
url = 'https://www.jd.com/'
chrome.get(url)
# 找到页面中的输入框
input = chrome.find_element_by_id('key')
# 像输入框中添加字符串
input.send_keys('华为手机')
# 模拟键盘输入回车
input.send_keys('\n')
time.sleep(10)
chrome.close()

代码放在这,自己配置环境之后试试。
获取页面信息
这里为什么要加sleep,因为我们需要在主页输入并且搜索,网页有一个数据接收的过程,所以我们需要先让程序挂起10s,然后再获取源代码。
但是有的网页打开慢,有的网页打开快,还可能受限于我们的网速,所以我们总不能把他设置的很长,所欲这里就有一个等待页面的方式

'''
selenium
软件功能测试工具
'''
from selenium import webdriver
import time
# 打开相应的浏览器,获取对象
chrome = webdriver.Chrome()
# 请求url
url = 'https://www.jd.com/'
chrome.get(url)
# 找到页面中的输入框
input = chrome.find_element_by_id('key')
# 像输入框中添加字符串
input.send_keys('华为手机')
# 模拟键盘输入回车
input.send_keys('\n')
'''
获取页面信息
time.sleep(10)
创建等待对象
第一个参数:等待的浏览器对象
第二个参数:等待的最长的时间
'''
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
wait = WebDriverWait(chrome, 10)
# 等待一个操作 presence_of_all_elements_located(对象) 等待对象加载完成
# 或者等待超时
m_list = wait.until(EC.presence_of_all_elements_located((By.CLASS_NAME, 'm-list')))
# 获取到的是一个节点
print(m_list)
print(chrome.page_source)
time.sleep(10)
chrome.close()
下面说一下我们selenium里面怎么选择我们想爬取的节点的内容
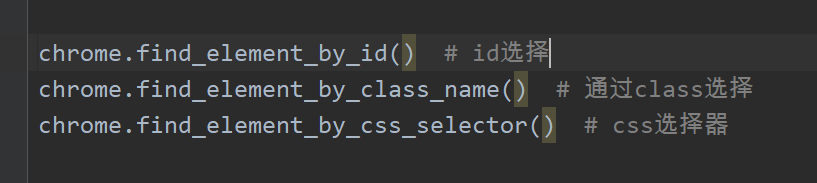
当然细心的人发现了,他还有一种形式是elements,复数嘛,不带s获取一个,带s获取所有。
先选取节点。

获取class为gl-item的节点
输出节点
输出节点文本内容
输出节点某一属性值
获取clss为J_goodsList里面的li标签节点
g_list = wait.until(EC.presence_of_element_located((By.ID, 'J_goodsList')))
ls_li = g_list.find_elements_by_tag_name('li') # 用列表名字获取节点,获取g_list里面的li节点
print(len(ls_li))
但是这种方法经常会获取到我们不必要的列表元素。所以我们用class来获取
g_list = wait.until(EC.presence_of_element_located((By.ID, 'J_goodsList')))
ls_li = g_list.find_elements_by_class_name('gl-item') # 用列表名字获取节点,获取g_list里面的li节点
print(len(ls_li))

但是呢通过输出我们发现,他只能获取初加载的30个手机信息,所以我们要用js命令来获取全部

理解一下
下面放出全部代码,可以自己试验一下
'''
selenium
软件功能测试工具
'''
from selenium import webdriver
import time
# 打开相应的浏览器,获取对象
chrome = webdriver.Chrome()
# 请求url
url = 'https://www.jd.com/'
chrome.get(url)
# 找到页面中的输入框
input = chrome.find_element_by_id('key')
# 像输入框中添加字符串
input.send_keys('华为手机')
# 模拟键盘输入回车
input.send_keys('\n')
'''
获取页面信息
time.sleep(10)
创建等待对象
第一个参数:等待的浏览器对象
第二个参数:等待的最长的时间
'''
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
wait = WebDriverWait(chrome, 10)
# 等待一个操作 presence_of_all_elements_located(对象) 等待对象加载完成
# 或者等待超时
g_list = wait.until(EC.presence_of_element_located((By.ID, 'J_goodsList')))
ls_li = g_list.find_elements_by_class_name('gl-item') # 用列表名字获取节点,获取g_list里面的li节点
print(len(ls_li))
chrome.execute_script('arguments[0].scrollIntoView()', ls_li[len(ls_li) - 1])
time.sleep(10)
for ls in ls_li:
price = ls.find_element_by_css_selector('.p-price i')
print(price.text)
name = ls.find_element_by_css_selector('.p-name em')
print(name.text)
# 获取到的是一个节点
# print(m_list)
# print(chrome.page_source)
# li = chrome.find_element_by_class_name('gl-item')
# print(li)
# print(li.text)
# print(li.get_attribute('class'))
time.sleep(10)
chrome.close()
# chrome.find_element_by_id() # id选择
# chrome.find_element_by_class_name() # 通过class选择
# chrome.find_element_by_css_selector() # css选择器














 149
149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









