







Map 端优化
Map 端聚合
map-side 预聚合,就是在每个节点本地对相同的 key 进行一次聚合操作,类似于MapReduce 中的本地 combiner。map-side 预聚合之后,每个节点本地就只会有一条相同的key,因为多条相同的 key 都被聚合起来了。其他节点在拉取所有节点上的相同 key 时,就会大大减少需要拉取的数据数量,从而也就减少了磁盘 IO 以及网络传输开销。
RDD 的话建议使用 reduceByKey 或者 aggregateByKey 算子来替代掉 groupByKey 算子。因为 reduceByKey 和 aggregateByKey 算子都会使用用户自定义的函数对每个节点本地的相同 key 进行预聚合。而 groupByKey 算子是不会进行预聚合的,全量的数据会在集群的各个
节点之间分发和传输,性能相对来说比较差。
SparkSQL 本身的 HashAggregte 就会实现本地预聚合+全局聚合。
读取小文件优化
读取的数据源有很多小文件,会造成查询性能的损耗,大量的数据分片信息以及对应
产生的 Task 元信息也会给 Spark Driver 的内存造成压力,带来单点问题。
设置参数:
spark.sql.files.maxPartitionBytes=128MB-- 默认 128m
spark.files.openCostInBytes=4194304--- 默认 4m
参数(单位都是 bytes):
➢ maxPartitionBytes:一个分区最大字节数。
➢ openCostInBytes:打开一个文件的开销。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num executors 3 --executor-cores 2 --executor-memory 6g --class com.atguigu.sparktuning.map.MapSmallFileTuning spark-tuning-1.0-SNAPSHOT jar-with-dependencies.jar
具体代码:
package com.atguigu.sparktuning.map
import com.atguigu.sparktuning.utils.InitUtil
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}
object MapSmallFileTuning {
def main( args: Array[String] ): Unit = {
val sparkConf = new SparkConf().setAppName("MapSmallFileTuning")
.set("spark.files.openCostInBytes", "7194304") //默认4m
.set("spark.sql.files.maxPartitionBytes", "128MB") //默认128M
// .setMaster("local[1]") //TODO 要打包提交集群执行,注释掉
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
sparkSession.sql("select * from sparktuning.course_shopping_cart")
.write
.mode(SaveMode.Overwrite)
.saveAsTable("sparktuning.test")
// while (true) {}
}
}

1)切片大小= Math.min(defaultMaxSplitBytes, Math.max(openCostInBytes, bytesPerCore))
计算 totalBytes 的时候,每个文件都要加上一个 open 开销
defaultParallelism 就是 RDD 的并行度
2)当(文件 1 大小+ openCostInBytes)+(文件 2 大小+ openCostInBytes)+…+(文件
n-1 大小+ openCostInBytes)+ 文件 n <= maxPartitionBytes 时,n 个文件可以读入同一个分
区,即满足: N 个小文件总大小 + (N-1)*openCostInBytes <= maxPartitionBytes 的话。
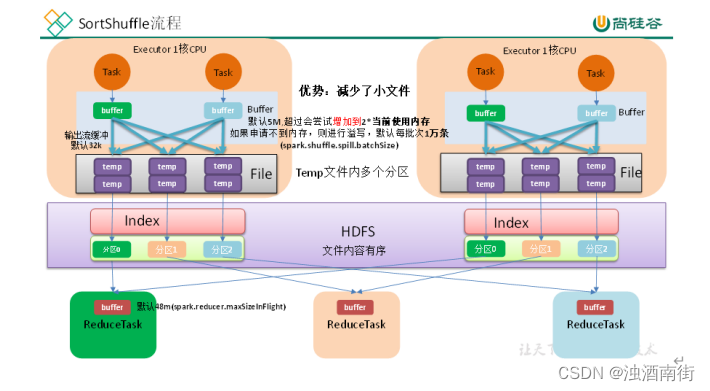
增大 map 溢写时输出流 buffer
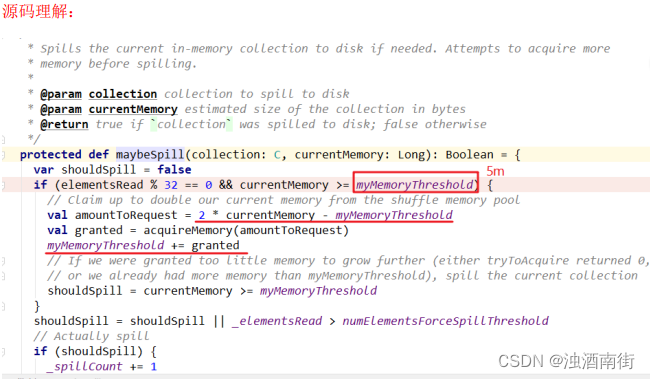
1)map 端 Shuffle Write 有一个缓冲区,初始阈值 5m,超过会尝试增加到 2*当前使用内存。如果申请不到内存,则进行溢写。这个参数是 internal,指定无效(见下方源码)。也就是说资源足够会自动扩容,所以不需要我们去设置。
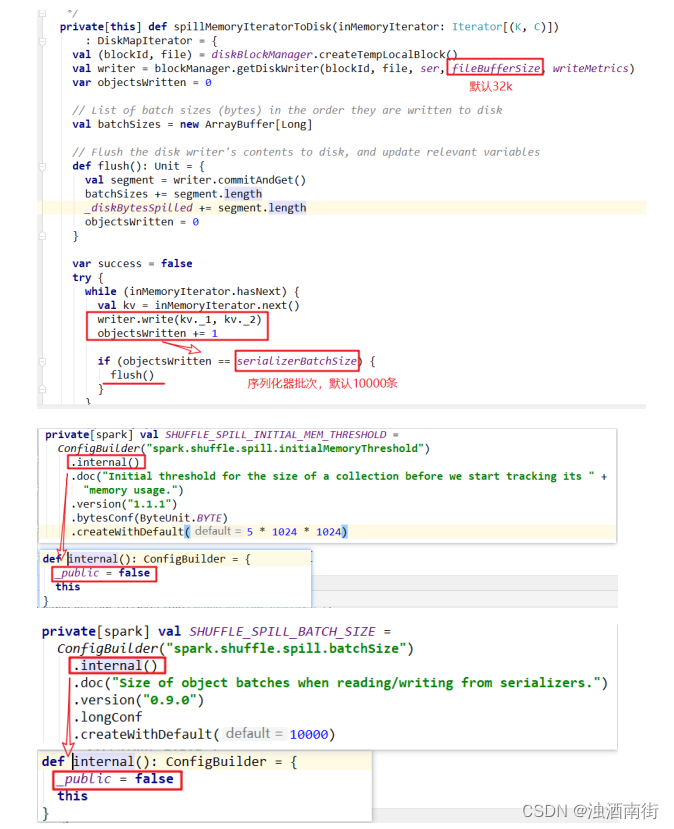
2)溢写时使用输出流缓冲区默认 32k,这些缓冲区减少了磁盘搜索和系统调用次数,适当提高可以提升溢写效率。
3)Shuffle 文件涉及到序列化,是采取批的方式读写,默认按照每批次 1 万条去读写。设置得太低会导致在序列化时过度复制,因为一些序列化器通过增长和复制的方式来翻倍内部数据结构。这个参数是 internal,指定无效(见下方源码)。
综合以上分析,我们可以调整的就是输出缓冲区的大小。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --numexecutors 3 --executor-cores 2 --executor-memory 6g --class com.atguigu.sparktuning.map.MapFileBufferTuning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
具体代码:
package com.atguigu.sparktuning.map
import com.atguigu.sparktuning.utils.InitUtil
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}
object MapFileBufferTuning {
def main( args: Array[String] ): Unit = {
val sparkConf = new SparkConf().setAppName("MapFileBufferTuning")
.set("spark.sql.shuffle.partitions", "36")
.set("spark.shuffle.file.buffer", "64")//对比 shuffle write 的stage 耗时
// .set("spark.shuffle.spill.batchSize", "20000")// 不可修改
// .set("spark.shuffle.spill.initialMemoryThreshold", "104857600")//不可修改
// .setMaster("local[1]") //TODO 要打包提交集群执行,注释掉
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
//查询出三张表 并进行join 插入到最终表中
val saleCourse = sparkSession.sql("select * from sparktuning.sale_course")
val coursePay = sparkSession.sql("select * from sparktuning.course_pay")
.withColumnRenamed("discount", "pay_discount")
.withColumnRenamed("createtime", "pay_createtime")
val courseShoppingCart = sparkSession.sql("select * from sparktuning.course_shopping_cart")
.drop("coursename")
.withColumnRenamed("discount", "cart_discount")
.withColumnRenamed("createtime", "cart_createtime")
saleCourse
.join(courseShoppingCart, Seq("courseid", "dt", "dn"), "right")
.join(coursePay, Seq("orderid", "dt", "dn"), "left")
.select("courseid", "coursename", "status", "pointlistid", "majorid", "chapterid", "chaptername", "edusubjectid"
, "edusubjectname", "teacherid", "teachername", "coursemanager", "money", "orderid", "cart_discount", "sellmoney",
"cart_createtime", "pay_discount", "paymoney", "pay_createtime", "dt", "dn")
.write.mode(SaveMode.Overwrite).saveAsTable("sparktuning.salecourse_detail")
// while (true) {}
}
}















 1249
1249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









