







第 9 周 15、 异常检测(Anomaly Detection)
15.5 异常检测与监督学习对比
之前我们构建的异常检测系统也使用了带标记的数据,与监督学习有些相似,下面的对比有助于选择采用监督学习还是异常检测:
两者比较:
| 异常检测 | 监督学习 |
|---|---|
| 非常少量的正向类(异常数据 𝑦 = 1), 大量的负向类(𝑦 = 0) | 同时有大量的正向类和负向类 |
| 许多不同种类的异常,非常难。根据非常 少量的正向类数据来训练算法。 | 有足够多的正向类实例,足够用于训练 算法,未来遇到的正向类实例可能与训练集中的非常近似。 |
| 未来遇到的异常可能与已掌握的异常、非常的不同。 | |
| 例如:欺诈行为检测 ,生产(例如飞机引擎),检测数据中心的计算机运行状况 | 例如:邮件过滤器, 天气预报 ,肿瘤分类 |
希望这节课能让你明白一个学习问题的什么样的特征,能让你把这个问题当作是一个异常检测,或者是一个监督学习的问题。另外,对于很多技术公司可能会遇到的一些问题,通常来说,正样本的数量很少,甚至有时候是 0,也就是说,出现了太多没见过的不同的异常类型,那么对于这些问题,通常应该使用的算法就是异常检测算法。
15.6 选择特征
对于异常检测算法,我们使用的特征是至关重要的,下面谈谈如何选择特征:
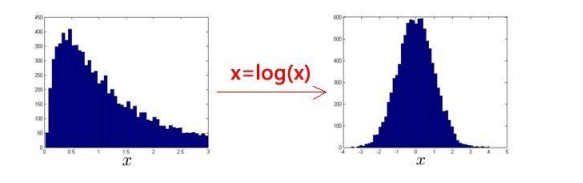
异常检测假设特征符合高斯分布,如果数据的分布不是高斯分布,异常检测算法也能够工作,但是最好还是将数据转换成高斯分布,例如使用对数函数:𝑥 = 𝑙𝑜𝑔(𝑥 + 𝑐),其中 𝑐为非负常数; 或者 𝑥 =
x
c
x^c
xc,𝑐为 0-1 之间的一个分数,等方法。
(编者注:在 python 中,通常用 np.log1p()函数,𝑙𝑜𝑔1𝑝就是 𝑙𝑜𝑔(𝑥 + 1),可以避免出现负数结果,反向函数就是 np.expm1())
误差分析:
一个常见的问题是一些异常的数据可能也会有较高的𝑝(𝑥)值,因而被算法认为是正常的。这种情况下误差分析能够帮助我们,我们可以分析那些被算法错误预测为正常的数据,观察能否找出一些问题。我们可能能从问题中发现我们需要增加一些新的特征,增加这些新特征后获得的新算法能够帮助我们更好地进行异常检测。
异常检测误差分析:
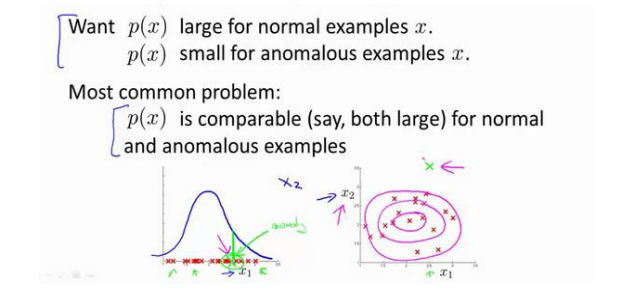
我们通常可以通过将一些相关的特征进行组合,来获得一些新的更好的特征(异常数据的该特征值异常地大或小),例如,在检测数据中心的计算机状况的例子中,我们可以用 CPU负载与网络通信量的比例作为一个新的特征,如果该值异常地大,便有可能意味着该服务器
是陷入了一些问题中。
在这段视频中,我们介绍了如何选择特征,以及对特征进行一些小小的转换,让数据更像正态分布,然后再把数据输入异常检测算法。同时也介绍了建立特征时,进行的误差分析方法,来捕捉各种异常的可能。希望你通过这些方法,能够了解如何选择好的特征变量,从而帮助你的异常检测算法,捕捉到各种不同的异常情况。














 340
340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









