







 本文介绍了在特征空间广泛的多元高斯分布如何应用于异常检测,通过协方差矩阵处理相关特征,以及如何通过计算样本均值和协方差矩阵估计参数。文章还讨论了多元高斯分布与原高斯分布的区别和在异常检测中的优势。
本文介绍了在特征空间广泛的多元高斯分布如何应用于异常检测,通过协方差矩阵处理相关特征,以及如何通过计算样本均值和协方差矩阵估计参数。文章还讨论了多元高斯分布与原高斯分布的区别和在异常检测中的优势。
第 9 周 15、 异常检测(Anomaly Detection)
15.7 多元高斯分布(选修)
假使我们有两个相关的特征,而且这两个特征的值域范围比较宽,这种情况下,一般的高斯分布模型可能不能很好地识别异常数据。其原因在于,一般的高斯分布模型尝试的是去同时抓住两个特征的偏差,因此创造出一个比较大的判定边界。
下图中是两个相关特征,洋红色的线(根据 ε 的不同其范围可大可小)是一般的高斯分布模型获得的判定边界,很明显绿色的 X 所代表的数据点很可能是异常值,但是其𝑝(𝑥)值却仍然在正常范围内。多元高斯分布将创建像图中蓝色曲线所示的判定边界。
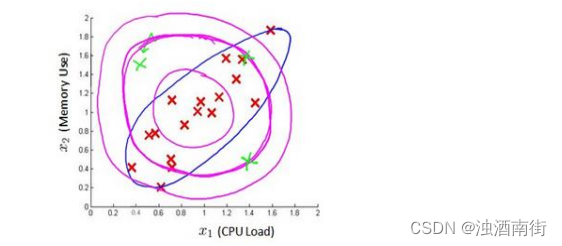
在一般的高斯分布模型中,我们计算 𝑝(𝑥) 的方法是: 通过分别计算每个特征对应的几率然后将其累乘起来,在多元高斯分布模型中,我们将构建特征的协方差矩阵,用所有的特征一起来计算 𝑝(𝑥)。
我们首先计算所有特征的平均值,然后再计算协方差矩阵:
p
(
x
)
=
∏
j
=
1
n
p
(
x
j
,
μ
j
,
σ
j
2
)
=
∏
j
=
1
n
1
2
π
σ
j
e
−
(
x
j
−
μ
j
)
2
2
σ
j
2
p(x) =\prod_{j=1}^n{p(x_j,\mu_j,\sigma_j^2 )} =\prod_{j=1}^n{\frac{1}{\sqrt{2\pi}\sigma_j}e^{-\frac{(x_j-\mu_j)^2}{2\sigma_j^2}}}
p(x)=j=1∏np(xj,μj,σj2)=j=1∏n2πσj1e−2σj2(xj−μj)2
μ
=
1
m
∑
i
=
1
m
x
(
i
)
\mu =\frac{1}{m}\sum_{i=1}^m{x^{(i)}}
μ=m1i=1∑mx(i)
∑
=
1
m
∑
i
=
1
m
(
x
(
i
)
−
μ
)
(
x
(
i
)
−
μ
)
T
=
1
m
(
X
−
μ
)
T
(
X
−
μ
)
∑=\frac{1}{m}\sum_{i=1}^m{(x^{(i)} -\mu)(x^{(i)} -\mu)^T} =\frac{1}{m}(X-\mu)^T(X-\mu)
∑=m1i=1∑m(x(i)−μ)(x(i)−μ)T=m1(X−μ)T(X−μ)
注:其中
μ
\mu
μ是一个向量,其每一个单元都是原特征矩阵中一行数据的均值。最后我们计算多元高斯分布的𝑝(𝑥):
p
(
x
)
=
1
(
2
π
)
n
2
∣
Σ
∣
1
2
e
(
−
1
2
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
)
p(x) = \frac{1}{(2\pi)^{\frac{n}{2}}|\Sigma|^{\frac{1}{2}}} e^{(-\frac{1}{2}(x-\mu)^T \Sigma^{-1} (x-\mu))}
p(x)=(2π)2n∣Σ∣211e(−21(x−μ)TΣ−1(x−μ))
其中:
|𝛴|是定矩阵,在 Octave 中用 det(sigma)计算
𝛴1 是逆矩阵,下面我们来看看协方差矩阵是如何影响模型的:
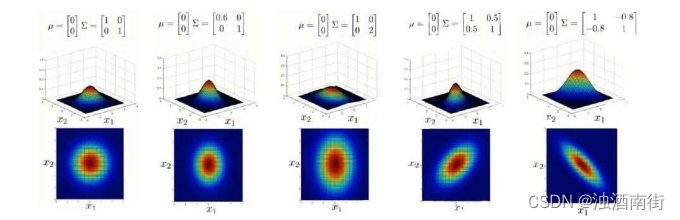
上图是 5 个不同的模型,从左往右依次分析:
- 是一个一般的高斯分布模型
- 通过协方差矩阵,令特征 1 拥有较小的偏差,同时保持特征 2 的偏差
- 通过协方差矩阵,令特征 2 拥有较大的偏差,同时保持特征 1 的偏差
- 通过协方差矩阵,在不改变两个特征的原有偏差的基础上,增加两者之间的正相关性
- 通过协方差矩阵,在不改变两个特征的原有偏差的基础上,增加两者之间的负相关性
多元高斯分布模型与原高斯分布模型的关系:
可以证明的是,原本的高斯分布模型是多元高斯分布模型的一个子集,即像上图中的第1、2、3,3 个例子所示,如果协方差矩阵只在对角线的单位上有非零的值时,即为原本的高斯分布模型了。
原高斯分布模型和多元高斯分布模型的比较:
| 原高斯分布模型 | 多元高斯分布模型 |
|---|---|
| 不能捕捉特征之间的相关性 但可以通过将特征进行组合的方法来解决 | 自动捕捉特征之间的相关性 |
| 计算代价低,能适应大规模的特征 | 计算代价较高 训练集较小时也同样适用 |
| 必须要有 𝑚 > 𝑛,不然的话协方差矩阵 不可逆的,通常需要 𝑚 > 10𝑛 另外特征冗余也会导致协方差矩阵不可逆 |
原高斯分布模型被广泛使用着,如果特征之间在某种程度上存在相互关联的情况,我们可以通过构造新新特征的方法来捕捉这些相关性。
如果训练集不是太大,并且没有太多的特征,我们可以使用多元高斯分布模型。
15.8 使用多元高斯分布进行异常检测(选修)
在我们谈到的最后一个视频,关于多元高斯分布,看到的一些建立的各种分布模型,当你改变参数,𝜇 和 𝛴。在这段视频中,让我们用这些想法,并应用它们制定一个不同的异常检测算法。
要回顾一下多元高斯分布和多元正态分布:
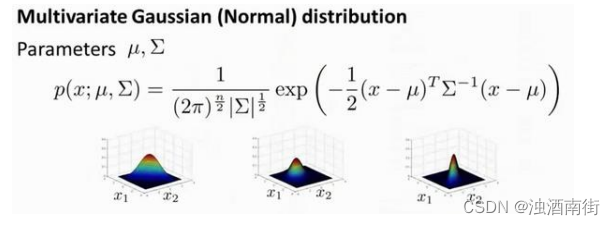
分布有两个参数, 𝜇 和 𝛴。其中𝜇这一个𝑛维向量和 𝛴 的协方差矩阵,是一种𝑛 × 𝑛的矩阵。而这里的公式𝑥的概率,如按 𝜇 和参数化 𝛴,和你的变量 𝜇 和 𝛴,你可以得到一个范围的不同分布一样,你知道的,这些都是三个样本,那些我们在以前的视频看过了。
因此,让我们谈谈参数拟合或参数估计问题:
我有一组样本𝑥(1), 𝑥(2), . . . , 𝑥(𝑚)是一个𝑛维向量,我想我的样本来自一个多元高斯分布。我如何尝试估计我的参数 𝜇 和 𝛴 以及标准公式?
估计他们是你设置 𝜇 是你的训练样本的平均值。
μ
=
1
m
∑
i
=
1
m
x
(
i
)
\mu=\frac{1}{m}\sum_{i=1}^m{x^{(i)}}
μ=m1i=1∑mx(i)
并设置𝛴:
Σ
=
1
m
∑
i
=
1
m
(
x
(
i
)
−
μ
)
(
x
(
i
)
−
μ
)
T
Σ =\frac{1}{m}\sum_{i=1}^m{(x^{(i)} -\mu)(x^{(i)} -\mu)^T}
Σ=m1i=1∑m(x(i)−μ)(x(i)−μ)T
这其实只是当我们使用 PCA 算法时候,有 𝛴 时写出来。所以你只需插入上述两个公式,这会给你你估计的参数 𝜇 和你估计的参数 𝛴。所以,这里给出的数据集是你如何估计 𝜇 和𝛴。让我们以这种方法而只需将其插入到异常检测算法。那么,我们如何把所有这一切共同开发一个异常检测算法?
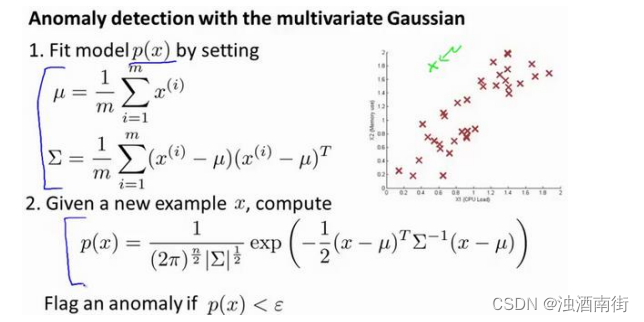
首先,我们把我们的训练集,和我们的拟合模型,我们计算𝑝(𝑥),要知道,设定𝜇和描述的一样𝛴。

如图,该分布在中央最多,越到外面的圈的范围越小。
并在该点是出路这里的概率非常低。
原始模型与多元高斯模型的关系如图:
其中:协方差矩阵𝛴为:
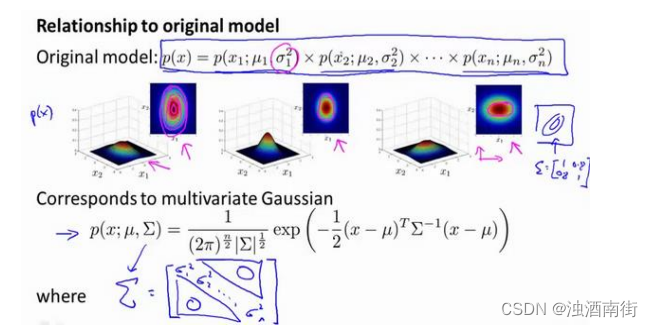
原始模型和多元高斯分布比较如图:
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









