







模型介绍
对于有监督的数据挖掘算法而言,数据集中需要包含标签变量(即因变量y的值)。但是有些场景下,并没有给定的y值,对于这类数据的建模,一般称为无监督的数据挖掘算法,,最为典型的当属聚类算法。
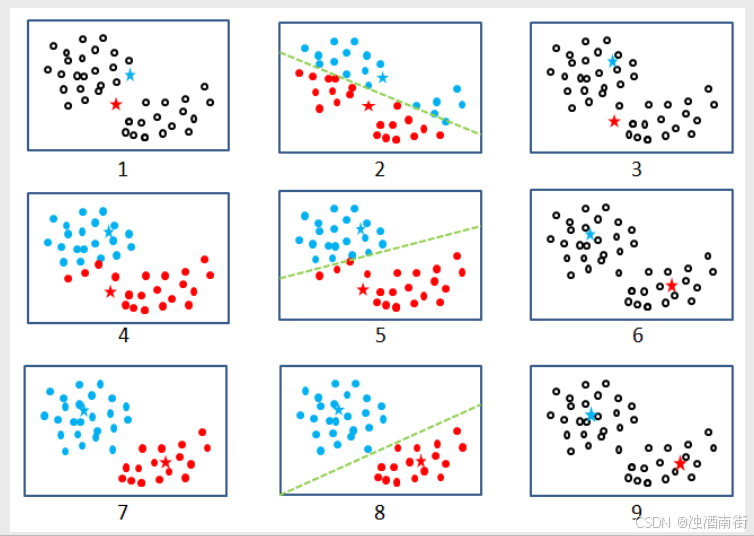
kmeans 聚类算法利用距离远近的思想将目标数据聚集为指定的k个簇,进而使样本呈现簇内差异小,簇间差异大的特征。
聚类步骤
1.从数据中随机挑选k个样本点作为原始的簇中心
2.计算剩余样本与簇中心的距离,并把各样本标记为离k个簇中心最近的类别
3.重新计算各簇中样本点的均值,并以均值作为新的k个簇中心
4.不断重复第二步和第三步,直到簇中心的变化趋于稳定,形成最终的k个簇
原理介绍
在kmeans聚类模型中,对于指定的k个簇,只有簇内样本越相似,聚类效果才越好。基于这个思想,可以理解为簇内样本的离差平均之和
达到最小即可。进而可以衍生出kmeans聚类的目标函数:
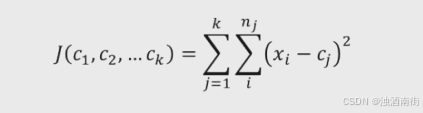
其中, c j c_j cj表示第j个簇的簇中心, x i x_i xi属于第j个簇的样本i, n j n_j nj表示第j个簇的样本总量。对于该目标函数而言, c j c_j cj是未知的参数,要想求得目标函数的最小值,得先知道参数 c j c_j cj的值。
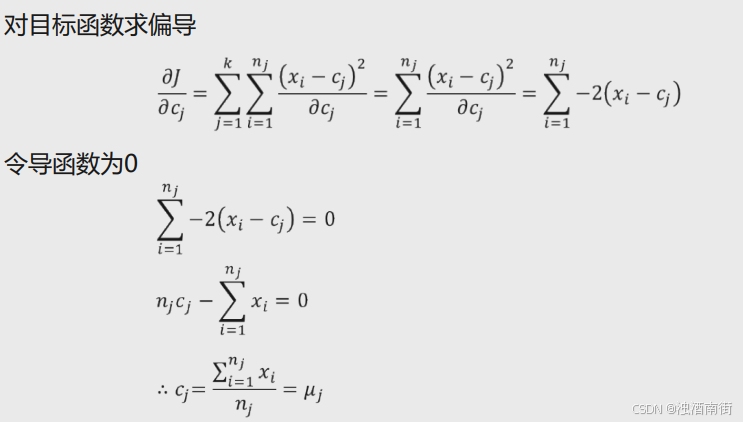
k值的选择
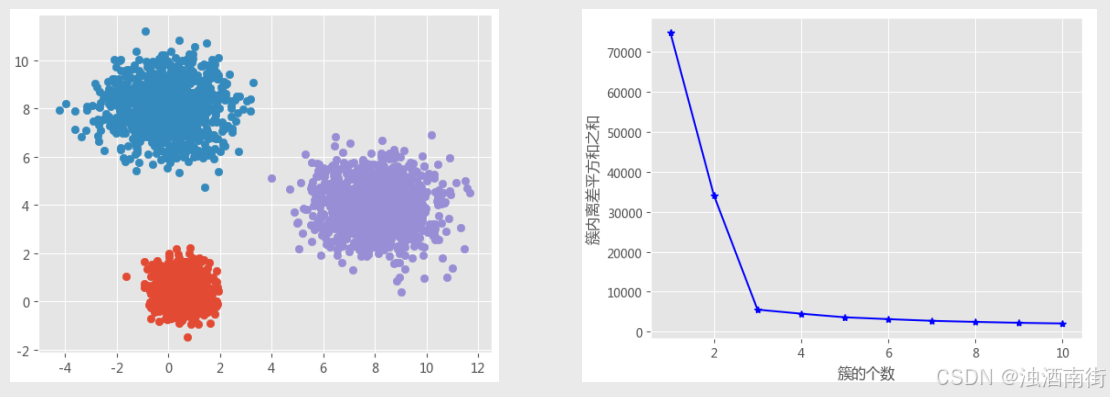
拐点法
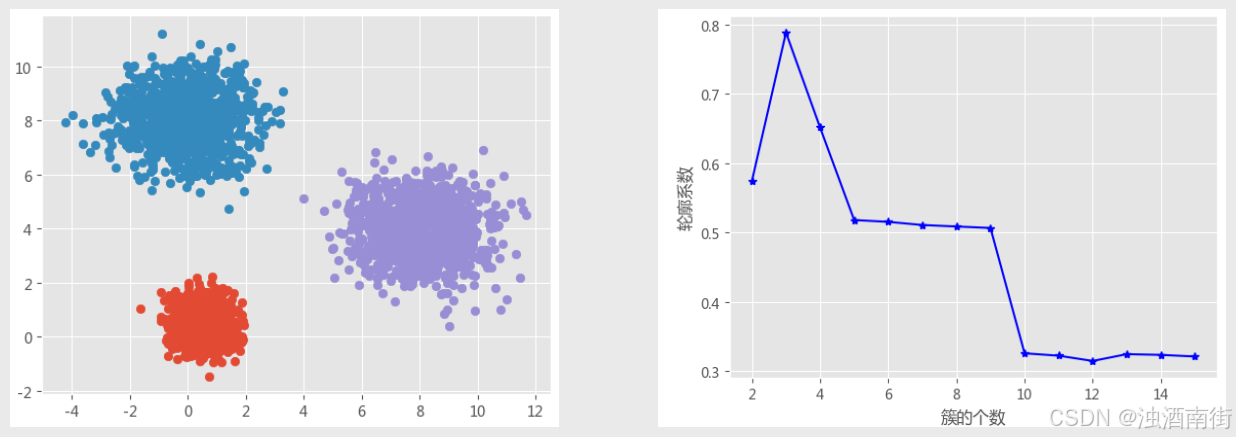
簇内离差平方和拐点法的思想很简单,就是在不同的k值下计算簇内离差平方和,然后通过可视化的方法找到“拐点”所对应的k值,当折线图中的斜率由大突然变小时,并且之后的斜率变化缓慢,则认为突然变化的点就是寻找的目标点,因为继续随着簇数k的增加,聚类效果不再有大的变化。
def k_SSE(X, clusters):
# 选择连续的K种不同的值
K = range(1,clusters+1)
# 构建空列表用于存储总的簇内离差平方和
TSSE = []
for k in K:
# 用于存储各个簇内离差平方和
SSE = []
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
# 返回簇标签
labels = kmeans.labels_
# 返回簇中心
centers = kmeans.cluster_centers_
# 计算各簇样本的离差平方和,并保存到列表中
for label in set(labels):
SSE.append(np.sum((X.loc[labels == label,]-centers[label,:])**2))
# 计算总的簇内离差平方和
TSSE.append(np.sum(SSE))
轮廓系数法
该方法综合考虑了簇的密集性与分散性两个信息,如果数据集被分割为理想的个簇,那么对应的簇内样本会很密集,而簇间样本会很分散。轮廓系数的计算公式可以表示为:
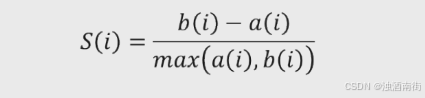
其中, a ( i ) a(i) a(i)体现了簇内的密集性,代表样本i与同簇内其他样本点距离的平均值; b ( i ) b(i) b(i)反应了簇间的分散性,它的计算过程是,样本i与其它非同簇样本点距离的平均值,然后从平局值中挑选出最小值。
当
S
(
i
)
S(i)
S(i)接近于-1时,说明样本i分配的不合理,需要将其分配到其他簇中;当
S
(
i
)
S(i)
S(i)近似为0时,说明样本i落在了模糊地带,即簇的边界处;
当
S
(
i
)
S(i)
S(i)近似为1时,说明样本i的分配是合理的。
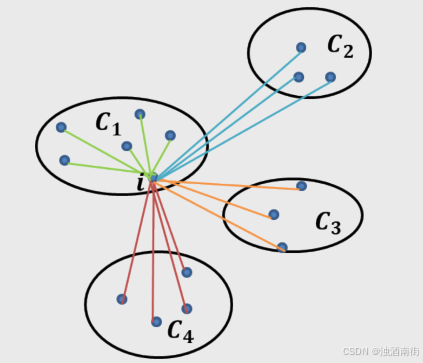
假设数据集被拆分为4个簇,样本i对应的
a
(
i
)
a(i)
a(i)值就是所有
C
i
C_i
Ci中其他样本点与样本i的距离平均值;样本i对应的
b
(
i
)
b(i)
b(i)值分两步计算,首先计算该带你分别到
C
2
C_2
C2,
C
3
C_3
C3和
C
4
C_4
C4中样本点的平均距离,然后将三个平均值中的最小值作为
b
(
i
)
b(i)
b(i)的度量。
# 构造自定义函数
def k_silhouette(X, clusters):
K = range(2,clusters+1)
# 构建空列表,用于存储不同簇数下的轮廓系数
S = []
for k in K:
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
labels = kmeans.labels_
# 调用子模块metrics中的silhouette_score函数,计算轮廓系数
S.append(metrics.silhouette_score(X, labels, metric='euclidean'))



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









