







前言
make_moons 是 scikit-learn 中用于生成合成数据集的函数,专门用于创建两个交错的半月形(或新月形)数据集。这种数据集常用于演示聚类算法(如 DBSCAN)或分类算法(如 SVM)在处理非线性可分数据时的性能。以下是详细介绍:
函数介绍
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=100,
noise=0.1,
random_state=None,
shuffle=True)
核心参数
n_samples (默认 100):生成的总样本数(两个半月形各占一半,如 n_samples=100 则每个半月形含 50 个点)。
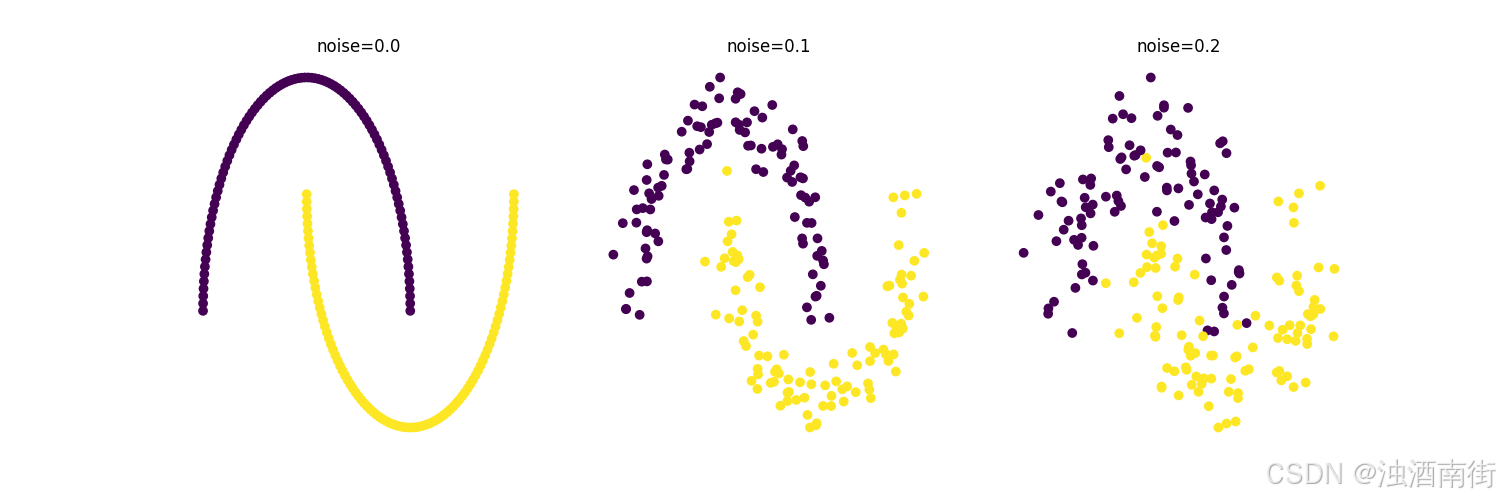
noise (默认 0.1):添加到数据中的噪声标准差,控制数据点的分散程度。值越大,半月形边界越模糊(见下图示例)。
random_state:随机种子,保证生成的数据可复现。
shuffle (默认 True):是否打乱生成的数据顺序。
返回值
X:形状为 (n_samples, 2) 的数组,表示生成的二维数据点坐标。
y:形状为 (n_samples,) 的数组,表示数据点的类别标签(0 或 1)。
使用示例
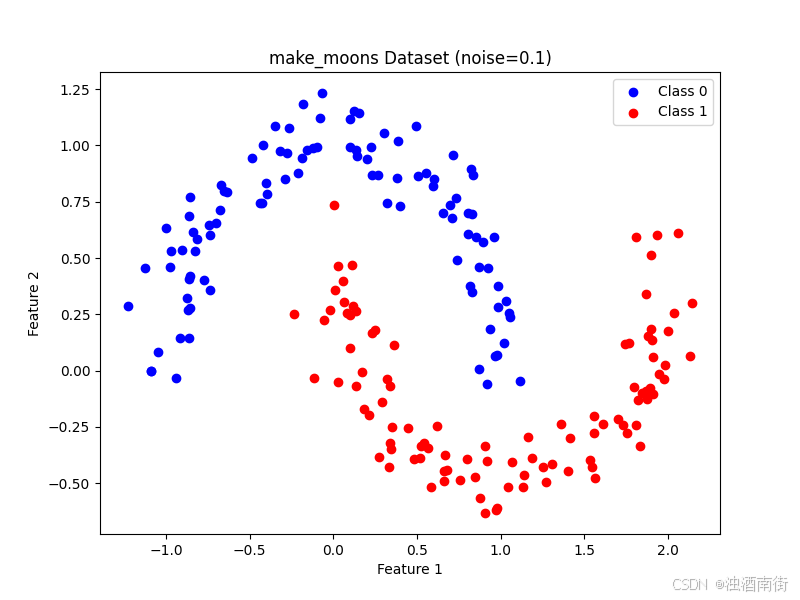
- 生成数据并可视化
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
# 生成数据
X, y = make_moons(n_samples=200, noise=0.1, random_state=42)
# 绘制半月形数据
plt.figure(figsize=(8, 6))
plt.scatter( X[y == 0, 0], X[y == 0, 1], c="blue", label="Class 0")
plt.scatter( X[y == 1, 0], X[y == 1, 1], c="red", label="Class 1")
plt.title("make_moons Dataset (noise=0.1)")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.legend()
plt.show()
- 不同噪声对比
noise_levels = [0.0, 0.1, 0.2]
plt.figure(figsize=(15, 5))
for i, noise in enumerate(noise_levels):
X, y = make_moons(n_samples=200, noise=noise, random_state=42)
plt.subplot(1, 3, i+1)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap="viridis")
plt.title(f"noise={noise}")
plt.axis("off")
plt.show()


















 1089
1089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









