







 商用集群作为成本效益高的并行计算解决方案,通过集中化的可扩展架构和数据并行处理,推动了大数据分析向低成本、高容错方向发展。其架构包括冗余数据存储和数据并行工作重启机制,确保了系统在部分组件故障时仍能稳定运行。
商用集群作为成本效益高的并行计算解决方案,通过集中化的可扩展架构和数据并行处理,推动了大数据分析向低成本、高容错方向发展。其架构包括冗余数据存储和数据并行工作重启机制,确保了系统在部分组件故障时仍能稳定运行。
基本概念:Scalable Computing over the Internet 基于互联网的可伸缩计算
1. 定义
Commodity cluster are affordable parallel computers with an average number of computing nodes. There are not as powerful as traditional parallel computers and are often built out of less specialized nodes.(来节省开支)
是一种虽然接没有传统并行计算机群算力强但是费用更低的折中商业方案。
2. 架构
Commdity cluster 架构:所有的计算机被集中在可拓展的racks上,通过快速的网络相连(下图是三个)
- 分布式计算: 在一个或多个集群中通过局域网或internet进行计算称为分布式计算 ,这样的架构支持我们的数据并行。在数据并行中,许多没有共享的工作可以在不同的数据集或数据集的不同部分上工作。(工作级并行(job level parallelism))
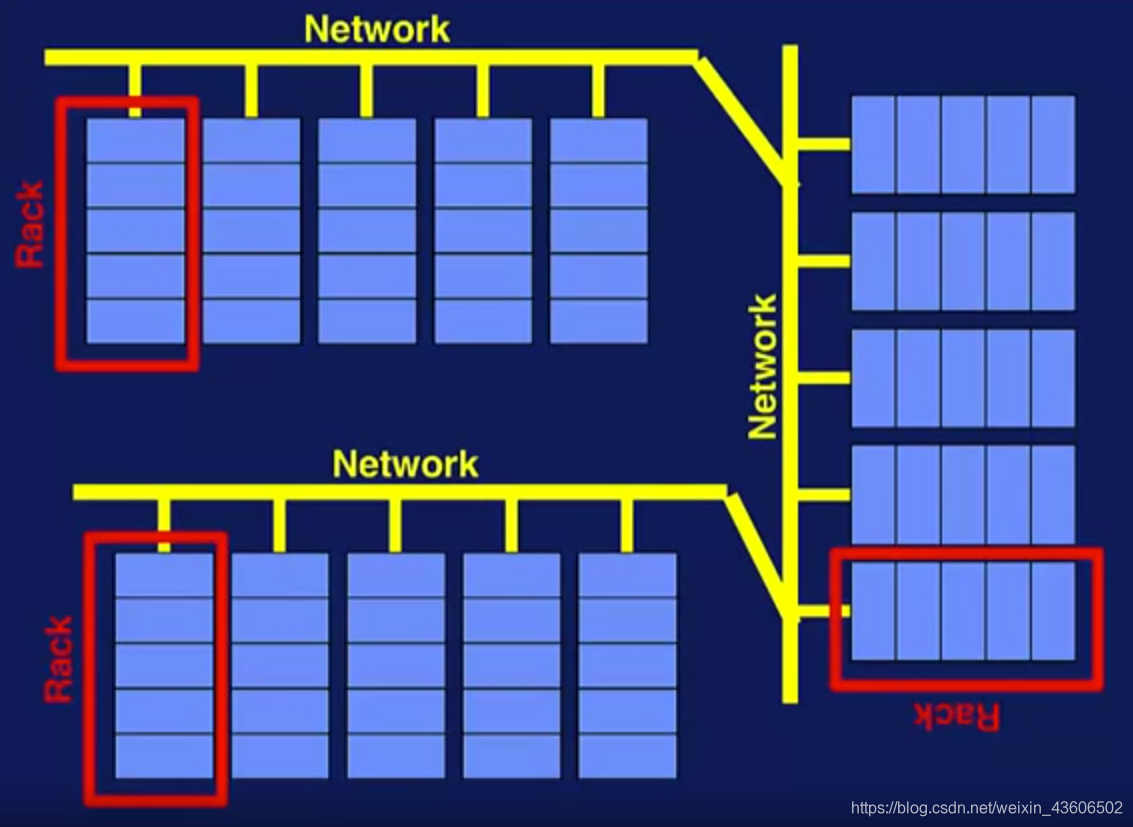
这种类型的并行有时候被称为作业级并行。但是在这种专门化中,我们将其称为大数据计算环境中的数据并行。利用这种并行模式,可以分析海量、多种类的大数据,实现可扩展性、性能和成本的降低。
- 容错性:一个节点或整个机架可能在任何给定时间发生故障。Rack到网络的连接可能会停止,或者各个节点之间的连接可能会中断。如果每一次故障都进行重启是不现实的。从这种失败中恢复的能力称为容错。对于这种系统的容错性,出现了两个简洁的解决方案。
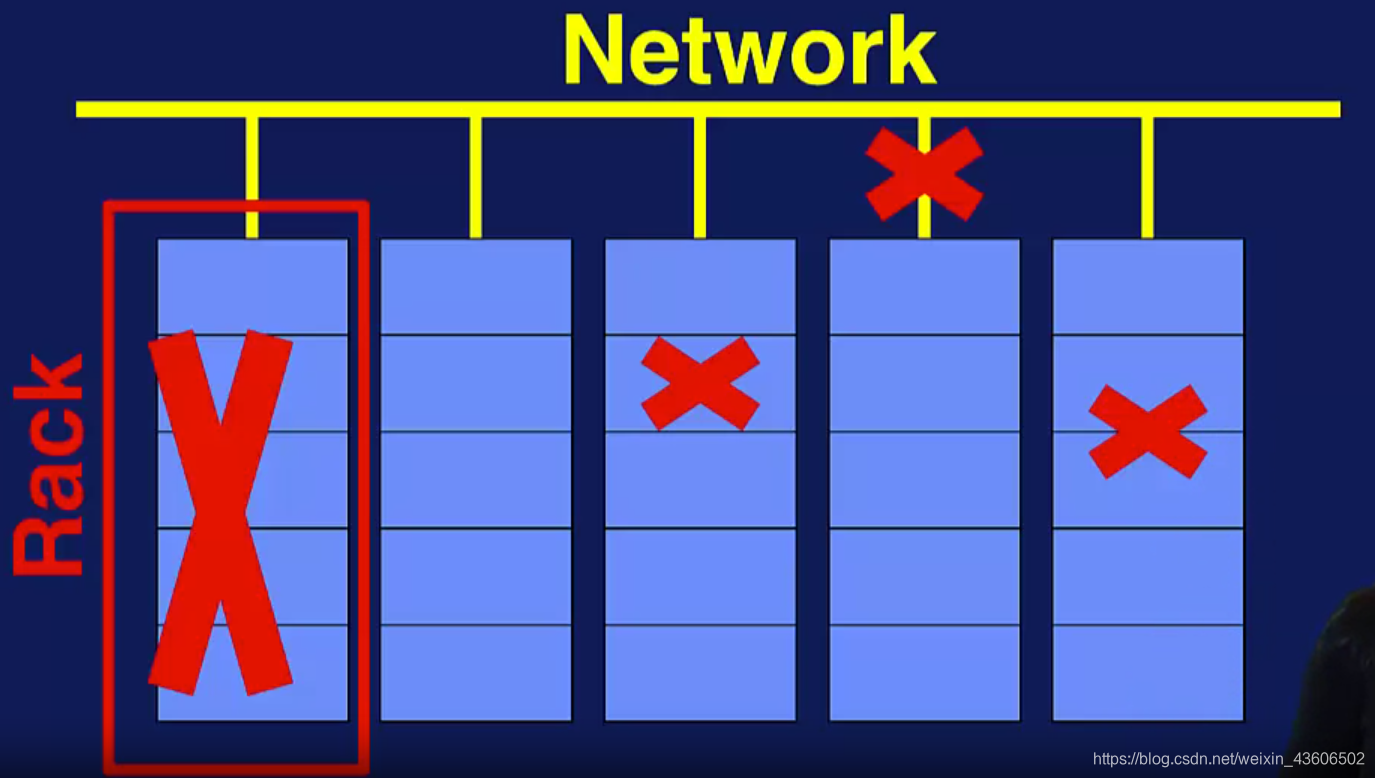
- redundant data storage(冗余数据存储机制)
- data-parallel job restart(数据并行工作重启机制):重新运行错误独立的并行任务
3. 总结
商用集群(commodity clusters )是一种划算却能实现大数据扩展并行的应用。它发生部分错误的可能性较高。正是这种分布式计算推动了大数据管理和分析向低成本、可靠和容错系统的转变。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









