







 本文探讨了半结构化数据模型的特性,对比了结构化、半结构化与非结构化数据的区别,详细分析了XML与JSON作为半结构化数据表示形式的优劣,并介绍了树状数据结构在半结构化数据中的应用。
本文探讨了半结构化数据模型的特性,对比了结构化、半结构化与非结构化数据的区别,详细分析了XML与JSON作为半结构化数据表示形式的优劣,并介绍了树状数据结构在半结构化数据中的应用。
文章目录
(写在前面:由于之前学习过数据库相关知识,这里不再赘述关于关系模型的相关知识)
半结构化数据模型(Semi-structured Data Model)
1. 几种数据模型
1. 结构化数据,简单来说就是数据库。也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理。结构化数据标记,是一种能让网站以更好的姿态展示在搜索结果当中的方式,搜索引擎都支持标准的结构化数据标记。
2. 半结构化数据是一种适于数据库集成的数据模型,也就是说,适于描述包含在两个或多个数据库(这些数据库含有不同模式的相似数据)中的数据。
- 和普通纯文本相比它具有一定的结构性,但和具有严格理论模型的关系数据库的数据相比更灵活。(最主要的)
- 它是一种标记服务的基础模型,用于Web上共享信息。
- 特别的,半结构化数据是“无模式”的。更准确地说,其数据是自描述的。它携带了关于其模式的信息,并且这样的模式可以随时间在单一数据库内任意改变。
这种灵活性可能使查询处理更加困难,但它给用户提供了显著地优势。例如,可以在半结构化模型中维护一个电影数据库,并且能如用户所愿地添加类似“我喜欢看此部电影吗?”这样的新属性。这些属性不需要所有电影都有值,或者甚至不需要多于一个电影有值。同样的,可以添加类似“homage to”这样的联系而不需要改变模式,或者甚至表示不止一对的电影间的联系。
因为我们要了解数据的细节,所以不能将数据简单地组织成一个文件按照非结构化数据处理,由于结构变化很大也不能够简单的建立一个表和他对应。
3. 非结构化数据:是与结构化数据相对的,不适于由数据库二维表来表现,包括所有格式的办公文档、XML、HTML、各类报表、图片和咅频、视频信息等。支持非结构化数据的数据库采用多值字段、了字段和变长字段机制进行数据项的创建和管理,广泛应用于全文检索和各种多媒体信息处理领域。
2. 半结构化模型特征
半结构化数据中结构模式附着相融于数据本身,数据自身就描述了其相应结构模式,具有下述特征:
-
数据结构自描述性。 结构与数据相交融,在研究和应用中不需要区分“元数据”和“一般数据”(两者合二为一)。
-
数据结构描述的复杂性。 结构难以纳入现有的各种描述框架,实际应用中不易进行清晰的理解与把握。
-
数据结构描述的动态性。 数据变化通常会导致结构模式变化,整体上具有动态得结构模式。
常规的数据模型例如E-R模型、关系模型和对象模型恰恰与上述特点相反,因此可以成为结构化数据模型。而相对于结构化数据,半结构化数据的构成更为复杂和不确定,从而也具有更高的灵活性,能够适应更为广泛的应用需求。
3. XML和JSON
- JSON(JavaScript Object Notation):是一种轻量级的数据交换模式
{ "people": [
{ "firstName": "Brett", "lastName":"McLaughlin", "email": "aaaa" },
{ "firstName": "Jason", "lastName":"Hunter", "email": "bbbb"},
{ "firstName": "Elliotte", "lastName":"Harold", "email": "cccc" }
]}
- XML(Extensible Markup Language) :可扩展的标记语言,它是SGML(标准通用标记语言)的一个子集
<?xml version="1.0" encoding="utf-8" standalone="no"?>
<students>
<student number="1001">
<name>zhangSan</name>
<age>23</age>
<sex>male</sex>
</student>
<student number="1002">
<name>liSi</name>
<age>32</age>
<sex>female</sex>
</student>
<student number="1003">
<name>wangWu</name>
<age>55</age>
<sex>male</sex>
</student>
</students>
*拓展:html和XML有什么区别?
| html | xml | |
|---|---|---|
| 设计目标 | 显示数据,如何更好地显示数据,焦点是数据外观 | 描述数据,什么是数据,如何存放数据,焦点是数据的内容 |
| 语法 | 要求标记的嵌套、配对等; 不区分大小写 引号是可用可不用的; 可以拥有不带值的属性名; 过滤掉空格; | 严格要求嵌套、配对,并遵循DTD的树形结构; 区分大小写; 属性值必须分装在引号中; 所有的属性都必须带有相应的值; 空白部分不会被解析器自动删除; xml比html 语法要求更严格 |
| 数据和显示的关系 | 内容描述与显示方式整合为一体 | 内容描述与显示方式分离 |
| 标签 | 预定义 | 免费、自定义、可扩展 |
| 可读性以及可维护性 | 难于阅读、维护 | 结构清晰、便于阅读、维护 |
| 结构描述 | 不支持深层的结构描述 | 文件结构嵌套可以复杂到任何程度 |
| 与数据库的关系 | 没有直接联系 | 与关系型和层状数据库均可对应和转换 |
| 超链接 | 单文件、书签链接 | 可以定义双向链接、多目标链接、扩展链接 |
xml不是要来取代html的,是对html的补充,用来与html协同工作的语言,基于上面这些优势,xml将来成为所有的数据处理和数据传输的常用工具非常可观。
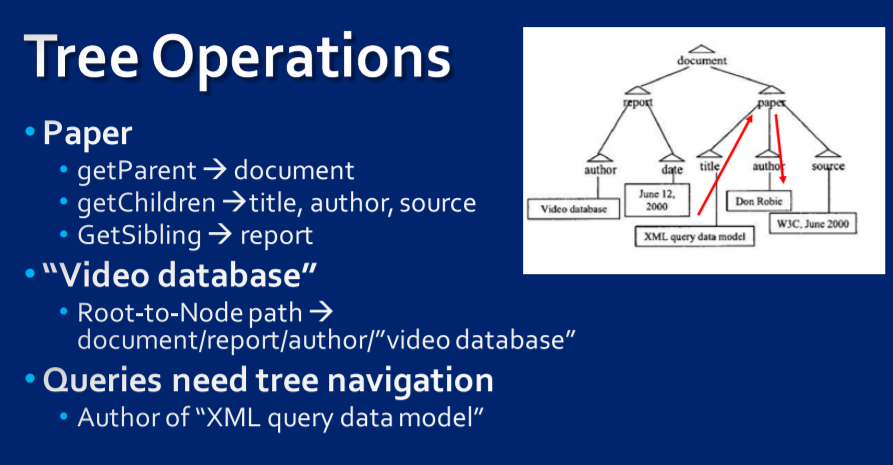
4. 树状数据结构(Tree Data Structure)
xml TREE Wikipedia:xml TREE

















 4433
4433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









