







目录
一、反转一个单链表
示例:
输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL
题解:
方法一:迭代
假设存在链表 1→2→3→∅,我们想要把它改成∅←1←2←3。
在遍历列表时,将当前节点的next 指针改为指向前一个元素。由于节点没有引用其上一个节点,因此必须事先存储其前一个元素。在更改引用之前,还需要另一个指针来存储下一个节点。不要忘记在最后返回新的头引用!
/**
struct LinkNode {
int m_iData{0};
LinkNode* m_pNext{ nullptr };
};
*/
LinkNode* reverseNode(LinkNode* pRoot)
{
if (nullptr == pRoot || nullptr == pRoot->m_pNext)
{
return pRoot;
}
LinkNode* pHead = pRoot;
LinkNode* pPre = nullptr;
while (nullptr != pHead) {
LinkNode* pTmp = pHead->m_pNext;
pHead->m_pNext = pPre;
pPre = pHead;
pHead = pTmp;
}
return pPre;
}复杂度分析
- 时间复杂度:O(n),假设 n 是列表的长度,时间复杂度是 O(n)。
- 空间复杂度:O(1)。
方法二:递归

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
if(nullptr == head || nullptr == head->next)
{
return head; //这是原链表最后一个节点
}
ListNode * pHead = reverseList(head->next); //这个节点就是翻转链表以后的头结点
head->next->next = head; //利用当前节点找到翻转链表的尾结点,pTail = head->next;
head->next = nullptr; //当前节点成了尾节点以后置空,否则链表中可能会产生循环
return pHead; //返回头结点
}
};复杂度分析
时间复杂度:O(n),假设 n是列表的长度,那么时间复杂度为 O(n)。
空间复杂度:O(n),由于使用递归,将会使用隐式栈空间。递归深度可能会达到 n 层。
二、给定一个链表,判断链表中是否有环
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
如果链表中存在环,则返回 true 。 否则,返回 false 。
进阶:
你能用 O(1)(即,常量)内存解决此问题吗?
示例 1:
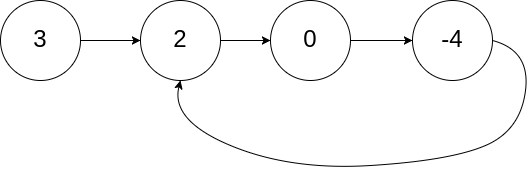
输入:head = [3,2,0,-4], pos = 1 输出:true 解释:链表中有一个环,其尾部连接到第二个节点
方法一:哈希表
思路及算法
最容易想到的方法是遍历所有节点,每次遍历到一个节点时,判断该节点此前是否被访问过。
具体地,我们可以使用哈希表来存储所有已经访问过的节点。每次我们到达一个节点,如果该节点已经存在于哈希表中,则说明该链表是环形链表,否则就将该节点加入哈希表中。重复这一过程,直到我们遍历完整个链表即可。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
bool hasCycle(ListNode *head) {
unordered_set<ListNode*> setNode;
while(head)
{
if(setNode.count(head))
return true;
setNode.insert(head);
head = head->next;
}
return false;
}
};复杂度分析
时间复杂度:O(N),其中 N 是链表中的节点数。最坏情况下我们需要遍历每个节点一次。
空间复杂度:O(N)O,其中 NN是链表中的节点数。主要为哈希表的开销,最坏情况下我们需要将每个节点插入到哈希表中一次。
方法二:快慢指针
思路及算法
本方法需要读者对「Floyd 判圈算法」(又称龟兔赛跑算法)有所了解。
假想「乌龟」和「兔子」在链表上移动,「兔子」跑得快,「乌龟」跑得慢。当「乌龟」和「兔子」从链表上的同一个节点开始移动时,如果该链表中没有环,那么「兔子」将一直处于「乌龟」的前方;如果该链表中有环,那么「兔子」会先于「乌龟」进入环,并且一直在环内移动。等到「乌龟」进入环时,由于「兔子」的速度快,它一定会在某个时刻与乌龟相遇,即套了「乌龟」若干圈。
我们可以根据上述思路来解决本题。具体地,我们定义两个指针,一快一满。慢指针每次只移动一步,而快指针每次移动两步。初始时,慢指针在位置 head,而快指针在位置 head.next。这样一来,如果在移动的过程中,快指针反过来追上慢指针,就说明该链表为环形链表。否则快指针将到达链表尾部,该链表不为环形链表。

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
bool hasCycle(ListNode *head) {
//三个节点才可能构成环
if(nullptr == head || nullptr == head->next)
{
return false;
}
ListNode* pSlow = head; //下面直接while循环,因此慢指针在后,快指针在前
ListNode* pFast = head->next;
while(pFast != pSlow)
{
if(nullptr == pFast || nullptr == pFast->next) //每次都要判空
{
return false;
}
pSlow = pSlow->next;
pFast = pFast->next->next;
}
return true;
}
};复杂度分析
时间复杂度:O(N),其中 N 是链表中的节点数。
当链表中不存在环时,快指针将先于慢指针到达链表尾部,链表中每个节点至多被访问两次。
当链表中存在环时,每一轮移动后,快慢指针的距离将减小一。而初始距离为环的长度,因此至多移动 N 轮。
空间复杂度:O(1)。我们只使用了两个指针的额外空间。
三、合并两个有序链表
将两个有序链表合并为一个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例:
输入:1->2->4, 1->3->4
输出:1->1->2->3->4->4
思路:依次比较两个链表中的数大小然后添加链表即可.技巧是可以先创建一个头结点,然后返回这个头结点的next,这样就比较容易实现

struct LinkNode {
int m_iData{ 0 };
LinkNode* m_pNext{ nullptr };
};
/*
Merge(H1,H2) = Min(H1,H2) + Merge(Hmin+1,Hmax);
H1 == NULL or H2 == NULL
@brief:
选出两个链表头结点中较小的一个节点:Min(H1,H2),最后返回这个节点
头较小链表指针加 1
递归合并两个链表
终止条件就是其中一个链表为空
*/
LinkNode* Merge(LinkNode* pHead1,LinkNode* pHead2)
{
if (nullptr == pHead1)
{
return pHead2;
}
else if (nullptr == pHead2)
{
return pHead1;
}
LinkNode* pMerge = nullptr;
if (pHead1->m_iData < pHead2->m_iData)
{
pMerge = pHead1;
pHead1->m_pNext = Merge(pHead1->m_pNext,pHead2);
}
else
{
pMerge = pHead2;
pHead2->m_pNext = Merge(pHead1, pHead2->m_pNext);
}
return pMerge;
}















 241
241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









